

Introduction
This blog post describes Ably’s journey as we build the next iteration of our global network; it focuses on the design decisions we faced. If you are interested in how you can network AWS accounts together on a global scale then read on!
Ably operates a global network spanning 8 AWS regions with hundreds of additional points-of-presences. This provides our customers with unrivaled realtime messaging and data streaming performance, availability, and reliability.
The existing network comprises multiple AWS Virtual Private clouds (VPCs) per region provisioned using AWS CloudFormation (CF). Depending on their function, certain VPCs are VPC peered together in all regions to form a mesh, using our internal CLI (command line interface) tool.
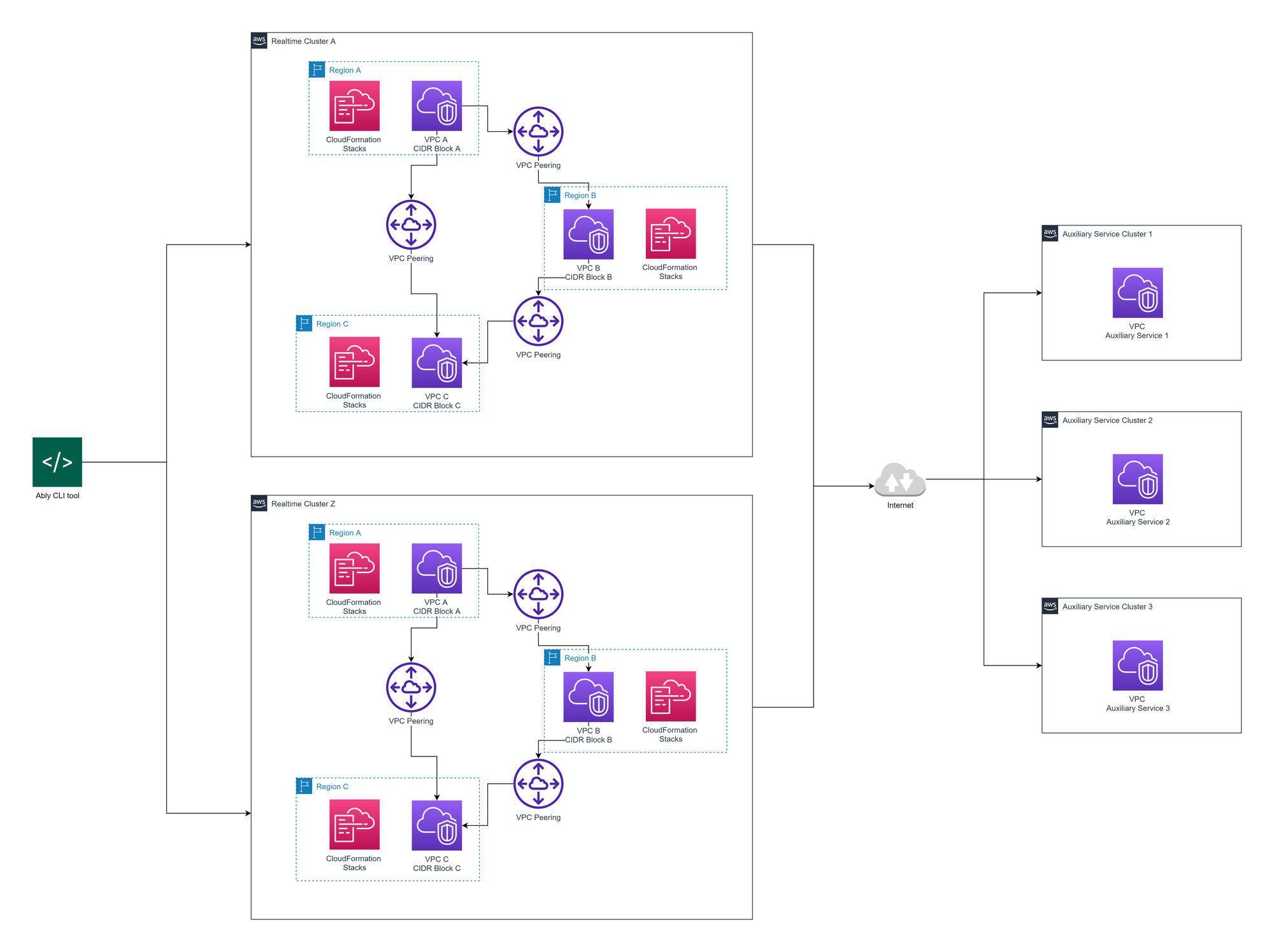
Out with the old
As with all engineering projects, Ably’s original network design included some technical debt that made developing new features challenging. It was time to start the next iteration of the design.
When we deploy a new realtime cluster, our infrastructure management CLI tool will iterate over all regions this cluster should be deployed to and create CF stacks. These deploy regional components such as Network Load Balancers, Auto Scaling Groups, Launch Templates, etc.
VPC peering is complex at scale, you need to initiate and accept the pending VPC peering connections, and update all route tables with all the other VPC Classless Inter-Domain Routing (CIDR) blocks you have peered to. CF is not well suited to this task so we used custom scripting. However, switching from declarative CF to imperative Ruby meant that the lifecycle of the resources was now our responsibility, such as deleting the VPC peering connections.
This led to extra effort being spent ensuring idempotency and created a fragile relationship between CF and the script. For example, if a new subnet with a new route table gets added in CF, we need to ensure the corresponding changes are made to the script or risk not having connectivity from all subnets.
There was also no centralized IP Address Management (IPAM). Every region a realtime cluster operates in has a separate CIDR block but it’s the same for different realtime clusters, which are not peered together. This becomes a problem when you want to peer realtime clusters with other types of clusters, say our internal metrics platform. We would only be able to peer one realtime cluster to the metrics network. We had no global IPAM available to dictate who gets what IP.
Network components design
There were 4 primary components to our design:
- Inter-VPC Connectivity - how do we connect our VPCs together to provide internal, private connectivity?
