Ably provides an edge messaging service to deliver data at low latency and power live and collaborative applications on millions of simultaneously connected devices. Our platform runs tens of millions of concurrent, long-running WebSocket and HTTP streaming connections and reaches more than 300 million devices across 80 countries each month. Ably is on track to power realtime digital experiences for one billion devices per month by 2024.
Our customers are wide-ranging, and use cases include platforms for participative online events, collaborative working, and realtime sports data distribution. For example, Ably powers the live score updates and commentary for Tennis Australia. The Australian Open is one of the four major tennis tournaments in the global sports calendar and has a global fan base of over 1.2 million users. Many fans monitor matches from their smartphones and Ably processes billions of messages during live play.
Elasticity is a crucial requirement: the load on Ably’s system is unpredictable and can typically change by an order of magnitude every day, or more than that for events with large audiences. Application developers such as Hubspot and Bet Genius look to Ably for reliable realtime services to avoid issues with availability during surges. We, in turn, rely on our cloud provider, AWS, for a bullet-proof infrastructure.
| Related content | First down or just down? Is your realtime infrastructure the real MVP?
How Ably uses AWS
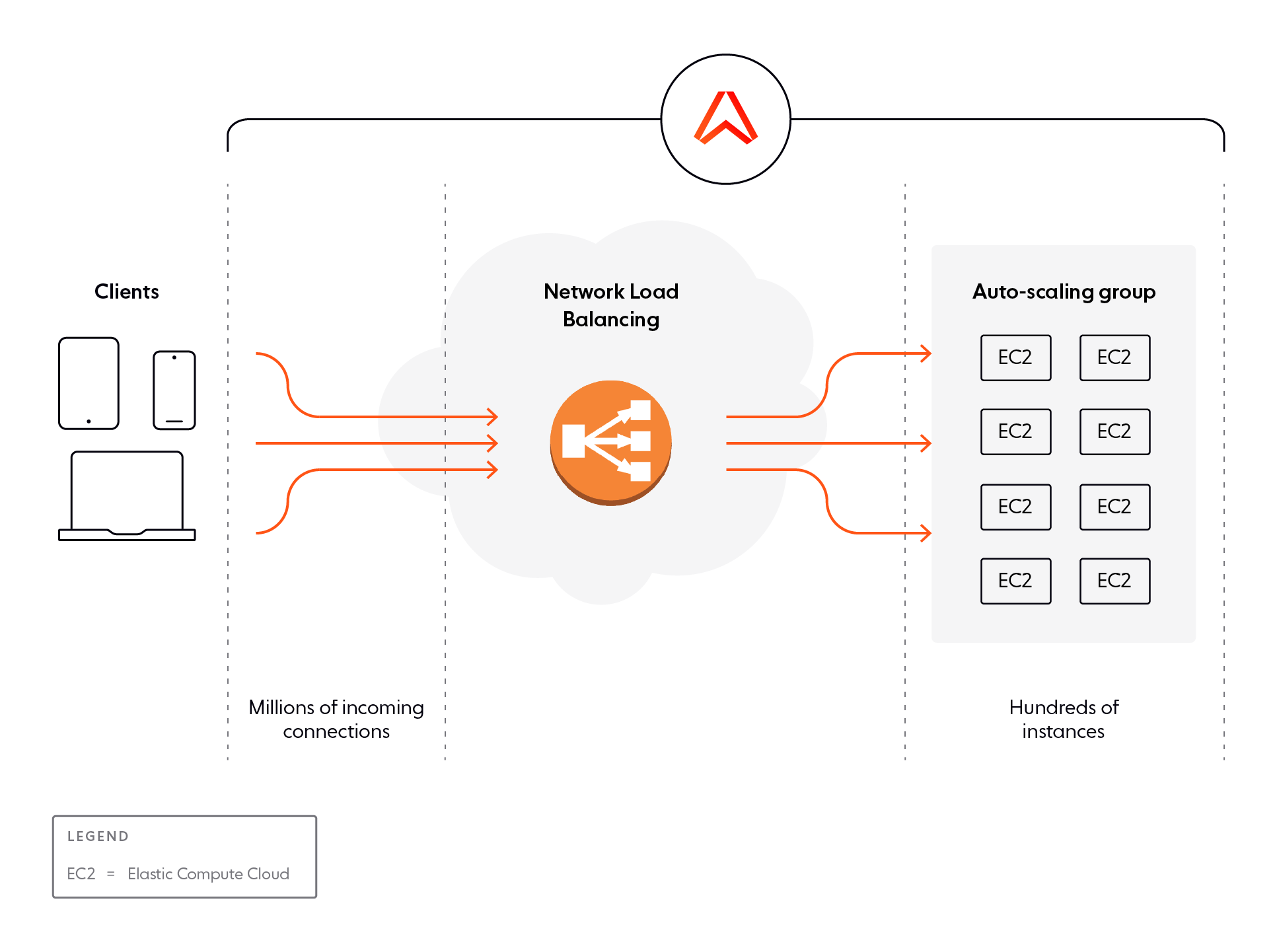
Ably is hosted on AWS EC2 infrastructure and uses its associated services. A cluster typically exists in multiple regions for availability reasons and spans between two and ten regions.
