There is increasing demand for realtime data delivery as users expect faster experiences and instantaneous transactions. This means not only is lower latency required per message, but providers must also handle far greater capacity in a more globally-distributed way.
When building realtime applications, the right tools for the job address these requirements at scale. WebSocket has become the dominant protocol for realtime web applications, and has widespread browser support. It offers a persistent, fully-duplexed connection to achieve low latency requirements. Publish/Subscribe (pub/sub) has been around even longer, and enables providers to scale data transmission systems dynamically, something that is crucial in providing these new capacity needs. While Pub/Sub itself is just an architectural pattern, tools like Redis have built out pub/sub functionality to make it easier to develop and deploy a scalable pub/sub system.
This article details how to build a simple pub/sub service with these components (WebSockets and Redis). It also discusses the particular technical challenges of ensuring a smooth realtime service at scale, the architectural and maintenance considerations needed to keep it running, and how a realtime service provider could simplify these problems and your code.
First, let’s briefly define the fundamental components at play.
What is pub/sub?
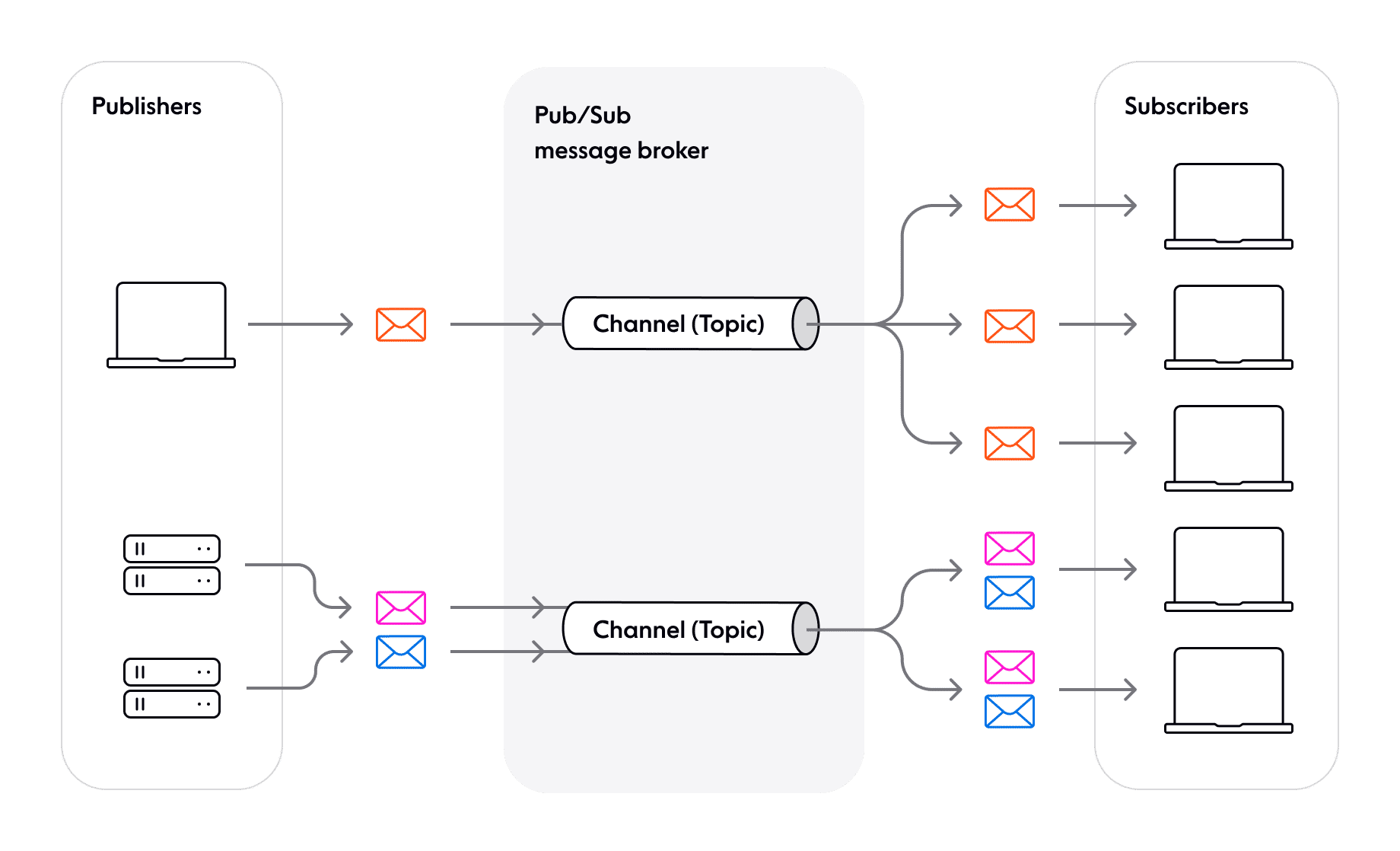
The core of pub/sub is messaging. Messages are discrete packets of data sent between systems. On top of this, channels (or topics) allows you to apply filtering semantics to messages; publishers (clients that create messages); and subscribers (clients that consume messages). A client can publish and consume messages from the same channel or many channels.
