What is autoscaling?
The timeline of commercial computing can be roughly summarized as: buying computers → renting computers → renting partial computers (virtual servers) → renting partial computers for very short periods (cloud computing).
The model that you are used to if you joined the tech industry after, say, 2010, is that you can request a virtual machine (VM) at any time, it will be available almost instantly, can be disposed of equally quickly, and will be billed by the second only when it was actually around.
The idea many people had in this context is simple and obvious: don’t pay for capacity you’re not using. If your application sees significantly less use at certain times – say, an online retail business only active in a single country when it is the middle of the night in that country – then reduce the provisioned compute capacity for the application accordingly. Ideally, this would happen without human intervention, automatically.
Economics of public cloud
At a high level, running a business is a simple calculation: you provide a product or service, you incur certain costs in making that product or providing that service, and you try to charge your customers slightly more than that and call the difference your profit. (I assume my economics Nobel will be in the mail.)
For the discussion in the rest of this article, it will be useful to have a basic understanding of the inherent costs and pricing models of public cloud computing.
The cost of cloud
The basic cost factors for running a public cloud are:
- You need to buy a number of computers.
- You need somewhere to put these computers: a datacenter building, and the land that it is on.
- The computers are going to need electricity to run.
- You’re going to need high bandwidth internet connectivity.
- You need some staff to install, maintain, operate and secure the computers.
A few additional thoughts on these. Computers are mainly a capital expense, but one with a relatively short useful service life. So if you spend, say, $20k per machine and assume a five year service life, you can calculate with $4k/year for having one machine.
It may have occurred to you that I forgot cooling, but I just don’t think it matters much for this discussion. You can cool computers anywhere – if you happen to build in a place that is particularly bad for cooling, you will just use more electricity to run heat pumps. But overall, that’s a constant factor of at most 2 or 3× and doesn’t affect any of the following arguments. (If you’re actually good at running a public cloud, the factor could be as low as 1.02×, giving you a substantial profitability bump.)
For similar reasons, we can mostly ignore electricity use by the equipment itself. Modern machines do have power management and use less electricity when not being used at full capacity, but the difference between actual power draw and theoretical max power draw tends to be a fairly small and mostly constant factor. So you will end up with, it costs approximately $x/year to house, power, and cool one machine in this location, and add this to your cost for the machine itself existing.
At cloud provider scale, nobody is interested in selling you internet by the gigabyte: you’ll be paying a certain amount of money a year per gigabit/second of potential bandwidth that exists, whether you use it or not.
The interesting thing about staffing costs is that it is highly sublinear. As companies acquire more computers, they invest in better automation, so you will find that, when comparing a small corporate datacenter with a thousand machines and a public cloud datacenter with one hundred thousand machines, the cloud datacenter does not need 100× as many employees to maintain 100× as many machines.
There is an ongoing theme throughout this section, which I hope you’ve picked up on: as a cloud provider, your costs are dominated by cloud capacity existing and barely influenced by how much capacity you manage to sell. If your customers turn some of their machines off overnight, those machines are all still in the rack, burning money.
The price of cloud
The model users are most familiar with is on-demand pricing, also known as pay for what you use. For each cloud resource, a usage-based price is listed, for example on AWS, a 16-core Graviton2 virtual machine in Oregon is $0.616000 for each hour it exists. That seems cheap enough if you only need the VM for an hour, but if you do some basic math and figure out how much that is for a month, or a year, or over the five-year lifespan of a physical machine, you’ll find it’s actually really expensive. Why is that?
From the cloud provider’s point of view, they have the problem that when you’re not renting the machine, and even when nobody is renting the machine, it’s still there and they’re still incurring most of the cost of the machine existing. They need to adjust their pricing accordingly, so while the headline might be “You only pay for what you use”, the subtext is: “…at a rate that also pays for everything you’re not using, because we’re a business.”
Can they optimize their capacity planning so that at any point in time, very few machines are unused? Realistically, no; customers really hate it when they request a VM and are told there’s no capacity, so it’s necessary to run with very generous capacity reserves so that almost all requests fulfill instantly. If you market it as “on demand”, customers will have demands.