- Multi Account support - when we add new AWS accounts, how do we easily integrate them into the network?
- IPAM - what will our IP address allocation strategy be to ensure we can easily route networks together?
- IPv6 - how can we realize the benefits of IPv6 and support new customer requirements?
The components were all related with each choice impacting at least one other component. For example, how we obtain and use IPv6 addresses in our network directly affects our options for IPAM.
We decided it best to tackle this like a jigsaw puzzle and identify the corner pieces which would be used as the starting points for the design.
Network migration also seemed like a good time to simplify our terminology. We have multiple distinct clusters for different purposes such as dev, sandbox, staging and multiple production clusters. In order to allow these resources to be managed collectively more consistently, we formalized the concept of environments, which are broad categories of resources with different criticality. A decision was made to provide two environments, prod and nonprod. Resources in the prod environment have access to customer data, are relied upon by external parties, and must be managed so as to be continuously available.
Inter-VPC connectivity
How we intend to peer the networks between accounts was identified as the primary decision and the starting point. It had the biggest effect on all the other choices as if we chose VPC Peering, it would limit the quantity of VPC networks we could provision.
There were two contenders, Transit Gateway and VPC Peering. Some of our internal services communicate with other nodes in a cluster directly and not through a load balancer. This meant AWS Endpoint Services via PrivateLink was not viable as a global option but could be used in the future for individual services. There is also the issue of PrivateLink not working cross-region without additional VPC connectivity setup.
AWS Transit gateway (TGW)
There is a TGW in every region, which has attachments to every VPC in the region. Each regional TGW is peered with every other TGW to form a mesh.
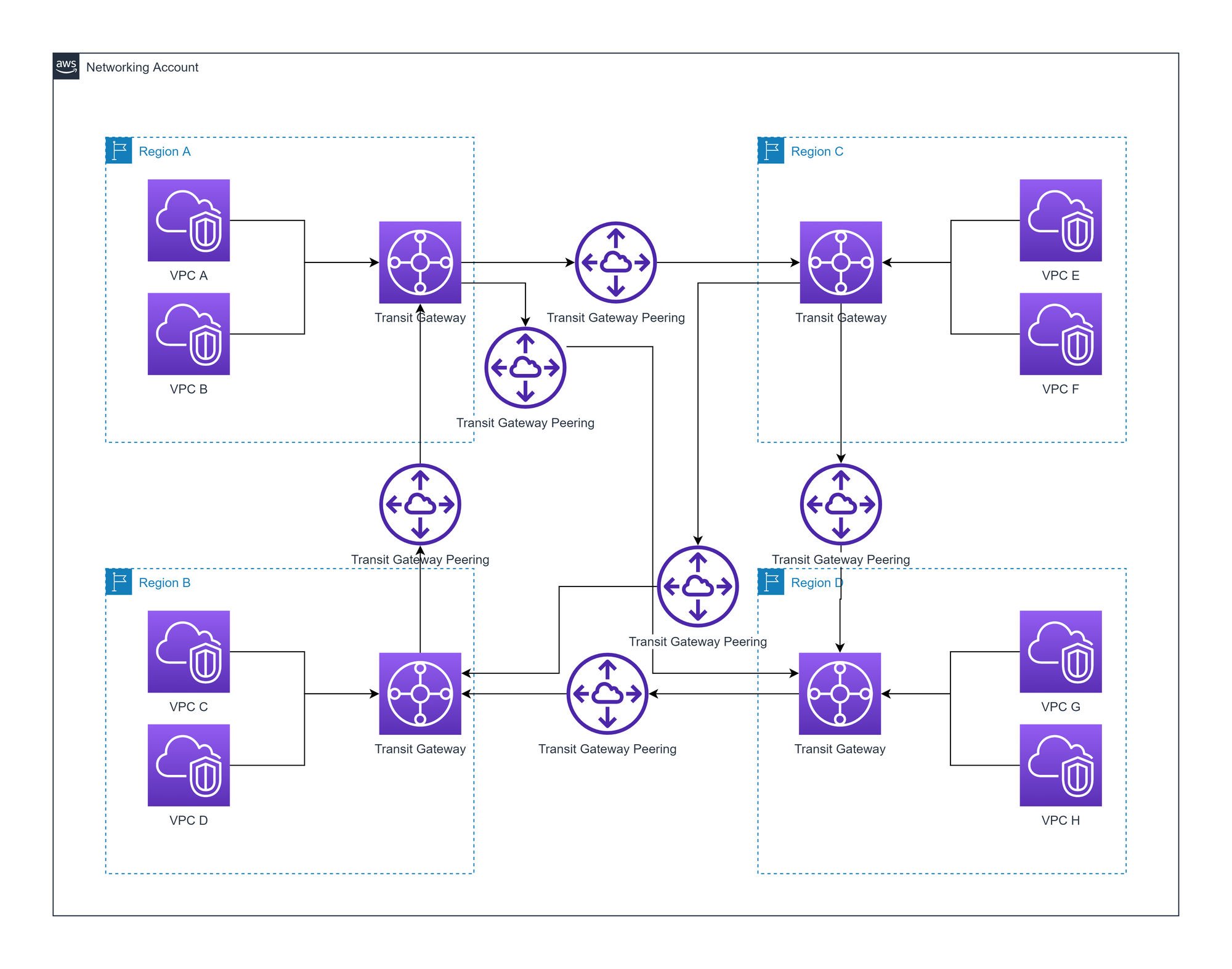
Advantages of AWS Transit Gateway
- Allows for more VPCs per region compared to VPC peering
- Better visibility (network manager, CloudWatch metrics, and flow logs) compared to VPC peering
- TGW Route Tables per attachment allow for fine-grained routing
- Complexity is based on region count
Disadvantages of AWS Transit Gateway
