Live experiences are at the heart of the modern web. And delivering them to small audiences is relatively easy, thanks to protocols such as WebSockets. But there is a challenge.
The difficulty involved in scaling WebSockets is non-linear. In other words, there comes a point where serving more clients demands significantly more complex architecture.
In this article we’ll look at one of the key decisions you’ll need to make when planning how to scale your WebSockets infrastructure: do you scale horizontally or vertically? And alongside that we’ll cover some of the technical challenges and their solutions, such as how to handle load balancing and data synchronization.
Let’s start by clarifying our terms.
What is vertical scaling?
Vertical scaling–or “scale up”–focuses on increasing the capacity of individual machines. It goes without saying that a more capable CPU with more RAM, for example, can handle more concurrent processes than a smaller machine.
The more headroom you have in a particular server, the more you can throw at it. But, apart from anything else, at some point you’ll hit a technological or financial limit.
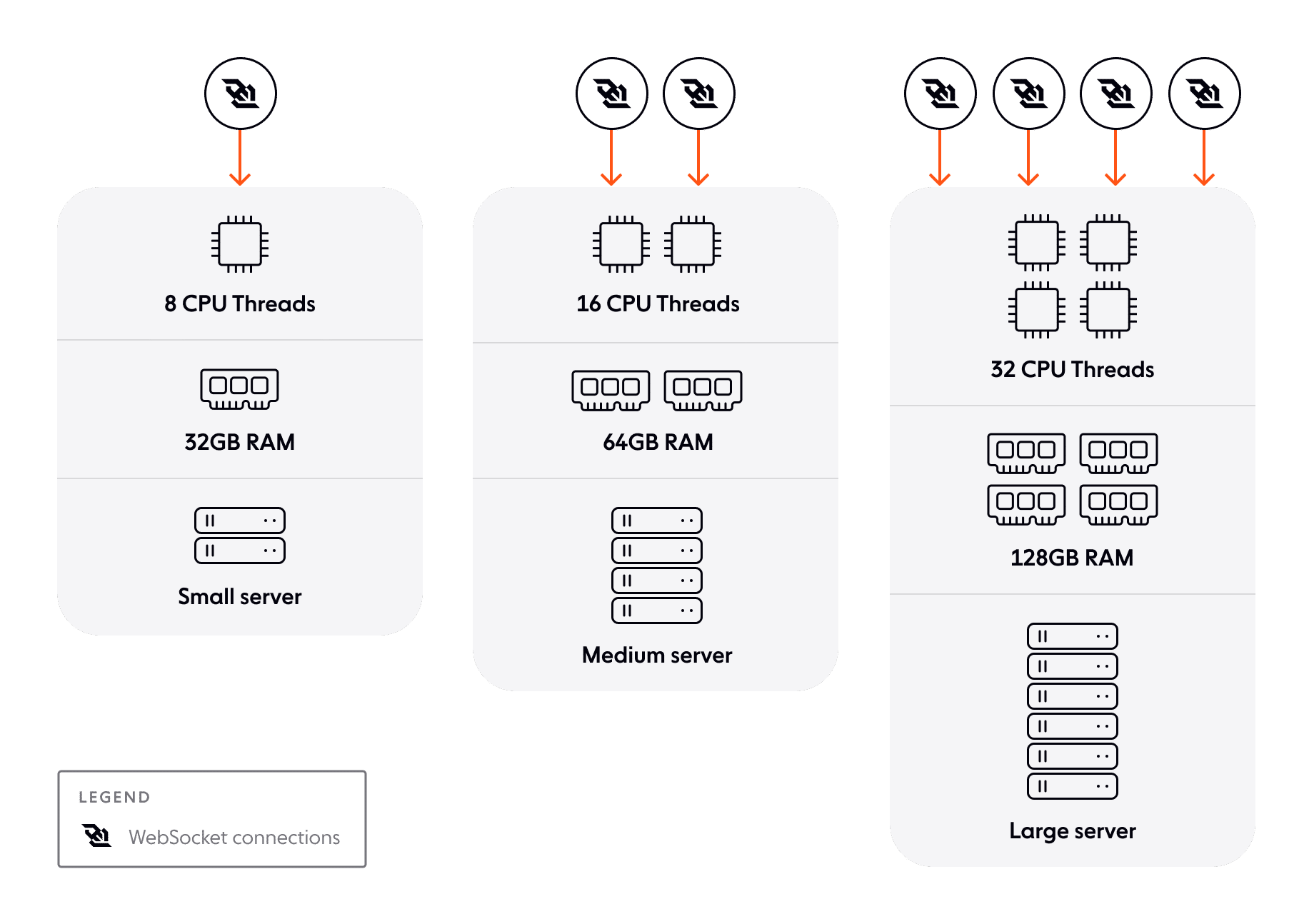
What is horizontal scaling?
Rather than looking for a bigger machine, horizontal scaling–or “scale out”–instead solves the problem by introducing more machines.
In a horizontally scaled architecture, you add and remove servers in response to changes in demand. As an example, you might have a cluster of application servers each running identical stacks. When demand outstrips the capacity of the cluster, you add another application server. When demand reduces, you can remove capacity by spinning down those servers you don’t need.