Additionally, physical capacity isn’t very elastic. If you decide “this site needs to go from 100,000 to 130,000 machines”, the new ones aren’t going to be up and running next week. The lead time is anywhere between several months (if you’re only buying computers) and a few years (if you need a whole new datacenter building).
Autoscaling does not solve this
If you model this as a game the cloud provider is playing against its customers, it’s clear there are no winners: if the customers get better at turning off their VMs, the provider will have to increase prices so that the remaining usage still pays for all the unused computers.
What can be done instead is to encourage customers to leave their VMs running and make longer term utilization trends more predictable. That’s why the major cloud providers offer very steep discounts for long-term use. 60 to 70 percent discounts off on-demand pricing are easily available, and with very large and very long term contracts, even 90% are possible.
Longer term load changes
Can autoscaling help with longer term load changes, such as business growth? If your business is growing at a very impressive pace, then next week’s daily peak will perhaps be 1% higher than this week’s. If you already have reactive autoscaling set up and working, this will of course be fine: it will automatically provision 1% extra capacity per week. However, every few months you will hit limits. This could be simple, the ASG reaches its configured max size, which you have to increase, or quite complicated, when the architecture of your application can no longer cope with the increased cluster size and you need to make deeper changes, such as vertically scaling your database servers in addition to horizontally scaling your frontends.
By comparison, if you’ve deployed without autoscaling, you will be fine day to day and week to week, because surely you’ve deployed with sufficient capacity reserves to handle a 1% or 5% increase in traffic. However, every few weeks or months you will get uncomfortably close to the limit, and you will have to either manually scale up or make deeper architecture changes.
Which is pretty much the same picture as with autoscaling. It doesn’t hurt, but it also doesn’t help much in this scenario. The operational benefit is debatable.

Autoscaling: its ancillary benefits
Here at Ably we use AWS, and we do use auto scaling groups (Amazon’s spelling) in production, so it would seem the analysis above suggesting the feature is pointless may not be the whole story. Let’s briefly consider how autoscaling works, and what it takes to get a service ready for autoscaling.
Sticking close to the AWS model (but other providers are similar), instead of creating one or several EC2 instances, you create an Auto Scaling Group. The name suggests you are encouraged to think of it as “a group of EC2 instances”. I find it more useful to think of it as a helper service in charge of creating and disposing of EC2 instances. The basic configuration for an ASG consists of a template for the kind of EC2 instances you want it to create, and a set of rules that describes when it should create or remove how many instances. These rules can range from the extremely simple (“I want 20 instances – no automatic changes”) to the simple (“when overall CPU utilization is above 70%, make another instance – if it is below 40%, remove one”) to the sophisticated (“try to keep the 95th percentile wait time for a free worker at or below 200ms”).
The second half of the picture is the software that is running on these EC2 instances. Even with the most advanced scaling algorithm, all the ASG will do is create, destroy, or replace instances. (Well, it can also register and unregister them in a load balancer for your convenience.) It’s your job to make sure that when an instance comes up, it starts doing something useful reasonably quickly, and that an instance going away doesn’t cause a service disruption that will annoy your users.
It’s fairly obvious that this only works for stateless services. You’re not going to be autoscaling your database. Some people will try anyway, of course, but my point is: if taking a node in or out of service implies a massive data transfer job to move on-disk state around, you’ll find it especially difficult to make autoscaling practically useful.
Getting your stateless services into this shape has a lot of advantages even if you don’t care about autoscaling at all. It forces you to have at least somewhat reliable service discovery and configuration management: if new instances are created without operator intervention, they need to become fully operational without requiring attention from an engineer. If you configure correct lifecycle rules and health checks for your group, failing instances will be automatically and quickly replaced with no operator intervention. Self-healing infrastructure – the holy grail of DevOps startups, included for free, and Amazon doesn’t even market these as Auto Healing Groups!
Software updates also become a lot more streamlined: with appropriate configuration, you only need to notify the group that a new version is ready and it will replace all old instances with new ones at a safe pace with no further operator intervention.