- Additional hop will introduce some latency
- Potential bottlenecks around regional peering links
- Priced on hourly cost per attachment, data processing, and data transfer
AWS VPC peering
Every VPC is peered with every other VPC to form a mesh
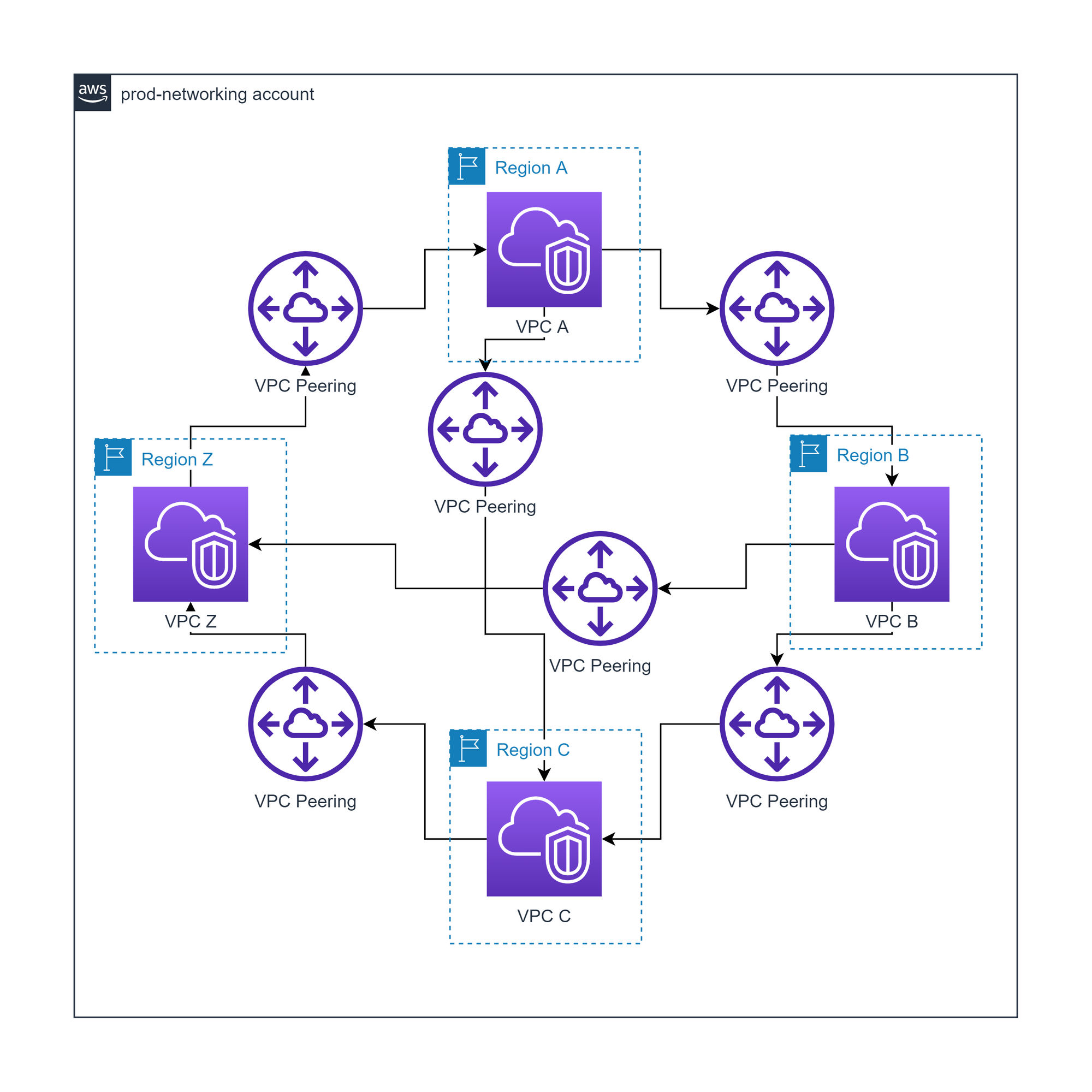
Advantages of AWS VPC peering
- Priced only on data transfer
- No bandwidth limit
Disadvantages of AWS VPC peering
- Each VPC increases the complexity of the network
- Limited visibility (only VPC flow logs) compared to TGW
- Harder to maintain route tables compared to TGW
VPC peering has the additional disadvantage of not supporting transitive peering, where VPCs can connect to other VPCs via an intermediary VPC. For us this was not an issue as we wanted a mesh network for high resilience.
VPC peering or Transit Gateway? Ably’s decision
We went with VPC peering.
Performing VPC flow log analysis of our current traffic indicates we are sending in excess of 500,000 packets per second over our existing VPC peering links. Inter-region TGW peering attachments support a maximum (non-adjustable) limit of 5,000,000 packets per second and are bottlenecks, as you can only have one peering attachment per region per TGW. This means TGW leaves us less than 10x headroom for future growth.
Additionally, we send significant volumes of inter-region traffic per month. TGW would cost $20,000 per petabyte of data processed extra per month compared to VPC peering.
VPC peering has no additional costs associated with it and does not have a maximum bandwidth or packets per second limit.
Multi-account support: cluster and environment isolation
To support easier management and global peering of any VPCs that were provisioned, we made a decision early on to create any VPCs in a central networking account and use AWS Resource Access Management (RAM) to share the subnets of the VPCs into the needed accounts.
We needed to decide exactly how we were going to split our prod and nonprod environments.
Please note in the following diagrams we have only shown one region, two environmental accounts, and one subnet resource to represent both public and private subnets to aid in readability.
General purpose shared subnets
In the central networking account, there is one VPC per region. This will have a family of subnets (public, private, split across AZs), created and shared to all the needed AWS accounts. All resources in all environments get deployed to the same family of subnets.