Because of this, pub/sub can be used to support a number of different patterns:
- One-to-one: Two clients that both need to subscribe and publish messages to the same channel. This is common in support chat use cases.
- One-to-many: Many clients may receive information from a centralized source, as with dashboard notifications.
- Many-to-one: Many clients publish messages to one channel; for example, in a centralized logging system, all logs of a certain tag are routed to one repository.
- Many-to-many: Multiple clients send messages to all in the members of the group - Such as a group chat or presence feature.
The pub/sub pattern allows clients to send and receive messages directly, without a direct connection to recipients with a message broker. It promotes an async and decoupled design, which lends itself to building scalable, distributed systems that can handle concurrent traffic for millions of connected clients. However, in practice, building a pub/sub system like this requires a reliable and performant data store.
What is Redis?
Redis is a highly performant in-memory key-value store, though it can also persist data to non-volatile storage (disk). It is capable of processing millions of operations per second, so makes it ideal for systems with high throughput. Its feature set includes pub/sub, allowing clients to publish to a channel which is then broadcast out to all subscribers of that channel in realtime.
What are WebSockets?
WebSockets are a protocol for bidirectional communication, and are a great choice where low latency and persistent connectivity are required. In contrast to something like HTTP long polling, which repeatedly queries the server for updates, WebSockets make a continuous connection between the client and server, so that messages flow in both directions as and when they occur. Because of this, WebsSockets can be ideal for applications like chat systems, live notifications, or collaborative tools. Having a persistent connection removes the need to poll a server for updates, this in turn reduces latency, a key metric in realtime applications.
They are commonly used for communication between some web client (browser) and some backend server. The persistent connection is formed over TCP.
A tutorial: A simple pub/sub service
Now, let’s see how a simple realtime pub/sub service comes together with Redis and WebSockets, where multiple clients can subscribe to a channel and receive channel messages.