Even manual scaling of a service is a lot more fun when you can just change the targeted number of instances and the service will take care of the rest.
Load distribution at scale
Here at Ably, we provide a service where we do not control demand; our customers and their users decide how much of the service they use on any given day. Of course, there is statistical regularity to it as the graph below shows.
Our usage has a fairly pronounced day/night pattern: while our service is inherently global, our current customer base is biased towards North America and Western and Central Europe, so there is a window in each calendar day where our fleet size is about 20% smaller than it is at the daily peak.
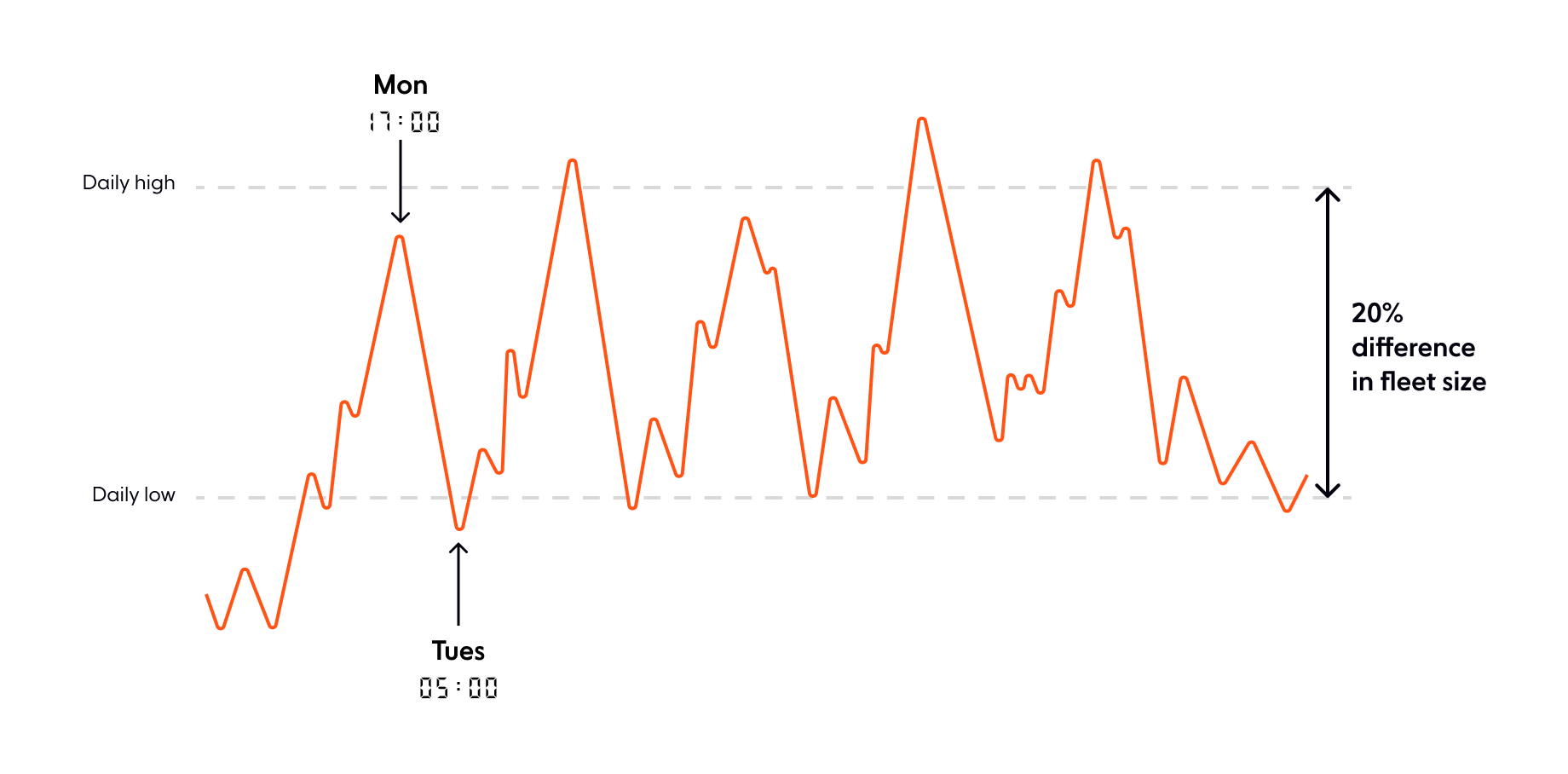
If we were starting from a point where we simply always have enough instances to handle the daily peak, and pay for them using on-demand rates, then turning on autoscaling could save us costs of at most 20%. (Actually less, because the cluster is 20% smaller for only part of each day.)