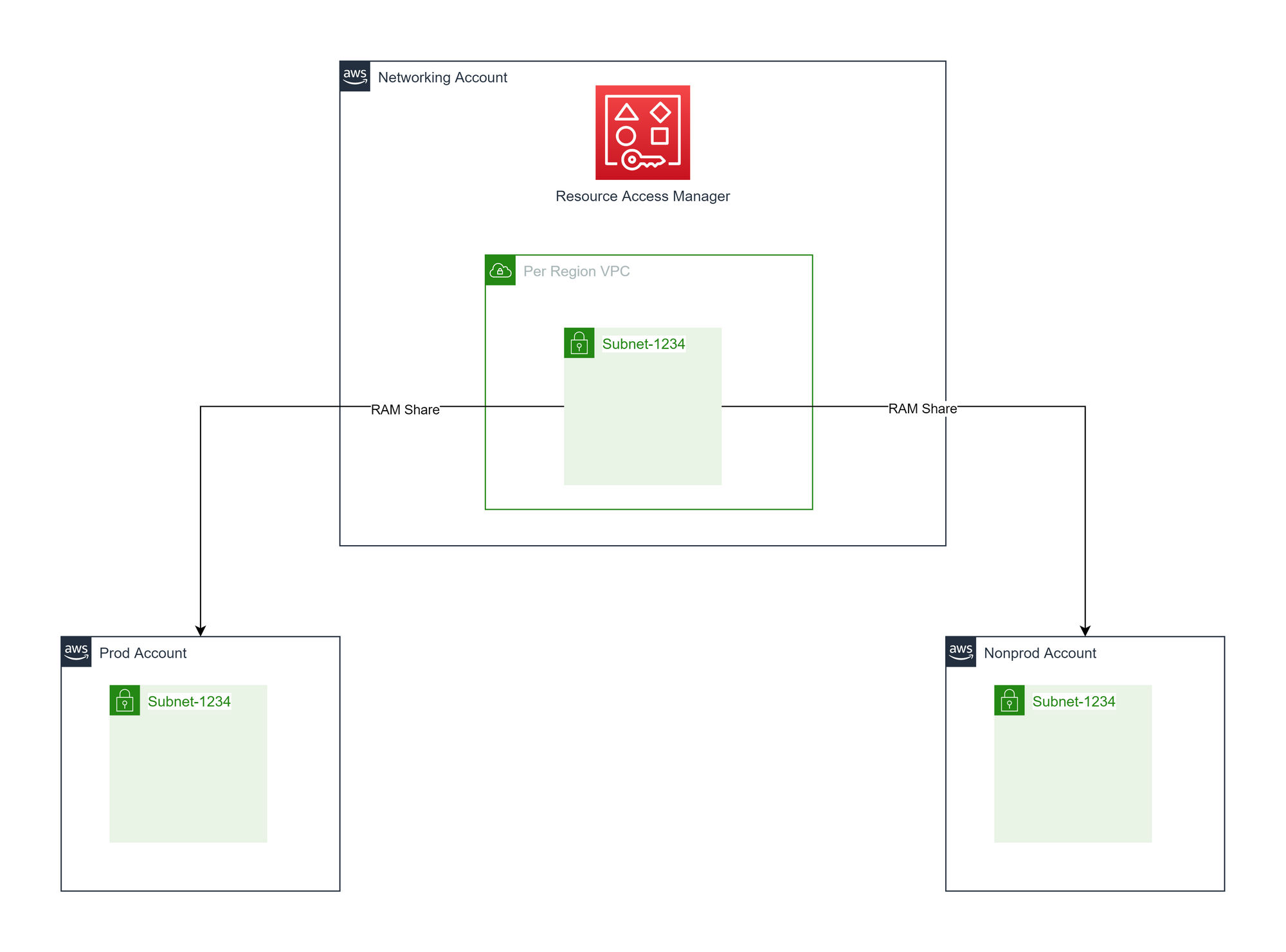
Advantages of general purpose shared subnets
- Only regional IP provisioning planning needed.
- The simplest setup compared to other options.
- Will likely be the cheapest overall to run, in terms of providing shared services such as NAT Gateways.
Disadvantages of general purpose shared subnets
- No OSI layer 3 or 4 traffic isolation.
- Additional work required for layer 7 isolation
- Cannot easily create VPC endpoint policies
Cluster and environment-specific shared subnets
In the central networking account, there is one VPC per region. This will have a family of subnets (public, private, split across AZs), created. Every cluster type gets a different family of subnets per environment. The subnets are shared to appropriate accounts based on a combination of environment and cluster type.
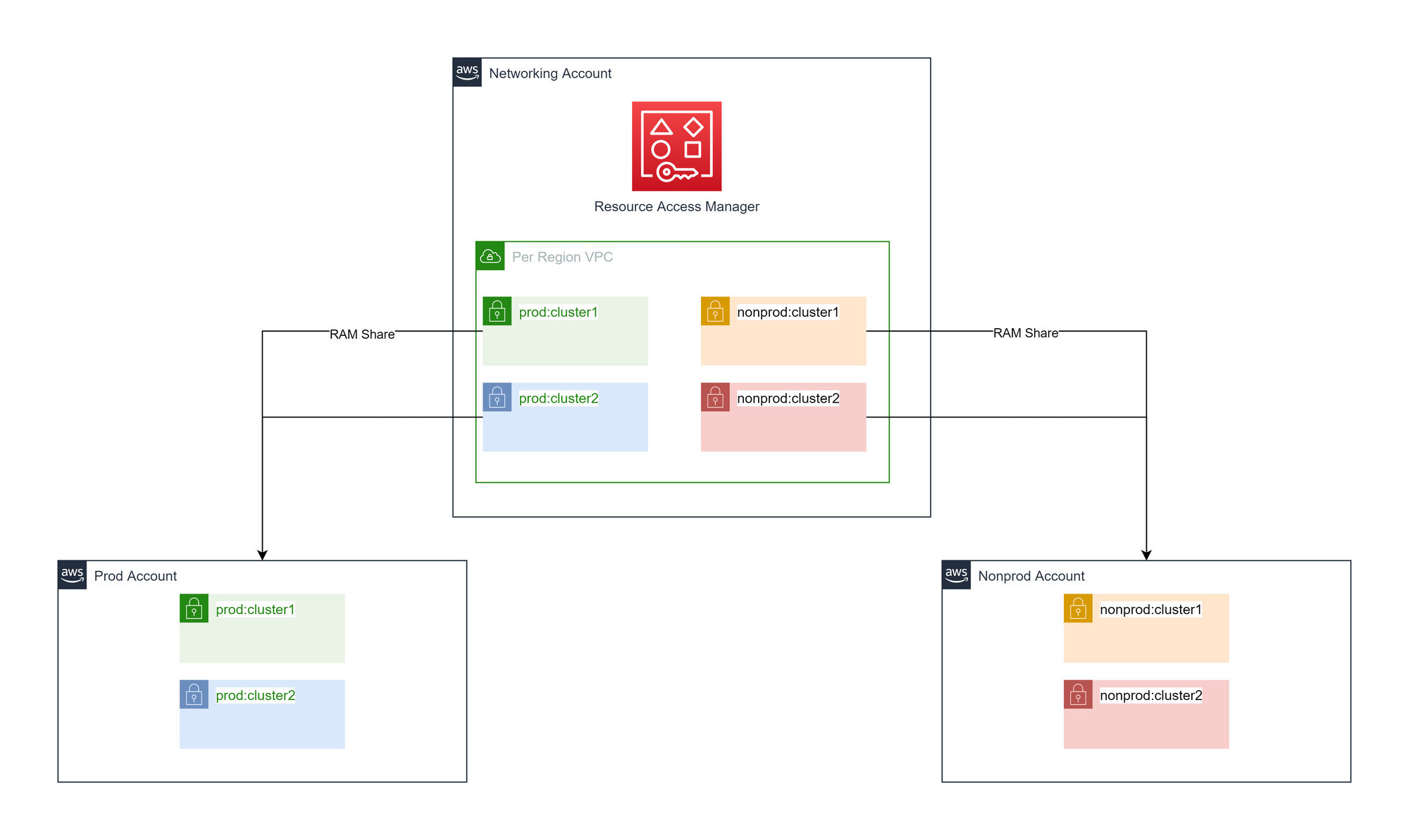