The primary functionality of the system is deployed in two principal roles:
- Frontend instances: these processes handle REST requests and realtime connections (Comet and WebSocket);
- Core instances: these processes perform all central message processing for channels.
We scale in each region according to load. We monitor CPU, memory, and other metrics on each instance and trigger autoscaling by aggregate metrics derived from those parameters.
Ably’s workloads are characterized by high connection counts and high rates of new connections. Traffic on individual connections ranges from low (single-digit messages per minute) up to hundreds of messages per second. Typical message sizes range from a few bytes to several kilobytes.
As clients connect, their connections are distributed by one or more network load balancers so that they can be terminated by a set of frontend compute instances.
Each load balancer exposes a single network endpoint externally and forwards individual requests to frontend server instances managed in a pool that can scale to match the request load.
| Related content | Using the Ably platform at scale
Ably’s adoption of Graviton2
In late 2021, we ran a series of load-testing experiments to compare Ably’s performance on two scenarios: Graviton2 (m6g.large) and our current baseline Intel (m5.large). Our goal was to confirm there were no regressions or issues experienced on Graviton2.
We tested by scaling up the number of users, each publishing on a unique channel, to 300K at the rate of 50 users/second, with each user publishing on their channel every 10 seconds. We chose this as it represents a typical scenario for the applications our customers deploy. Once all 300K users had spawned, we observed the number of EC2 instances the cluster had scaled to: for Graviton2 and for the baseline.
Our observations were promising: the instance counts were similar, and the performance of the Graviton2 scenario appeared to be better. So, early in 2022, we started running Graviton2 instances in non-production environments for several weeks with no issues. We then started rolling Graviton2 out to production environments on January 20th. Our deployment mechanism means that instances are terminated and recreated, so it was a matter of updating launch templates attached to auto scaling groups (ASG) and then waiting for the instances to be recreated.
We started in a single region in a single cluster and left it to run for a few days with real user traffic before continuing the process elsewhere. We observed performance to ensure there was no degradation. As confidence grew in the architecture, we increased our rate of adoption.
We have now migrated 100% of our core systems to Graviton2 instances in all production clusters (we hit this milestone on February 10th, 2022).
As part of this rollout, we also included running multiple launch templates in an ASG: if an instance type is unavailable, the ASG will automatically use a different one. This ensures that the Ably service is not interrupted if we try to provision more capacity than AWS may have in a region.
Observations
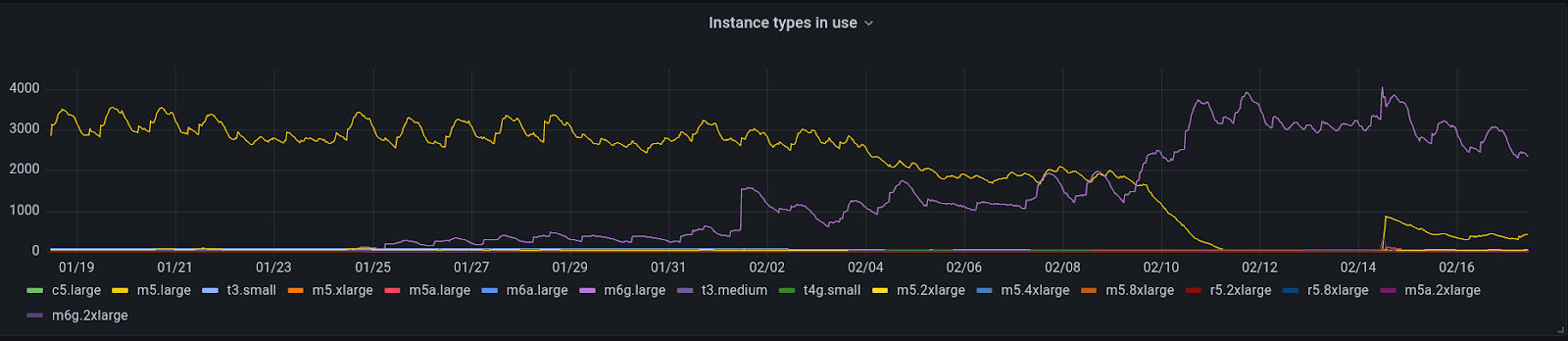
The following graph shows Ably’s adoption rate. Note the drop on February 14th, which is due to rolling back a cluster during an incident unrelated to the Graviton2 migration.
