Ably is a platform for pub/sub messaging. Publishes are done on named channels, and clients subscribed to a given channel have all messages on that channel delivered to them. The Ably pub/sub backend is multi-region: we run the production cluster in 7 AWS regions, and channel pub/sub operates seamlessly between them. If you publish a message on a channel in one region, it is sent immediately to subscribers in the same region as you, and in parallel is broadcast to active instances of the same channel in other regions to reach subscribers in those regions.
A channel running in a region needs to know, when it starts, in which other regions that channel is already active, so it can subscribe to them. And once running, it needs to keep track of any subsequent changes to the set of active regions.
We've rolled out a complete redesign of the way that region discovery happens. We called this change 'channel global decoupling'.
This post explains why we designed it the way we did initially, why we decided to change course, and how we arrived at the new design.
(For clarity, in the context of this post, 'channel' or 'regional channel' refers to a running entity on our backend that processes and directs messages. It is located on one of our servers which is determined by consistent hashing of the channel ID. It is distinct from the idea of a channel object in an SDK).
So what was the original design?
Originally, for a given channel (for example, the channel "foo" in someone's app), one of the regions that that channel could be active in was deterministically chosen as the 'GlobalChannelResource' for that channel. Its purpose was to be a single point, somewhere in the cluster, that was responsible for determining which regions channel "foo" was active in, and communicating that to the other regional "foo" channels. It would always be active, even if there were no publishers or subscribers in its region.
When a regional channel was first activated (say, as a result of a connection trying to attach to it), it would try to connect to that channel's GlobalChannelResource (unless, of course, it was lucky enough to be the GlobalChannelResource itself). The GlobalChannelResource would then tell the new regional channel what other regions are already active. (If the GlobalChannelResource was not previously active, it would be activated by the first region to connect to it).
What was the reasoning behind the original design?
It makes region discovery simple and scalable. A new regional channel has to contact only one place (the GlobalChannelResource) to find out what other active regions exist, and it can get all updates to the set of active regions from the same place. There is a single source of truth for what regions are active for a channel. And since the amount of work a new regional channel has to do for region discovery does not depend on how many regions we run the cluster in — it always has one place to contact — the process scales well with the number of regions that we run the cluster in.
Sounds good. Why did you decide to change it?
Three main reasons:
Issue 1: Activation speed
Imagine a cold start: a channel being poked into existence for the first time (not having previously been active in any region), activated by a client in us-east-1 (West Virginia).
Say that channel happens to have its GlobalChannelResource located in ap-southeast-2 (Sydney). That means that before anyone can use it, the channel in Virginia had to poke the channel in Sydney to start.
Actually, it's worse than that: as well as the main GlobalChannelResource there was an Alternate global resource, in another region, that the GlobalChannelResource has to contact when it starts (which helps to provide continuity when the GlobalChannelResource relocates, the details of which don't matter for this post).
Say the Alternate was in eu-central-1 (Frankfurt). So Virginia had to contact Sydney, then Sydney in turn had to contact Frankfurt before it could reply to Virginia. Only then was the channel finally ready to be used.
That's a lot of inter-region latency. If you were unlucky with locations of global resources, this could take two or three seconds before the channel actually became ready, even if the channel's users were all from the same region. Our cold channel activation times were poor, and a clear weak point of the service.
Issue 2: Resource usage
In many cases we were using a lot more resources, and doing more inter-region network traffic than we needed to. All the users of a channel might be in a single region, but we'd still run the channel in all three regions, each processing all messages as well as subscribing to each other. (Two if you were lucky enough to have the actually-used region be one of the global resource locations.)
Issue 3: Reliability in the face of disruption to a region
Say a channel's locations are as above (GlobalChannelResource in Sydney, Alternate in Frankfurt, you in Virginia). Now say that there's some inter-region network issue like Sydney being temporarily unresponsive due to a network partition. Well, you're out of luck, the channel can't start. Doesn't matter if none of its users are anywhere near Sydney, the GlobalChannelResource and the Alternate have to both be responsive to activate a channel.
(In a clear and persistent partition, the global resource would have relocated. But this is relatively rare; a far more common form of disruption is such that regions, or even individual locations, are not decisively absent, just inconsistently responsive).