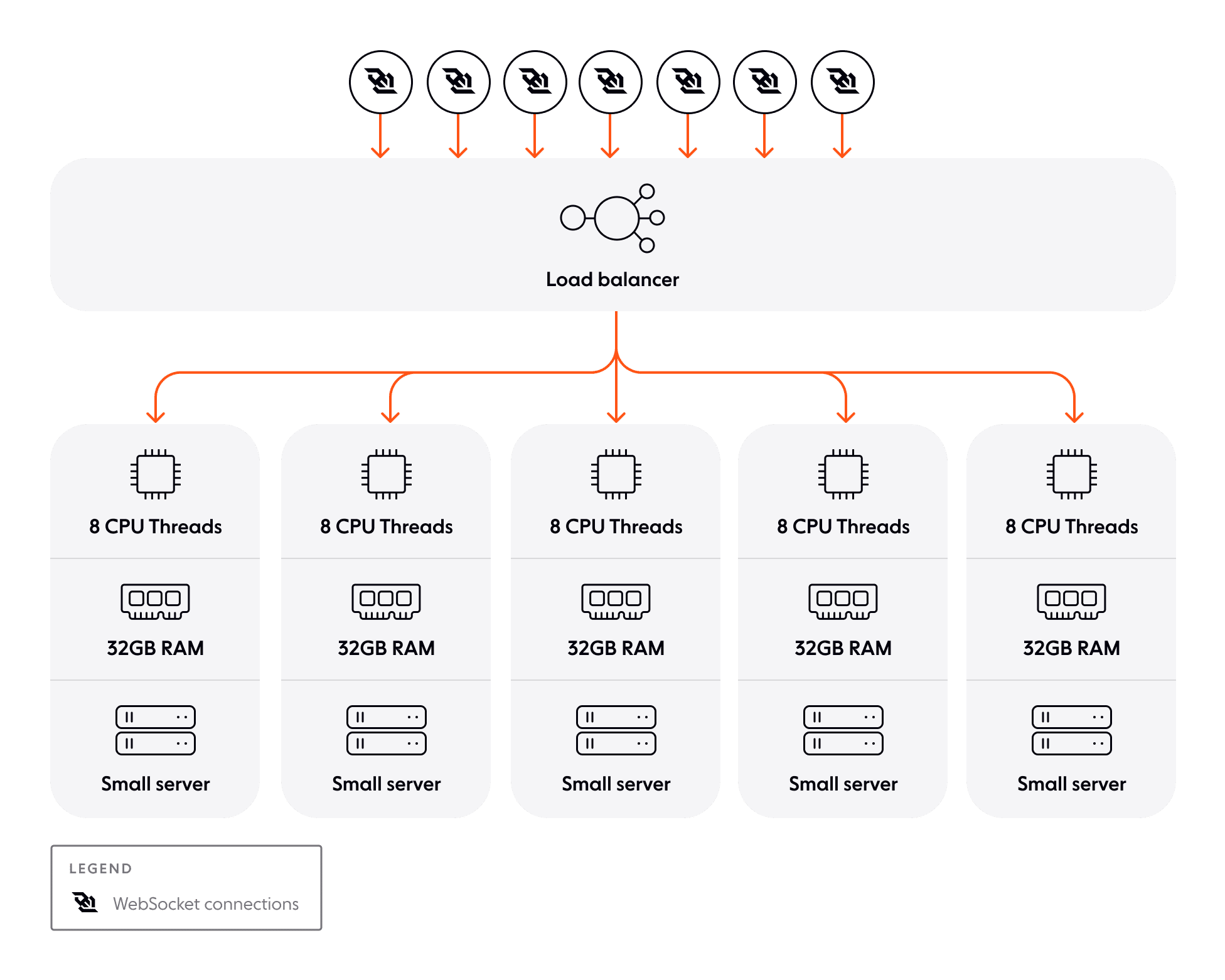
Vertical vs horizontal scaling
Before we look at vertical and horizontal scaling from a WebSockets perspective, it’s worth comparing them as general approaches to scaling.
The first thing to say is that there’s no one size fits all solution. In some situations, vertical scaling is more appropriate than horizontal scaling. And in other situations it’s the other way around. The pros and cons of both approaches suit them to different architectural problems.
Let’s start with the benefits of vertical scaling:
- Simpler to set up and maintain: increasing the capacity of a single application server or database server, for example, requires no special architectural considerations
- Less risk of data synchronization problems: with just one big machine for a particular application or task, there’s a single canonical instance of each item of data
- Potentially faster for some operations: without the need to communicate across multiple instances within a cluster, it might be that some operations are faster
- Lower cost, at first: until you start hitting certain limits, a larger machine is usually cheaper to run than the equivalent capacity split across multiple servers
If you want to emphasize architectural simplicity or you are scaling a stateful service, such as a database, then vertical scaling can be a good option. There are, though, some potential negatives to consider:
- Single point of failure: with just one machine handling a particular task, there’s no fallback
- Technical ceiling: you can scale only as far as the biggest option available from your cloud host or hardware supplier
- Traffic congestion: at busy times, larger applications could saturate the network connection available to a single instance
- Less flexibility: switching out a larger machine will usually involve some downtime, meaning you need to plan for changes in advance and find ways to mitigate end user impact
How about horizontal scaling? Let’s start with the pros:
- Spontaneously accommodate demand: adding and removing stateless instances can be automated and happen within minutes in response to changes in demand
- Higher availability: with less chance of having a single point of failure, you can continue serving end users even if one or more machines go down
- Higher traffic throughput: with multiple instances, you can distribute traffic across more than one network
That makes horizontal scaling well suited to scenarios where you have a highly critical yet stateless service, especially where demand can change unpredictably. But there may be a point where you hit the limits of servers available to you, making horizontal scaling your only option.