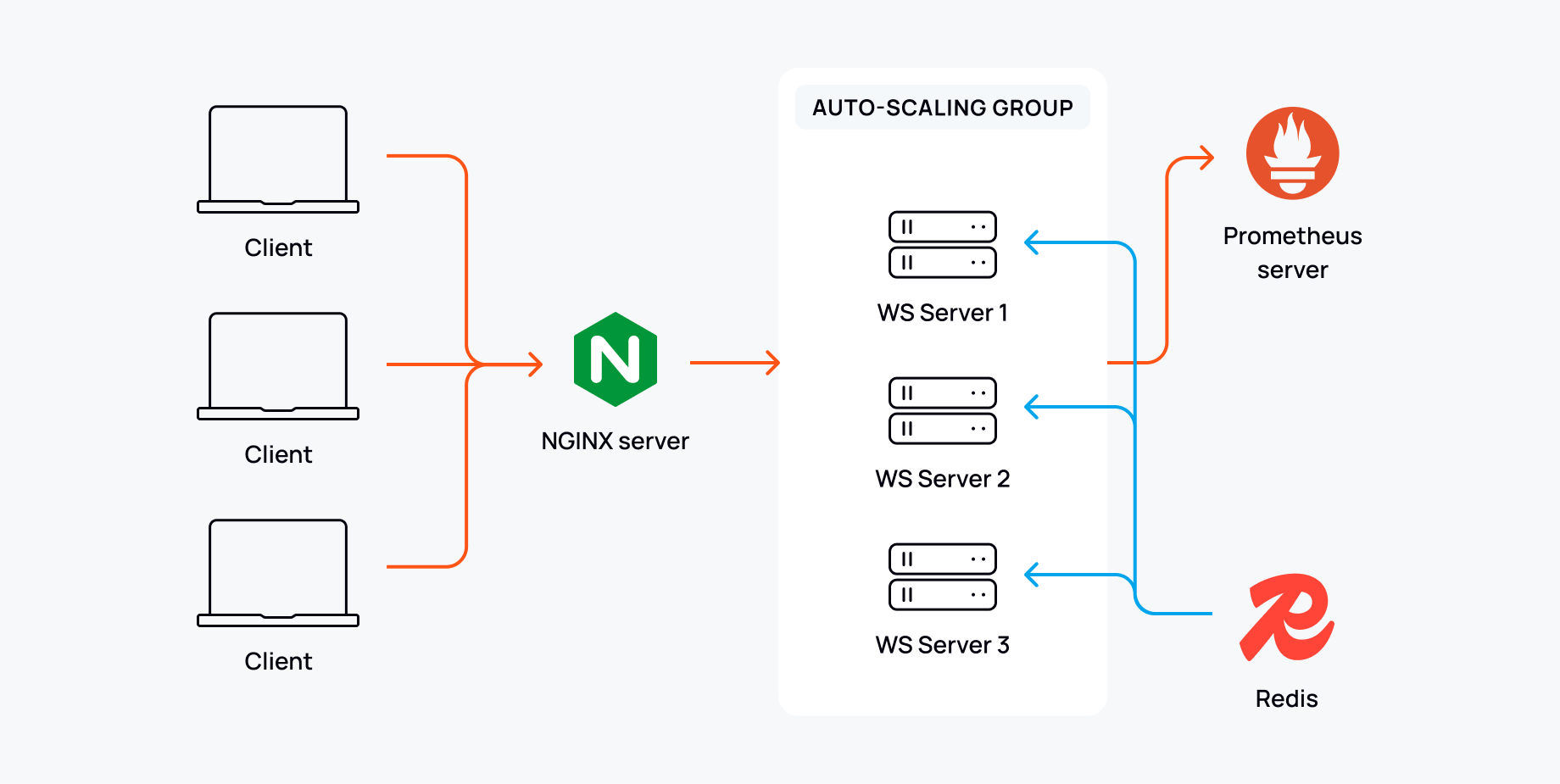
A typical architecture consists of a WebSocket server for handling client connections, backed by Redis as the Pub/Sub layer for distributing new messages. A load balancer like NGINX, or AWS ALB is used to handle incoming WebSocket connections and route them across multiple server instances; this is key to distributing load on our service.
Autoscaling can be used to dynamically adjust our servers to match demand, maintaining performance while reducing cost during quiet periods. To do this, we would need our WebSocket servers to remain stateless.
Breakdown of components
- WebSocket server - Clients connect to this server to receive updates from a channel. The server subscribes to Redis channels and forwards messages it receives through the pub/sub subscription. We can build this with something like Gorilla-WebSocket or Express-ws.
- Redis as a pub/sub layer - The distribution service between publishers (backend services) and subscribers (our WebSocket servers). For simplicity, we will run a single instance of Redis. In production this will likely need to be clustered to avoid becoming a bottleneck.
- Load balancer (NGINX) - Distributes incoming WebSocket connections across multiple WebSocket server instances. It could do this naively in a round-robin fashion, or use some other method like IP hashing, though care should be taken to avoid creating hotspots.