Once the channel is active you're in a marginally better position... but only if no new regions want to join, or existing ones want to leave. This still isn't ideal.
This wasn't just a theoretical problem. Transient network issues in one region could regularly be seen in error rates for customers who didn't have any clients in that region. We ran in seven regions with automatic alternate-region fallbacks, we really should have been getting global fault-tolerance out of that — but if you were unlucky enough to be using a channel whose GlobalChannelResource fell in a region experiencing issues, it didn't matter that you as a client could be directed to a fallback region, the channel could still be unusable.
We ultimately decided that the design tradeoffs we made when we initially designed the system needed reevaluating. As nice as the properties were that led us to the initial design, we concluded it would be worth sacrificing them if it let us solve these problems.

Alternative designs
As a result, we started considering possibilities for purely peer-to-peer region discovery that didn't rely on having a global role.
What's a really simple thing we could do? One strategy might be: on start, broadcast out an "Are you there?" probe to (the calculated channel location in) every other region.
The obvious downside to this strategy is that with every region contacting every other region, the total amount of region discovery traffic goes as the square of the number of regions.
You could imagine various refinements to that. Perhaps regions could persist themselves into a database when they activate and check on start for what other regions are active. Or regions could send what other regions they know to be active in the reply to the initial query, in a gossip-like mechanism, so you only have to find a single region that's already active — though that doesn't help much with knowing where to look to first. Or you could divide the cluster into a few federations of regions, with a two-stage peer discovery (within each federation as well as between federations).
But in the end we decided to just go with the simple thing that we first thought of. While O(n²) in total, it's only O(n) for any individual node (assuming relatively even region sizes); the work on the receiving end to handle a probe negatively is small; and ultimately, n is not very large. And a very simple strategy has the advantage of being easier to hold in your head and to convince yourself of its correctness (as well as to model more formally).
The new region discovery design in detail
On start, a new regional channel gets a list of candidate regions, and for each region, contacts the location where the channel would be if it was active in that region, to ask if it is there.
If the answer is yes, the new channel starts monitoring (and subscribing to messages from) that region; if not, nothing further to do.
The destination region will only respond with a 'No such channel here' if it agrees that a channel would be there if it was active in that region. If it doesn't agree (perhaps there's some cluster state update that hasn't yet propagated to one of the ends), then it declines to give a definitive 'no', and the origin keeps monitoring and periodically retrying. Eventually either source or destination will get the new update. Similarly if the call fails or times out, the origin keeps retrying (with backoff). It only stops if it gets a definite confirmation that the target instance, while agreeing it's the right one, confirms the lack of a channel.
When a new region starts up, and it contacts every other region, that probe notifies the other regions that the new region is active, and so they all know to contact it.
Do these properties guarantee that we avoid persistent partitions (where two channel regions are active, but neither believes the other is)? Unfortunately this is not the case. Imagine a sequence of events where a cluster state inconsistency means that there's some period during which two instances in region Y, A and B, both believe they are the correct location for a channel. A client request comes via an instance that locates the channel on A and activates it, but the channel in region X believes it to be on B and probes that, which issues the reply that it has no such channel. The cluster inconsistency then resolves in favor of the channel being on A. This would leave region X believing there is no channel in region Y.
But we have another thing we do: we require that monitoring be symmetrical. The channel in region X can see what other regions (for that channel) are monitoring it. If it sees that region Y is monitoring it, it will continue trying to probe region Y no matter what replies it gets, until the cluster inconsistency is resolved and it starts contacting the right instance. So it cannot be the case that Y thinks X is active but X thinks Y is not. This means that in order to have a persistent partition, the relevant instances in both regions would need to independently and simultaneously experience the above pathological sequence of events. This is still not impossible, but brings the probability down to acceptably low levels.
Another pathological case would be a protracted complete inter-region cluster partition: some region or regions are partitioned from the rest of the cluster for so long that they mutually drop off each other's netmap entirely, and temporarily continue as isolated separate clusters. In the original design, the moment the clusters re-merge, a huge amount of work would be triggered, as the GlobalChannelResources all relocate to their newly-calculated locations. The new design avoids that, but leaves channels on each side partitioned from each other by default even after the clusters re-merge into one.