Advantages of cluster and environment-specific shared subnets
- Layer 4 isolation at the instance level.
- Can restrict access to production resources.
Disadvantages of cluster and environment-specific shared subnets
- No layer 4 isolation at subnet level.
- We would need to maintain prefix lists for all cluster type and environment combinations in order to use IP based security.
Cluster and environment-specific VPCs
In the central networking account, there is one VPC per region per cluster type per environment. Each VPC will have a family of subnets (public, private, split across AZs), created. The subnets are shared to appropriate accounts based on a combination of environment and cluster type.
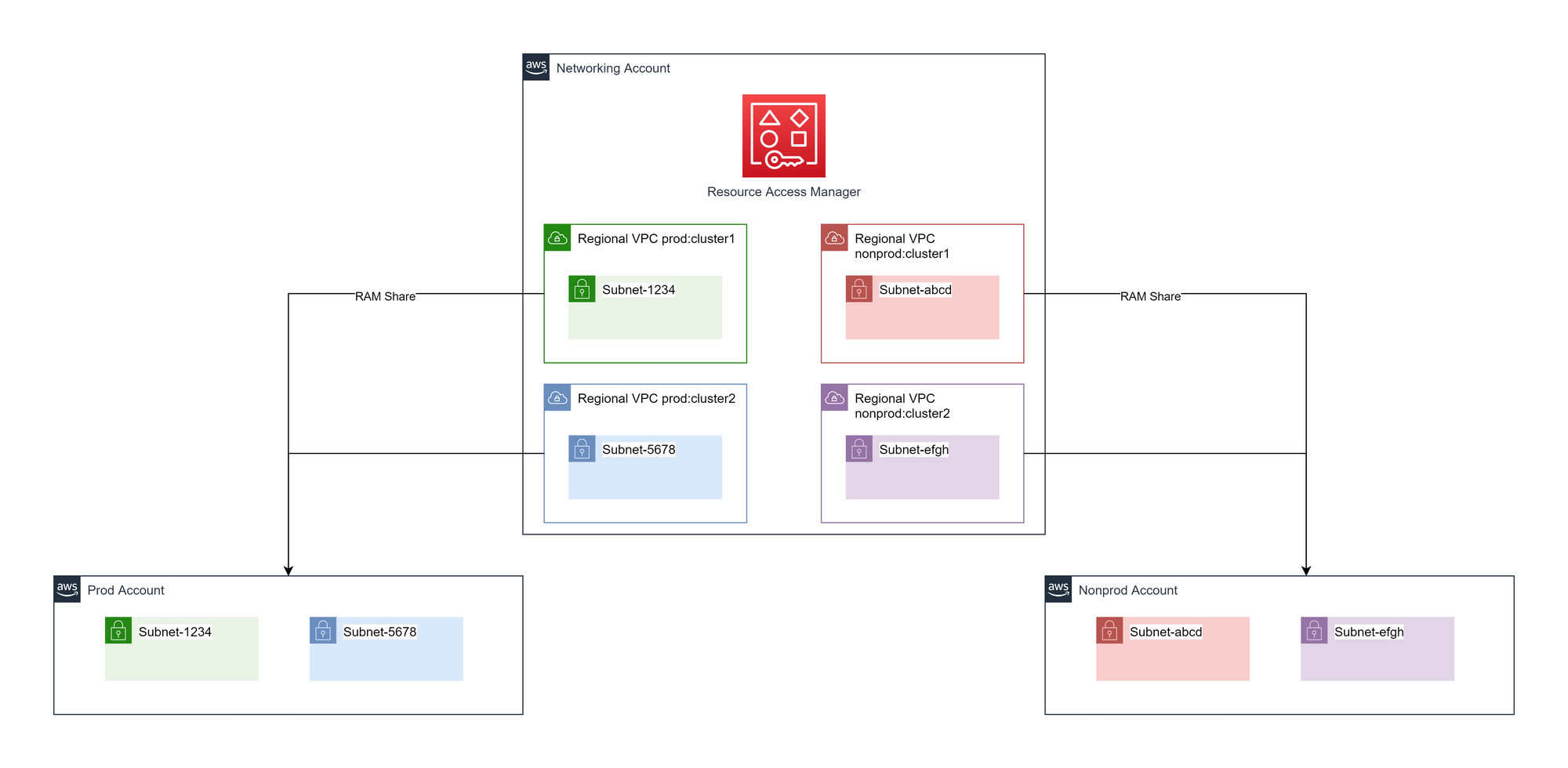
Advantages of cluster and environment-specific VPCs
- Layer 4 isolation at the instance level and subnet.