- Autoscaler - It’s highly likely we will experience changing traffic, so an autoscaler will adjust our WebSocket servers according to available resources. We can implement this with Kubernetes, which can monitor metrics and respond accordingly.
- Monitoring and logging - Monitoring tools like Prometheus and Grafana track system performance, latency, and message delivery success rates. This will allow us to see how our system is operating and catch any errors that occur. It’s a good idea to configure some alerting on these metrics too.
We will write the server in TypeScript (TS) using Node as our runtime environment. We won’t cover setup and usage of auto scaling, but more information on this topic can be found here.
1. Set up NGINX
Install NGINX and get it running. On Mac or Linux operating systems, we could do this with a package manager like brew.
brew install nginx && brew services start nginxWe also need to configure it to route connections, forward requests to the server, and ensure NGINX handles the WebSocket requests correctly, something like this:
# Define the upstream WebSocket server
upstream websocket_backend {
server 127.0.0.1:8080; # Your WebSocket server address
}
location /ws {
# Proxy WebSocket traffic to the backend
proxy_pass http://websocket_backend;
# Required for WebSocket
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
# Pass the original Host header
proxy_set_header Host $host;
# Timeouts for WebSocket
proxy_read_timeout 300s;
proxy_send_timeout 300s;
}
2. Set up Redis
Install Redis and get it running.
brew install redis && brew services start redisWe should now have a local instance available at localhost. Note: this creates an instance of Redis with no authentication, and is not an advisable setup for production.
3. Set up the server
Now, we will need to write the server code to handle client requests, integrate with our Redis instance, and allow WebSocket connections. TypeScript has a vast range of packages that we can use, such as WS, which provides WebSocket client and server capabilities. WS implements the WebSocket protocol and abstracts away a lot of the details like handshakes, framing and connection management, so we get a nice high-level API.
import WebSocket, { WebSocketServer } from 'ws';
We will also need the ioredis package, which provides a fully-featured client to manage our connections to Redis.
import Redis from 'ioredis';
Let’s create a basic application that will do the following;
- Accept client requests and upgrade them to WebSockets
- Provide simple handling of the WebSocket and Channel lifecycle
- Store the new connections so we can send messages as needed
- Connect to Redis and subscribe to a specified channel
- When a new message is received on the channel, iterate through all subscribed clients and send the message along.
- Remove unused redis connections
This looks like:
// Maps to track channel subscriptions
const redisClients: Map<string, Redis> = new Map(); // Redis client per channel
// Maps to track WebSocket connections
const channelSubscribers: Map<string, Set<WebSocket>> = new Map(); // WebSocket clients per channel
// WebSocket Server
const wss = new WebSocketServer({ port: 3000 });
console.log('WebSocket server is listening on ws://localhost:3000');
wss.on('connection', (ws: WebSocket) => {
console.log('New WebSocket connection established');
ws.on('message', (message: string) => {
try {
const data = JSON.parse(message);
// Validate the message format
if (data.action === 'subscribe' && typeof data.channel === 'string') {
const channel = data.channel;
// Ensure a Redis client exists for this channel
if (!redisClients.has(channel)) {
const redisClient = new Redis();
redisClients.set(channel, redisClient);
// Attempt to subscribe to the Redis channel
redisClient.subscribe(channel, (err) => {
if (err) {
console.error(`Failed to subscribe to Redis channel ${channel}:`, err);
ws.send(JSON.stringify({ error: `Failed to subscribe to channel ${channel}` }));
} else {
console.log(`Subscribed to Redis channel: ${channel}`);
}
});
// Handle incoming messages from the Redis channel
redisClient.on('message', (chan, message) => {
if (channelSubscribers.has(chan)) {
channelSubscribers.get(chan)?.forEach((client) => {
if (client.readyState === WebSocket.OPEN) {