Given that any situation where the global cluster has a complete and persistent partition will be a major incident, our solution to this is to accept that that situation requires ops work to fix, for example by redirecting all traffic away from the regions in the smaller side of the partition toward the bigger side until channels on the smaller side close for inactivity, at which point traffic can be safely restored.
Measured results
So now that we've done this, have we achieved what we wanted to?
In short, yes, the new design seems to be a huge improvement over the old in all three of the metrics we were trying to improve. It is early days yet, and while we haven't had a chance to see the new mechanism cope with, say, a major network partition in the production cluster in real-world conditions, we are cautiously optimistic.
Result 1: Activation speed
The average time it takes to activate a channel from a cold start (here, measured by an internal quality-of-service monitor) dropped to less than a quarter of what it was before.

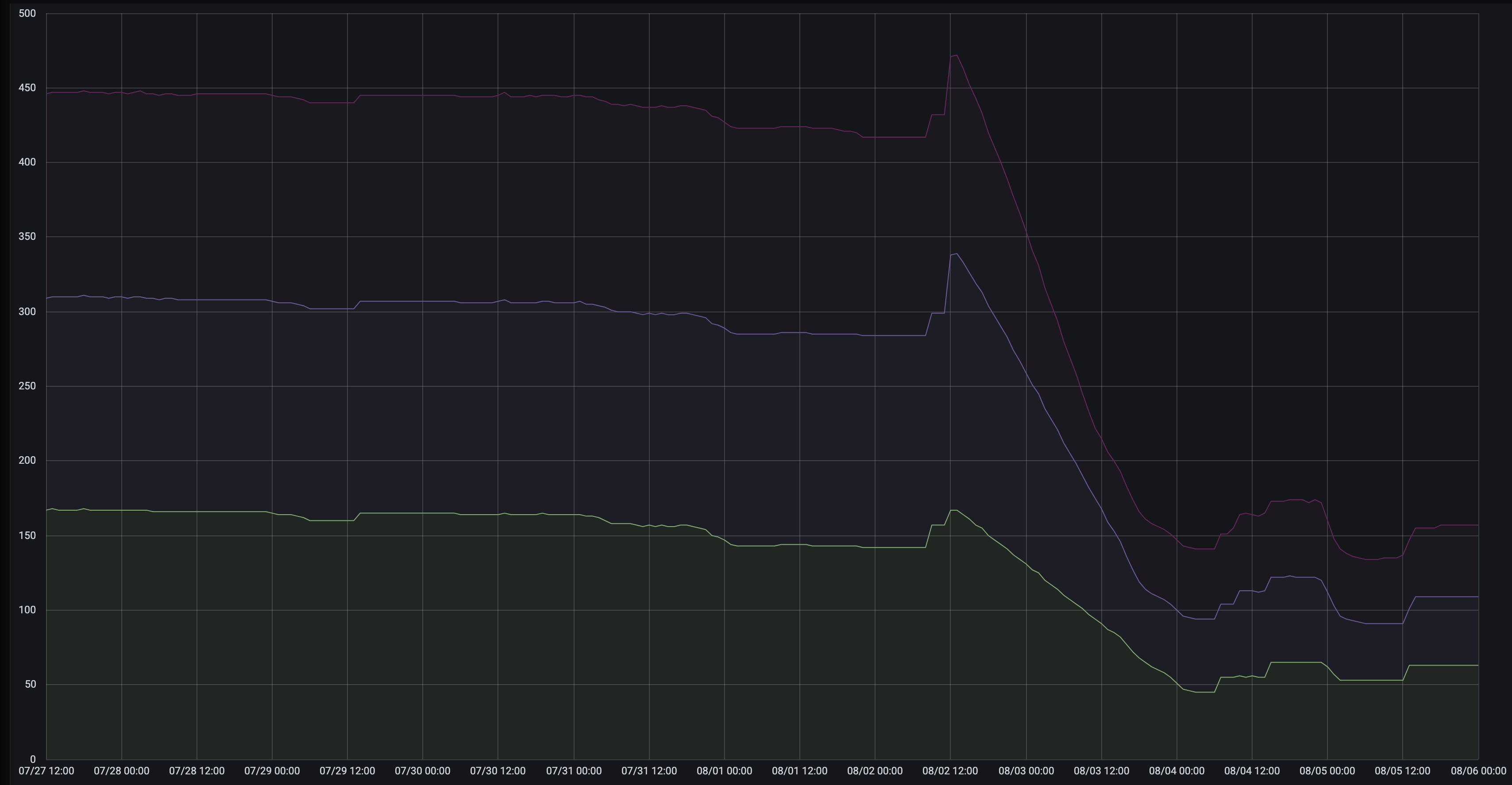
Result 2: Resource usage
The number of channel-hosting instances dropped drastically. The following graph shows a dedicated environment which runs in three regions; in each, the channel-hosting server count dropped to around a third of what it had been. (This environment was admittedly chosen for the dramatic size of the drop; most environments dropped by a smaller amount, to around 40-60% of their previous size).