- Layer 3 isolation as by means of not routing certain traffic.
- Allows for source VPC condition keys in resource policies.
Disadvantages of cluster and environment-specific VPCs
- Will entail a more expensive inter-VPC connectivity design.
- Providing shared DNS, NAT etc will be more complex than other solutions.
Nonprod in prod?
You may be wondering why we have networks called nonprod provisioned into our prod network account. As we quickly discovered during this project and others relating to AWS account architecture, naming is hard.
We coined the term Ably Landing Zone (ALZ), which is in line with AWS terminology, to help with rectifying the confusion. The ALZ is a service provider, it provisions resources that are consumed by both nonprod and prod environments, such as our AWS SSO Setup.
For the ALZ, all environments are treated as prod, the names are inconsequential. If we were to take down the nonprod environment’s networks and stop all engineers from doing development, there would be a big business impact.
Multi-account support: Ably's decision
We are creating a prod and nonprod VPC per region, with 3 public and private subnets per VPC each in a different availability zone, apart from us-west-1 which only has 2 availability zones for new accounts. The prod VPC subnets will be shared with the prod related AWS accounts, and similar for nonprod. All prod resources will be deployed into the same set of prod subnets. All prod VPCs will be VPC peered with each other, as will nonprod but prod VPCs will not be peered with nonprod VPCs. However, they will still have non-overlapping CIDRs to cater for future requirements.
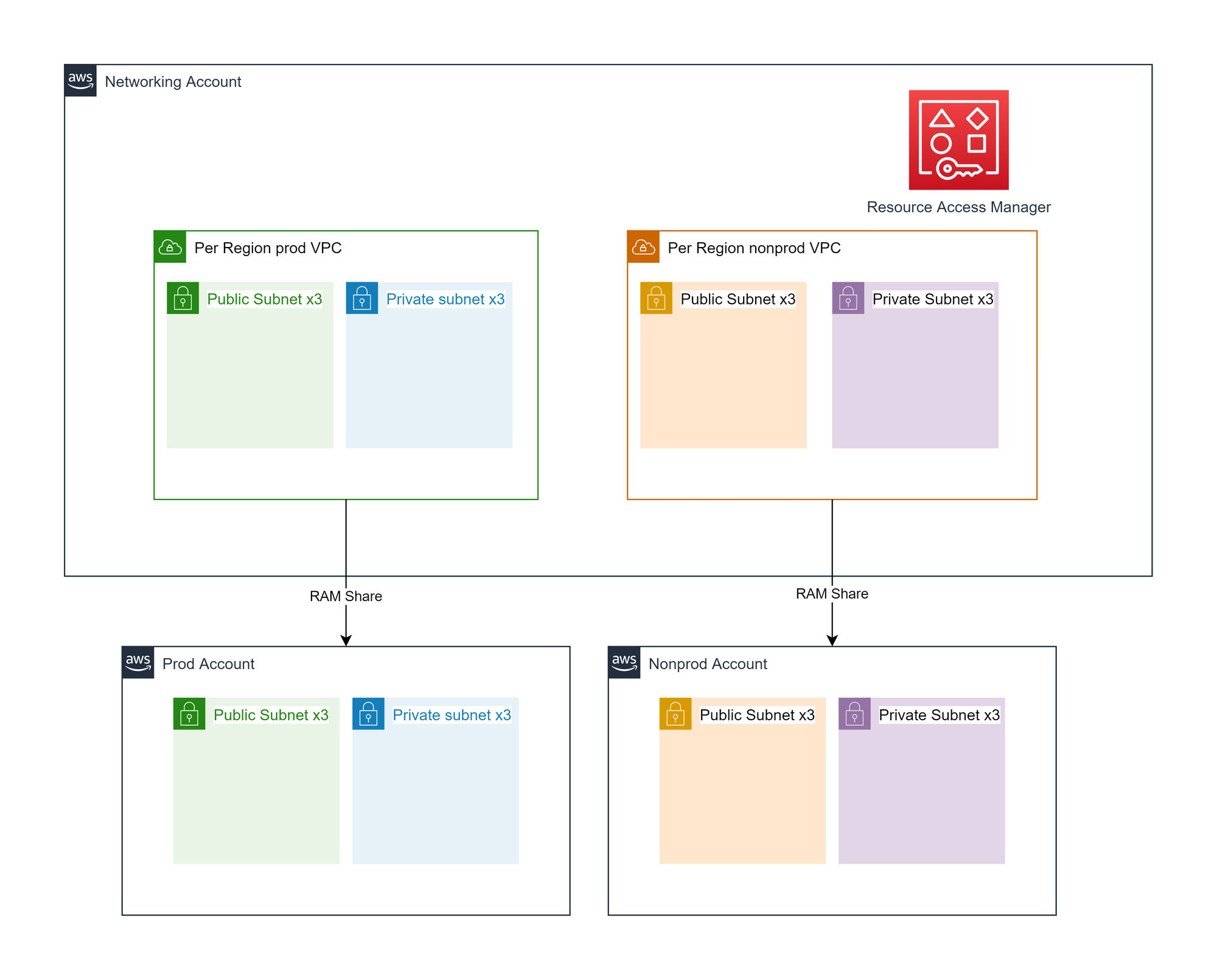
Our decision to use VPC peering limits our maximum VPC count. You can have a maximum of 125 peering connections per VPC. AWS VPC best practices recommend you do not use more than 10 VPCs in a mesh to limit management complexity. To create a mesh network where every VPC is peered to every other VPC, it takes n - 1 connections per VPC where n is the number of VPCs.