client.send(JSON.stringify({ channel: chan, message }));
}
});
}
});
}
// Add this WebSocket client to the channel's subscribers
if (!channelSubscribers.has(channel)) {
channelSubscribers.set(channel, new Set());
}
channelSubscribers.get(channel)?.add(ws);
console.log(`WebSocket subscribed to channel: ${channel}`);
} else {
ws.send(JSON.stringify({ error: 'Invalid action or channel name' }));
}
} catch (err) {
console.error('Error processing WebSocket message:', err);
ws.send(JSON.stringify({ error: 'Invalid message format' }));
}
});
ws.on('close', () => {
console.log('WebSocket connection closed');
// Remove this WebSocket from all subscribed channels
channelSubscribers.forEach((subscribers, channel) => {
subscribers.delete(ws);
// If no more subscribers for the channel, clean up Redis client
if (subscribers.size === 0) {
redisClients.get(channel)?.quit();
redisClients.delete(channel);
channelSubscribers.delete(channel);
console.log(`No more subscribers; unsubscribed and cleaned up Redis client for channel: ${channel}`);
}
});
});
ws.on('error', (err) => {
console.error('WebSocket error:', err);
});
});
}
4. Send some messages
Produce some messages on the channel so that the server can begin sending the data on to connected clients. Here, as an example, we'll query for telemetry data of the International Space Station (ISS) each second, then publish this to our channel.
import axios from 'axios';
import Redis from 'ioredis';
const telemetryUrl = 'http://api.open-notify.org/iss-now.json';
const redisChannel = 'iss.telemetry'; // Redis channel name
const publishInterval = 1000; // Interval in milliseconds
// Create a Redis client
const redis = new Redis();
// Function to query URL and publish to Redis
async function queryAndPublish() {
try {
console.log(`Fetching data from ${telemetryUrl}...`);
// Query the URL
const response = await axios.get(telemetryUrl);
// Get the response payload
const payload = response.data;
// Publish the payload to the Redis channel
const payloadString = JSON.stringify(payload);
await redis.publish(redisChannel, payloadString);
console.log(`Published data to Redis channel "${redisChannel}":`, payloadString);
} catch (error) {
console.error('Error publishing data:', error);
} finally {
// Schedule the next query and publish task
setTimeout(queryAndPublish, publishInterval);
}
}
// Start the query and publish loop
queryAndPublish()
// Handle graceful shutdown
process.on('SIGINT', () => {
console.log('Shutting down...');
redis.disconnect();
process.exit();
});
5. Create the client
Construct a simple client that will point to our NGINX server and establish a WebSocket connection. It should begin receiving messages published to the channel. We have kept things simple here, but a production solution would need to handle things like heartbeats, retry mechanics, failover, authentication and more.
import WebSocket from 'ws';
const serverUrl = 'ws://localhost/ws';
const channelName = 'iss.telemetry';
// Create a new WebSocket connection
const ws = new WebSocket(serverUrl);
// Handle the connection open event
ws.on('open', () => {
console.log('Connected to WebSocket server');
// Send a subscription request for the specified channel
const subscriptionMessage = JSON.stringify({ action: 'subscribe', channel: channelName });
ws.send(subscriptionMessage);
console.log(`Subscribed to channel: ${channelName}`);
});
// Handle incoming messages
ws.on('message', (message) => {
console.log(`Message received on channel ${channelName}:`, message.toString());
});
// Handle connection close event
ws.on('close', () => {
console.log('WebSocket connection closed');
});
// Handle errors
ws.on('error', (error) => {
console.error('WebSocket error:', error);
});
After starting up the server, publisher, and client, we should see data being printed out to the standard output (stdout).
Challenges of a Redis + WebSockets build at scale
The code we’ve written is a basic implementation, but at scale in production, we will have to account for additional complexities. There are some issues with using Redis at scale, including:
Message persistence
In Redis pub/sub, messages are not persisted and are lost if no subscriber is listening (fire-and-forget). For some realtime use cases, like chat, this is likely not acceptable.