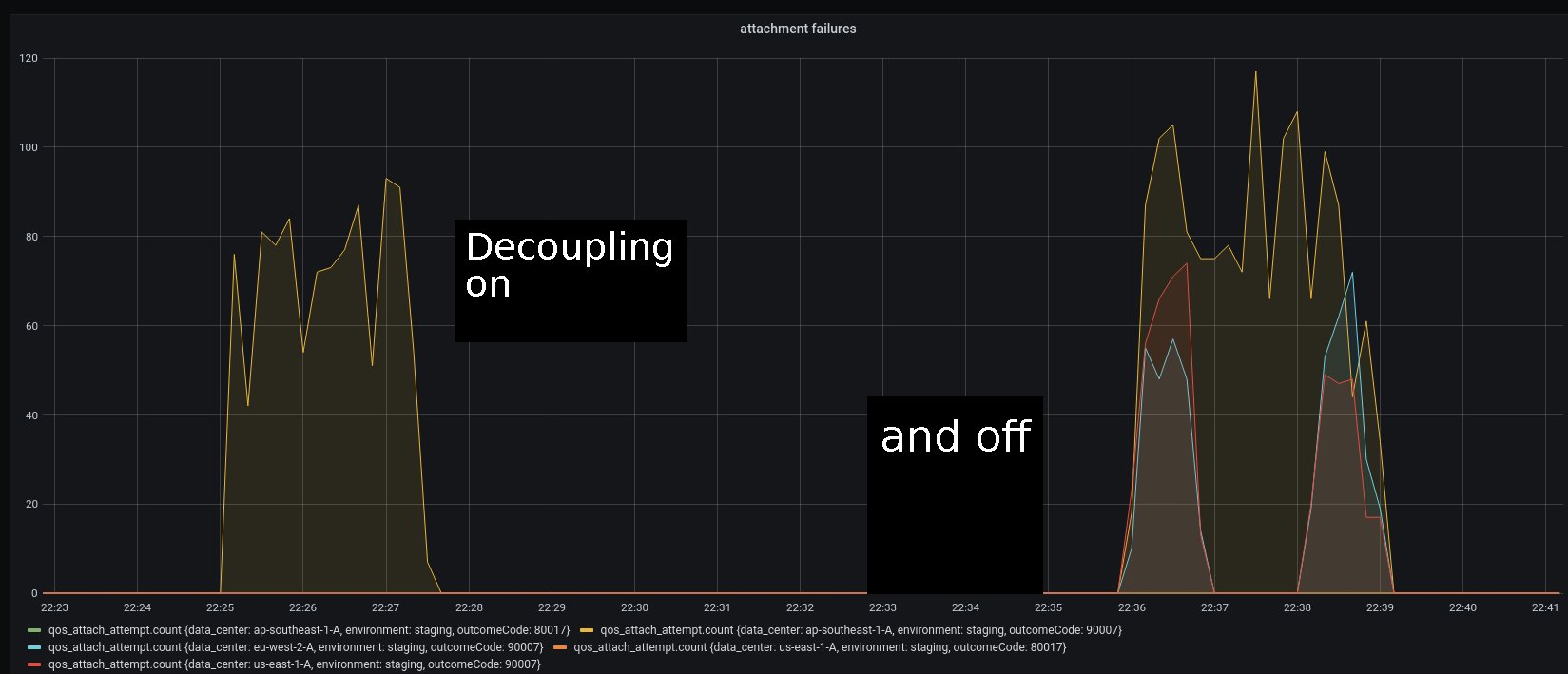
Result 3: Reliability in the face of disruption to a region
The following graph shows a very simple region disruption test with all channel-hosting instances in one region forced into a hard busy-loop for 120 seconds showing attach failures in different regions in a staging environment. This was again measured by our quality-of-service monitor, which was also measuring message delivery for every pair of regions. With decoupling on, the disruption is entirely limited to the sabotaged region.