On the other hand, the minimum we would save by not scaling at all and just going on the simplest possible reserved capacity plan is about 30%! And that takes no engineering effort whatsoever, it’s a few clicks in the billing system.
However, it’s not quite that straightforward. At Ably, we see significant, unexpected surges. We have contracts that permit users to use the service, and we have to honor those by ensuring sufficient capacity is established in response to load.
| Related content: Engineering dependability and fault tolerance in a distributed system |
Unexpected load surges
Can autoscaling help with load changes that are neither daily ebb and flow nor long term trends?
At its most basic, it’s not particularly good at it. A simple autoscaling policy implies a sort of cone around your fleet size graph: if it creates one new instance every thirty seconds, that gives you a largest possible scaling movement of 120 additional instances per hour. If your usage spike breaks out of that range, autoscaling is not going to keep up.
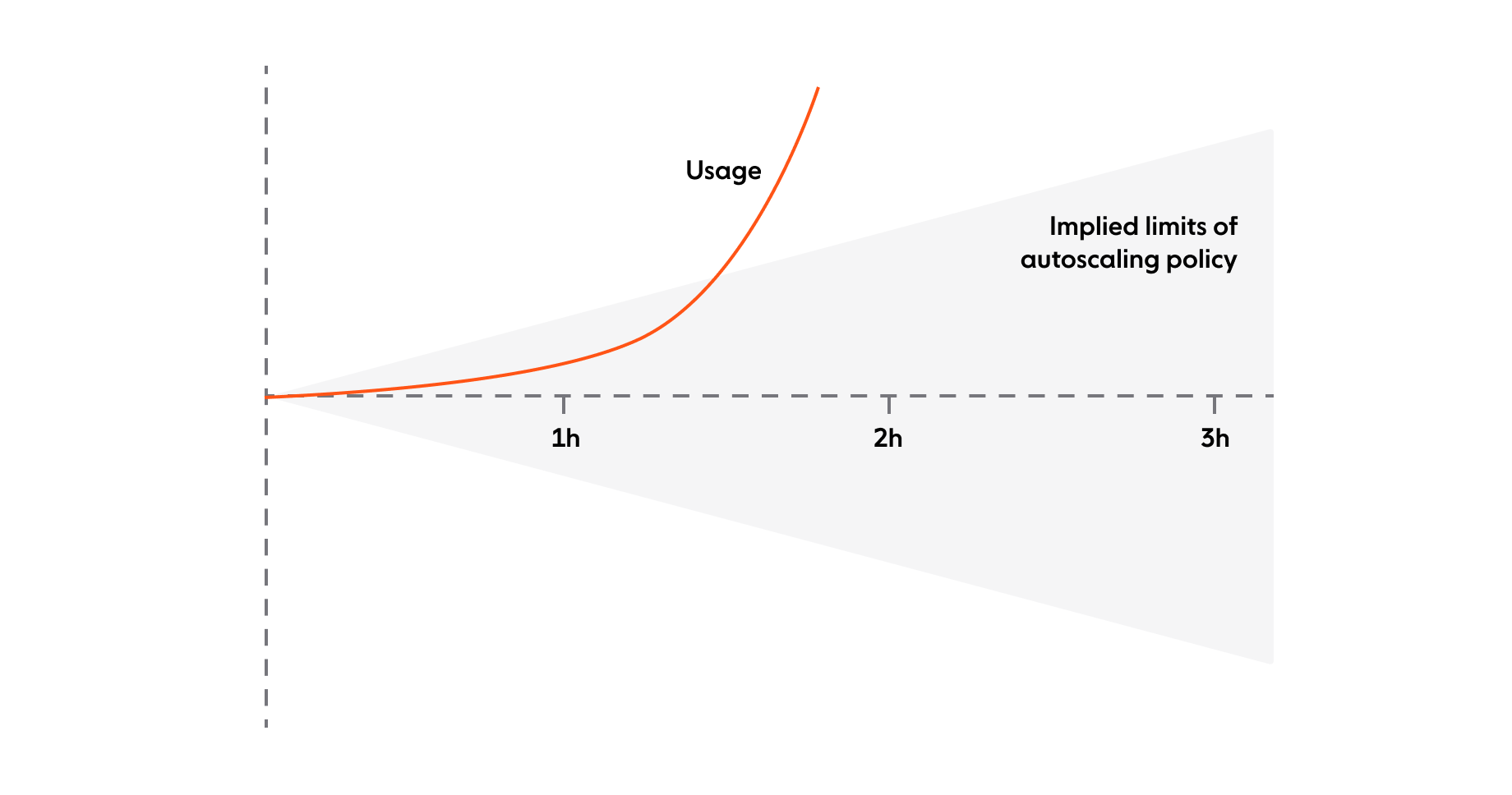
More complex scaling policies are more flexible. There is still some risk that we hit an AWS limit for bringing new instances online per minute (either a configured limit or one inherent to the service) but that is why we have an on-call rota so we can intervene manually when needed.
Autoscaling helps us meet load when it peaks while remaining more efficient most of the time. Overall we can provide a more responsive service than we could if we just had a fixed static capacity that we adjust manually.
| Related content: The four pillars of dependability |
Serverless
“Serverless” application hosting just has the autoscaling configuration built in and managed by the provider, as well as some other operational stuff you’d otherwise have to deal with yourself. However, underneath the service still ends up being provided using the same hardware in the same datacenters – with the same underlying cost structure and economics.
The good news is that the cloud provider’s engineers are quite possibly better at managing platform infrastructure for your service – including its autoscaling setup – than your own engineers would be. Does that change the story in terms of cost savings? The bad news is that the answer is probably no. Cost savings from autoscaling are still inherently very limited and the only way to get good pricing is to have long term predictable usage and buy in bulk.