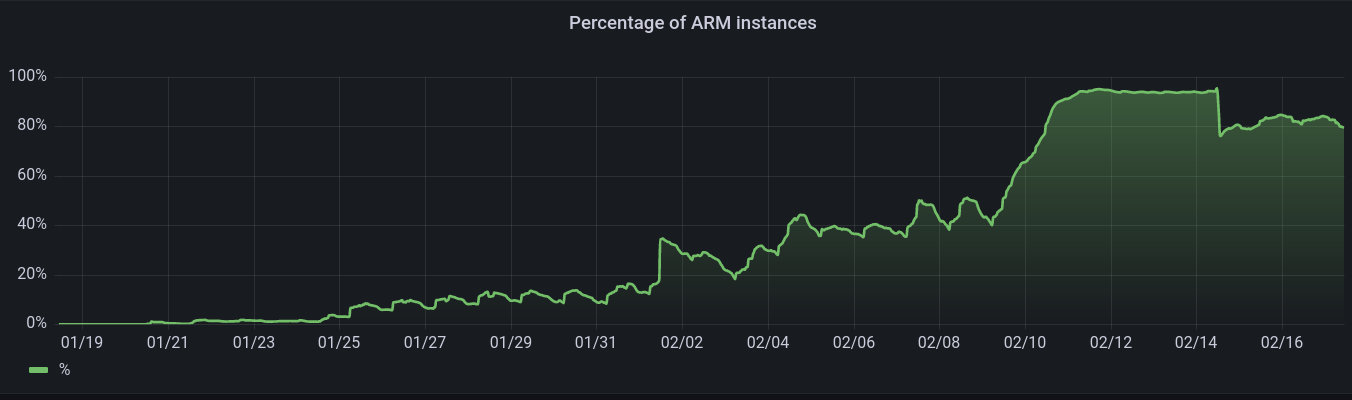
Number of hosts by architecture:
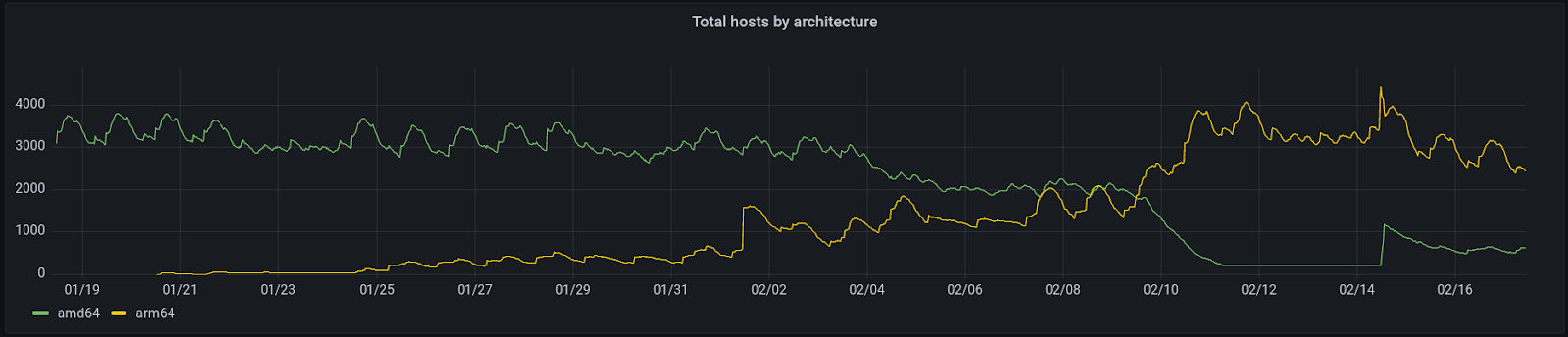
Instance types in use:
Benefits of Graviton2
Ably is always looking for ways to innovate and add value, for example, reduce costs, improve performance, or both. The migration to use Graviton2 has lowered our overhead costs as the m6g.large costs are lower than the corresponding Intel instances. Arm-based hardware also has a positive environmental impact because it typically consumes less power and generates less heat.
Our incremental migration to Graviton2 has long-term benefits for Ably, for our existing customers, and ultimately for future projects that depend on unbreakable realtime performance at scale.
Every day, Ably delivers billions of realtime messages to millions of users for thousands of companies. Our platform is mathematically modeled around Four Pillars of Dependability, so we’re able to ensure messages don’t get lost while still being delivered at low latency over a secure, reliable, and highly available global edge network.
Try our APIs and discover how easy we make the move to event-driven, or get in touch to learn more about us.

More from Ably Engineering
- Stretching a point: the economics of elastic infrastructure
- Redis scripts do not expire keys atomically
- Channel global decoupling for region discovery
- Save your engineers' sleep: best practices for on-call processes
- No, we don't use Kubernetes
- Key choices in AWS network design: VPC peering vs Transit Gateway and beyond