This yields a maximum VPC count of 124. Therefore, a single environmental VPC per region gives us additional capacity to add more VPCs in the mesh if needed. Depending on future requirements, we do not necessarily have to create a mesh of all networks and can use technologies such as AWS PrivateLink to enable secure, private cross-VPC communication without a peering connection.
Each VPC can support 5 /16 IPv4 CIDR blocks for a maximum count of 327,680 IPs per VPC. Each subnet can have a maximum CIDR block of /16 which contains 65,536 IPs. Based on our current IP usage count there should be no risk of IPv4 exhaustion.
We chose not to use separate subnets for different cluster types as to realize the security benefit of this would require creating and maintaining regional AWS prefix lists of each cluster and ensuring they are applied appropriately to any security groups. This would be complex and entail a large overhead.
Network ACLs have a default rule limit of 20, increasable up to 40 with an impact on network performance, and do not integrate with prefix lists. This low rule limit would quickly be breached if we started to specify 6 subnet CIDR blocks per cluster per region and would not scale. Security Groups cannot be referenced cross-region and therefore they also cannot be used.
There is a future project planned to provide service authentication and authorization to all components which would be used to provide the controls NACLs and SGs otherwise would for traffic in the same environment.
IPAM: Permutations of IPAM pooling
The examples below are not exhaustive but cover the main permutations of IPAM pooling we might choose. Each one can be simplified and cut off at any depth.
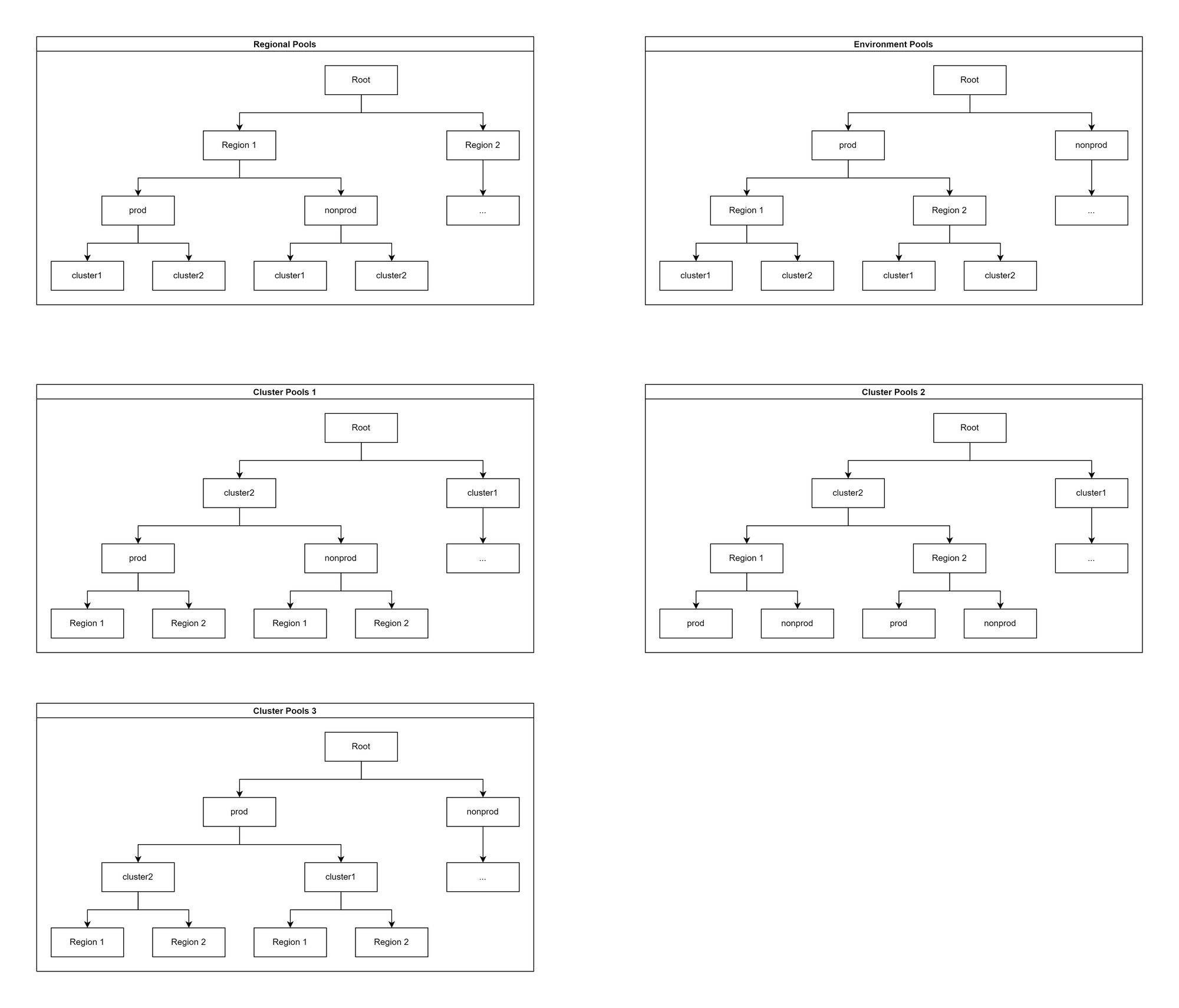
The choice we go for will be greatly influenced by the need for IP-based security. The lower down the tree the cluster type pools are, the harder it is to achieve this. On the flip side, the lower down the regional pools are, the trickier it becomes to peer cross-regional networks.