Is autoscaling worth it?
In conclusion, if you are considering reactive autoscaling of your cloud resources purely as a cost-saving measure, I would suggest you reconsider, because:
- the cost savings achievable are probably fairly low,
- the engineering effort needed to get there is probably substantial, and
- your cloud provider is probably eager to give you a discount larger than what you could get from this, if you even out your usage and stop turning machines off all the time.
That said, an autoscaling group is a very useful abstraction for operational reasons.
For us to provide a fixed static capacity that could meet all of the theoretically possible customer demand would be grossly inefficient most of the time. At Ably we use a combination of committed capacity, with on-demand scaling for short-lived or unexpected spikes, to combine cost optimization with operational flexibility and serve customers whose usage patterns are unpredictable.
What about predictive autoscaling?
Reactive autoscaling adds or removes resources based on current utilization. Predictive autoscaling adds resources based on predicted utilization: you have some sort of model that predicts when you will have a large increase in utilization. This could for example be a machine learning model looking at past utilization data, or the marketing team telling you they’re about to run a TV ad during a large live event, or the calendar telling you it’s Black Friday.
This model output can be provided as additional input to the autoscaling algorithm to get it to provision additional resources when high load is expected but current load doesn’t show that yet.
This is an emerging field Ably is very interested in. If you’d like to help, we are hiring for roles in various engineering teams, including Infrastructure!
About Ably
Ably's platform powers synchronized digital experiences in realtime over a secure global edge network for millions of simultaneously connected devices. It underpins use cases like virtual live events, realtime financial information, and synchronized collaboration.
Ably offers WebSockets, stream resume, history, presence, and managed third-party integrations to make it simple to build, extend, and deliver digital realtime experiences at scale.
Take our APIs for a spin to see why developers from startups to industrial giants choose to build on Ably to simplify engineering, minimize DevOps overhead, and increase development velocity.