Horizontal scaling
A single instance of Redis is insufficient at scale, and as there is a limit to how far it can be vertically scaled, so a horizontally-scaled infrastructure is going to be your best option.
Redis can be deployed in a clustered mode for high availability and scalability. This essentially turns your single Redis instances into a network of interconnected redis nodes, then data can be distributed across these nodes. It allows for potentially much higher throughput and greater numbers of subscribers. Each node would take a portion of the data, this can be managed automatically, to distribute the workload (through sharding). But this comes with its own complexities, including:
- Needing active management to ensure even data distribution and cluster health - not specific to Redis, but general distributed systems issues, including:
- Failover mechanisms when a node goes down
- Manual node provisioning in case there are no replica sets
- Robust monitoring to catch network issues
- Increased networking overheads for cross-node communication
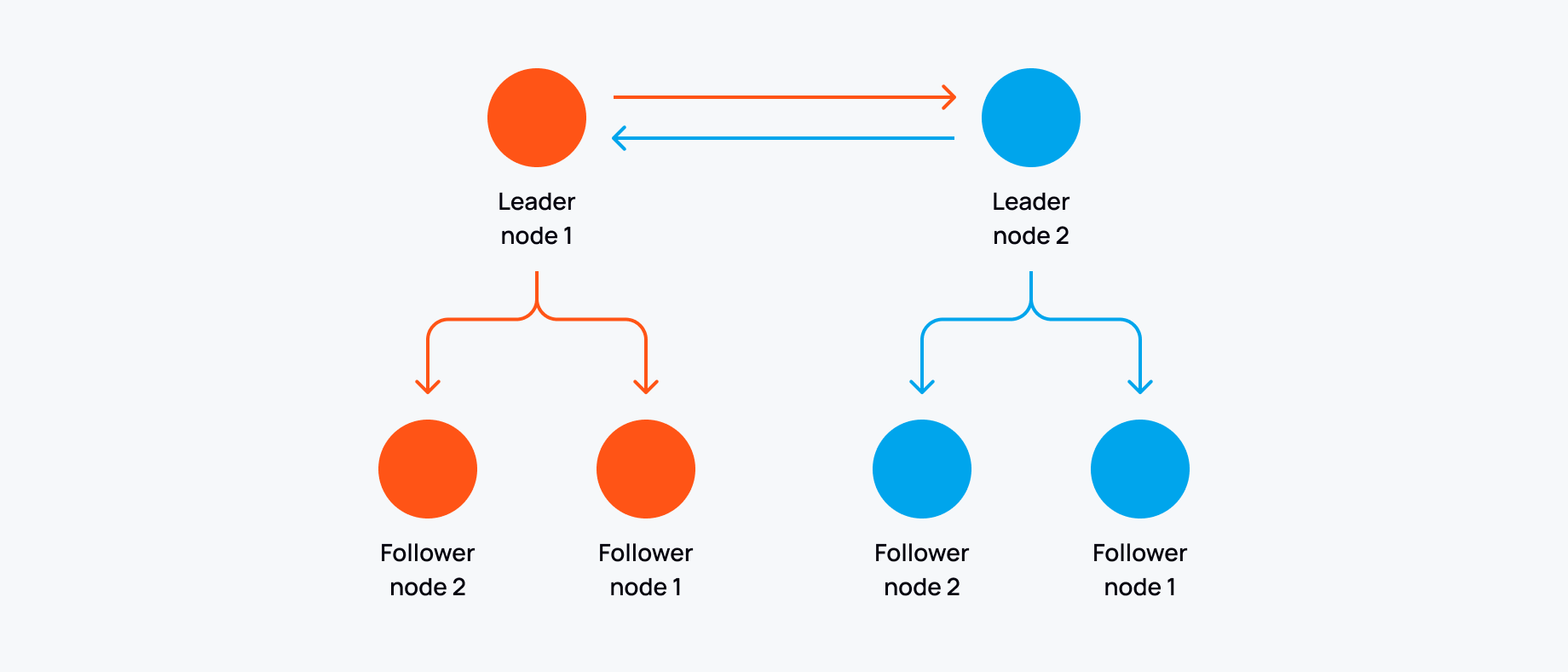
- Node discovery, leader election and split brain (where multiple leader/primary nodes become disconnected and we need to work out which nodes we will consider to still be active). Redis cluster uses a gossip protocol to share cluster state and quorum based voting for leader election and to help prevent split brain.