Ably’s decision
We are using the structure below:
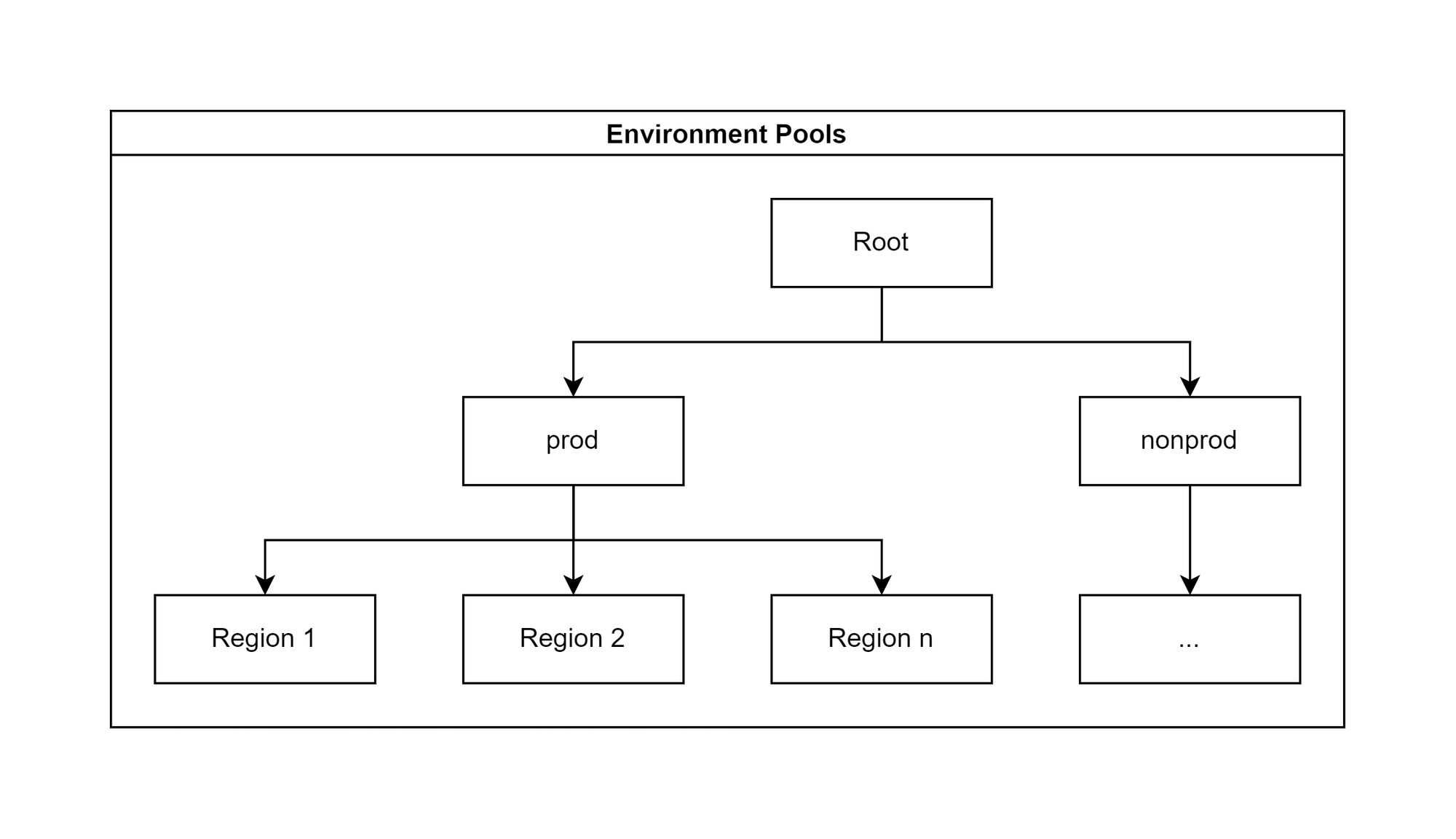
This decision was based on our previous decision to use the same family of subnets for all cluster types. We can easily differentiate prod and nonprod traffic, and regional routing only requires one route per environment.
IPV6 deployment options
There are two main ingress paths for customers, CloudFront to NLB, and direct connections to our NLBs. CloudFront distributions can easily be switched to support IPv6 from the target in the distribution settings. They always communicate with the origin (the NLB) over IPV4, so no changes to our infrastructure are required.
For direct connections to our fallback NLBs, they can be operated in dual-stack mode where they support both IPv4 and IPv6 connections from the source. They automatically perform NAT64 to allow communication with IPv4 only destinations in AWS. See AWS reference architecture. This means our VPCs would also need to be dual stack but we don’t necessarily have to route IPv6 traffic internally, as it will be translated to IPv4 at the border, therefore avoiding the need for IPv6 IPAM.
If we decide at a later date we want to provision IPv6 addresses from IPAM, we can add a secondary IPV6 block to the VPC, and re-deploy services as necessary. Alternatively, we can purchase an IPV6 block under the assumption we will want to route IPv6 traffic internally in the future without having to redeploy services.
IPV6 deployment: Ably’s decision
We decided to purchase a block of IPv6 space and will provision all VPCs and subnets as dual stack.
To ensure we can easily route traffic between regions we need a single IPv6 allocation that we can divide up intelligently. AWS can only provide non-contiguous blocks for individual VPCs. Trying to set up IPv6 later down the road after our new networks have been provisioned will likely require us to destroy and recreate resources, which will be time-consuming and complex to do so without downtime.
IPv6 also has the immediate benefit of lowering our AWS costs for any internet-bound traffic we can send over IPv6, as there are no additional AWS costs. The equivalent IPv4 traffic would otherwise be sent through a NAT gateway, which does incur additional costs.
AWS does not provide private IPv6 addresses as it does with IPv4 meaning we must use our public allocation for all deployments.
What's next?
With all the pieces selected, it was time to get started. We plan to document the build and migration process in due course!
About Ably
Ably's serverless WebSockets platform powers synchronized digital experiences in realtime over a secure global edge network for millions of simultaneously connected devices. It underpins use cases like virtual live events, realtime financial information, and synchronized collaboration.
On top of raw WebSockets, Ably offers much more, such as stream resume, history, presence, and managed third-party integrations to make it simple to build, extend, and deliver digital realtime experiences at scale.
Take our APIs for a spin to see why developers from startups to industrial giants choose to build on Ably to simplify engineering, minimize DevOps overhead, and increase development velocity.