Other complexities — lifecycle and occupancy events
There are a few other things that had to be reconsidered when we made this change.
There are various tasks that have to be done once, globally for a given channel. For example, emitting channel.opened and channel.closed lifecycle events; sending occupancy events to any channel.occupancy reactor integrations; and updating the stats for the number of active channels there are in a given application. These were previously all done by whichever regional channel happened to be the GlobalChannelResource. Now that we no longer have a GlobalChannelResource, we have to be more creative.
Occupancy events are sent to reactor integrations by whichever regional channels believe they are first in a miniature hashring consisting of the active regions for a channel. This is only eventually consistent -- in particular, in the early lifecycle of a channel, if multiple regions are activated simultaneously, both may believe they're the only region. But this doesn't matter for occupancy events, which are idempotent and are eventually consistent anyway.
(Why didn't we use leader election for things like this? We kept leader election as an option, ready to deploy if needed. But we didn't want to be too quick to reach for it. Leader election has its downsides — complexity, chattiness, relatively long election durations when the nodes are spread around the globe — which are especially palpable in a context where the set of participating regional channels may be changing quite often. Ultimately we never encountered a problem that we felt needed the guarantees that the Raft algorithm etc. would provide sufficiently to make it worth the costs).
For lifecycle events, the miniature-ring mechanism unfortunately wouldn't be good enough. channel.opened is easy enough: a regional channel emits one of those if, once it has completed region discovery, it has the earliest starting point of all of the regions it knows about. But imagine two regions losing their last client and closing approximately simultaneously. Which will emit a channel.closed event? Up until they both close, they may both see the other and believe that they themselves aren't the last active region, and so they don't feel the need to emit a closed event.
To solve this we have a concept of a 'lifecycle token'. A region that emitted a channel.opened event gets a lifecycle token. The rule is that, as a regional channel, if you hold the lifecycle token, you can't shut down without either handing the token off to another regional channel, or emitting a channel.closed event. And you can only do the latter if there are no other regional channels left alive. So in the situation of two channels racing to close, whichever one has the lifecycle token will decide it wants to close and try to hand the token off to the other, which will refuse it as it also wants to close. The channel with the lifecycle token is then forced to stay alive until the other has actually closed, at which point it can safely emit the closed event and shut itself down. (Given unreliable networks, there are sequences of events that can lead to multiple regional channels holding the lifecycle token, and by consequence multiple channel.closed events, but this isn't actually a problem, as a closed event is inherently idempotent. So we err on the side of multiple rather than zero closed events under a partition.)
Finally, for tracking the number of active channels in an app, we simply have each region contribute 1/N active channels to the app statistics if it sees N regional channels active (including itself). It's another use case where approaching the correct answer eventually is good enough; seeing a fractional number of active channels for short periods of time, while a little odd, doesn't cause any harm.
Further work
We have a roadmap crammed full of further reliability and scalability improvements. This is not even the last 'global decoupling' work we want to do. On our to-do list is app/account global decoupling: we want to take app and account functions such as statistics aggregation and limit enforcement, which are currently done by global roles (one for each individual app and account), and make them regional and peer-to-peer between regions. The goal is to make those functions similarly resilient against disruption in regions other than where genuine client activity is taking place. That change will doubtless have its own bag of distributed-systems problems that we'll need to solve.
If that sounds like something you're interested in, my team is hiring distributed systems engineers. Join us and help solve them!
Latest from Ably Engineering
- Ably's globally-distributed architecture for reliable, low-latency edge messaging
- Stretching a point: the economics of elastic infrastructure ?
- A multiplayer game room SDK with Ably and Kotlin coroutines ?
- Save your engineers' sleep: best practices for on-call processes
- Migrating from Node Redis to Ioredis: a slightly bumpy but faster road
- No, we don't use Kubernetes