- There should be an odd number of nodes in a redis cluster setup, so if a network partition occurs, a quorum can still be reached.
- Lack of strong consistency guarantees - redis cluster prioritises throughput and works on eventual consistency, this means you can face data loss in some cases. You could use something like redisraft (experimental) that implements the RAFT consensus algorithm, but this writes to only a single leader at a time, creating a bottle neck for write-heavy workloads. (And RAFT does not account for byzantine failures, though these are rare in practice.)
Disaster recovery and geo distribution
For realtime use cases at scale, a globally-distributed system is non-negotiable. For example, what happens if our single datacenter fails? Or what if customers on the other side of the world require the lowest latency possible? Forcing a request between geographic regions would incur unacceptable latency penalties. Both problems would require us to geolocate our cluster in multiple regions.
A Redis cluster can be globally distributed - in the case of AWS, this would mean running in multiple availability zones. But this introduces more management and maintenance complexities on top of those we’ve already accumulated for horizontal scaling, like the need to ensure correct sharding, manage reconciliation of concurrent writes across regions, route traffic in the case of a net split, and rebalance to avoid hot nodes.
Challenges of WebSockets as a protocol
WebSockets on their own have potential issues to consider in the context of building out a realtime service:
Implementation
WebSocket libraries provide the foundations to build a WebSocket service, but they aren’t a solution we can use straight out of the box. For example, how do you handle routing requests when your server is becoming overloaded? What monitoring do you put in place? What scaling policies do you have in place, and what capacity do we have to deal with large traffic spikes? Home brewed implementations often fall short for large-scale, realtime apps, a gap that usually requires a huge amount of additional development to fill.
Authentication
WebSockets also complicate authentication, as they lack the standardized mechanisms found in HTTP protocols, like HTTP headers. Also, many client-side WebSocket libraries don’t provide much support for authentication, so developers have to implement custom solutions themselves. These gaps can complicate the process of securing WebSocket connections, so it’s paramount to select an approach here that gives a good balance of security with usability.
Basic Authentication, passing API keys as URL parameters, is a simple but insecure method and should not be used for client-side applications. A more secure and flexible alternative is Token-Based Authentication like JSON Web Tokens (JWT).
How do we manage these keys though, and how do we implement token revocation? How do we ensure a token is refreshed before a client loses access to resources?
Handling failover
WebSocket connections can encounter issues that often require fallback mechanisms. Secure ports like 443 are preferred for reliability and security, but fallback transports such as XHR polling or SockJS are needed for when networks have stricter restrictions. It’s likely we would need to implement this too if you’re looking to implement your own WebSocket solution.
Power consumption and optimization
WebSocket connections are persistent, so thought must be taken when considering devices like mobiles, as the drain on battery life must be well managed. Heartbeat mechanisms like Ping/Pong frames (aka heartbeats) can help maintain connection status but may increase power consumption. We could use push notifications, waking up apps without maintaining an active connection, but they don’t provide the same kind of reliability or ordering guarantees of WebSocket streams.
Handling discontinuity
In real-world applications, networks are rarely perfect, so how do we account for changing network conditions? Things like message history, stream resume, and backoff strategies are needed to maintain continuity of the channel. It could be that subscribe-only protocols like SSE are more appropriate, as they include built-in capabilities for resume without the bidirectional complexity of WebSockets.
A simpler way: dedicated services
As we can see, developing and maintaining WebSockets means managing complexities like authentication, reconnections, and fallback mechanisms if we want to provide a robust realtime experience.
The considerations needed across Redis and WebSockets for an at-scale realtime service need an entire team dedicated to them. If this sounds like a headache, that’s because it is! We should avoid doing this unless we absolutely have to - whole companies have been set up to solve these problems for us.
Ably provides a globally distributed pub/sub service, with high availability and a scalable system able to meet any demand while maintaining low latencies that are crucial for realtime experiences.
There is a way we can achieve the same results with Ably while alleviating all of the issues discussed in previous sections:
- WebSocket management - Ably provides pre-built WebSocket support in multiple SDKs, with SLAs that guarantee availability and reliability, and infrastructure currently handling over 1.4 billion connections daily.
- Connection reliability - Ably’s SDKs are designed to maintain consistent connectivity under all circumstances. They have automatic failover, selecting the best transport mechanism and ensuring connections remain stable even during network issues. If a temporary disconnection occurs, the SDKs automatically resume connections and retrieve any missed messages. Additionally, message persistence is supported through REST APIs, allowing retrieval of messages missed due to connection failures or extended offline periods.
- Scalability and capacity - Ably uses AWS load balancers to distribute WebSocket traffic efficiently across stateless servers, enabling limitless scaling to handle connections. With autoscaling policies in place, the infrastructure dynamically adjusts to meet changes in demand while maintaining a 50% capacity buffer to handle sudden spikes. Ably’s high-availability SLA guarantees 99.999% uptime, relying on redundant architecture and globally distributed routing centers.
- Global distribution - Ably operates core routing datacenters in seven regions, with data persistence across two availability zones per region. This setup ensures message survivability, achieving a 99.999999% guarantee by accounting for the probability of availability zone failures and enabling quick replication. Connections are routed to the closest datacenter to minimize latency, achieving a P99 latency of less than 50ms globally.
- Data distribution - Ably uses consistent hashing for channel processing, but also has dynamically scaling resources and will distribute the load as needed. This includes things like connection shedding.
- Operations and maintenance - Since Ably is a fully-managed service, it has dedicated monitoring, alerting and support engineers with expertise in operating a distributed system at scale.
- SDKs - 25+ SDKs for different environments.
In essence, Ably gives a comprehensive, managed Pub/Sub solution that handles the difficulties of building a distributed system with high availability, reliability, and survivability guarantees. This means developers can focus on their core application without the overhead of managing complex infrastructure like this.
Ably in practice: a code example
Let’s try using Ably’s ably-js SDK.
We can condense all of the code in the previous example into a few lines, for subscribing to our data channel:
import * as Ably from 'ably';
let client: Ably.Realtime;
async function subscribeClient() {
client = new Ably.Realtime('xxx.yyy');
const channel = client.channels.get('iss.data');
try {
await channel.subscribe((message) => {
console.log(`Received message: ${message.data}`);
});
} catch (error) {
console.error('Error subscribing:', error);
}
}
// Handler for SIGINT
function exitHandler() {
if (client) {
client.close();
console.log('The client connection with the Ably server is closed');
}
console.log('Process interrupted');
process.exit();
}
// Handle SIGINT event
process.on('SIGINT', exitHandler);
(async () => {
await subscribeClient();
})();
And publishing to our data channel:
import * as Ably from 'ably';
import axios from 'axios';
let client: Ably.Realtime;
async function publishData() {
client = new Ably.Realtime('xxx.yyy');
const channel = client.channels.get('iss.data');
try {
// Query the endpoint
const response = await axios.get('http://api.open-notify.org/iss-now.json');
// Get the response
const payload = response.data;
// Publish the payload to the Ably channel
const payloadString = JSON.stringify(payload);
await channel.publish({ data: payloadString });
} catch (error) {
console.error('Error publishing:', error);
}
}
// Handler for SIGINT
function exitHandler() {
if (client) {
client.close();
console.log('The client connection with the Ably server is closed');
}
console.log('Process interrupted');
process.exit();
}
// Handle SIGINT event
process.on('SIGINT', exitHandler);
(async () => {
await publishData();
})();
And in just a few lines of code, we have removed the need to handle the infrastructural complexities we mentioned earlier. If you’re interested in trying Ably, sign up for a free account today.