There are downsides to horizontal scaling, though:
- More complexity: rather than directing all traffic for a particular service to one machine, you now need to consider how to load balance across multiple stateless nodes
- Higher start-up costs: whether you’re working with VMs or physical hardware, deploying multiple machines will often be more expensive than using a single larger instance
- Data synchronization considerations: making sure that data changes are reflected across all servers is the subject of doctoral theses and many conference talks; the good news is that means there are solutions
So, how does all of this apply to WebSockets?
WebSockets in context
The transformation of the web has been remarkable. What began as a way to link static documents has become the medium through which billions of people share and communicate instantaneously.
Often, these realtime experiences are powered by WebSockets.
Why use WebSockets?
HTTP is stateless. It’s also biased towards a client requesting information from a server. That’s ideal for, “Please serve me a paper on particle physics”. It’s less helpful when it comes to live experiences.

Most human experiences are heavily stateful. Imagine a conference delivered remotely through a web browser. If delegates want to chat, there needs to be some way to keep track of who is in the conversation and what has been said. Not only that but the relationship between client and server is less one-sided than in the HTTP model. When a new message appears in the conversation, it makes more sense for the server to push it to each client rather than for each client to repeatedly poll the server just in case there’s an update.
Over the web’s lifetime, many engineers have created solutions that deliver realtime experiences. Some used proprietary tools. Others bend HTTP almost to breaking point. One technique is long polling, where the client keeps a request open in the hope that the server will respond before the timeout limit hits. Rather than trying to hack HTTP into delivering a form of realtime, the WebSocket protocol is realtime from the ground up. It’s available in all major browsers, is an open standard, and uses the same ports as HTTPS and HTTP.
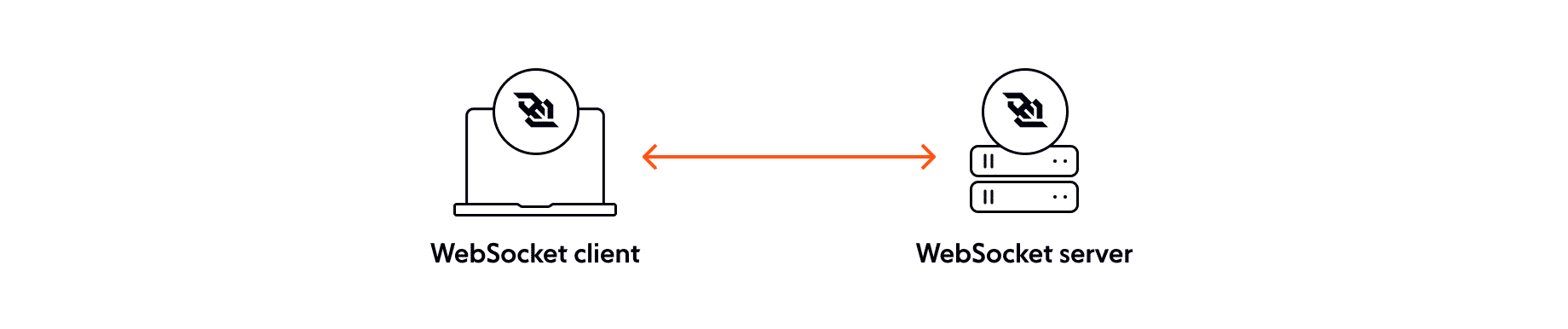
And that’s great for live experiences. But there are some extra considerations to make when scaling WebSockets vs scaling HTTP.
Why WebSockets are more challenging than HTTP in terms of scaling
Plain old HTTP is almost perfectly suited to scaling. Being stateless, every single request is self-contained:
- GET: page X
- RESPONSE: here’s page X
- END
This isn’t news to anyone but it’s useful to remember just how simple HTTP is. Page X could be anywhere. It could be in different places depending on, say, where the client is. So long as there’s a load balancer in between the client and the server, page X could be on multiple servers across a global CDN. And that’s because, in its simplest form, HTTP serves up the same data each and every time and then instantly forgets about the client.
WebSockets are almost entirely about state, though. WebSockets connections rely on the fact that they’re persistent. Scaling WebSockets is a problem of two halves. First, you must maintain persistent connections between your system and thousands or maybe millions of clients. But it’s not just about state between your server(s) and the clients. Most likely, state will be shared between clients just as it would be in our conference chat example from earlier. So the second part of the problem is data synchronization.
The simple solution would be to throw a bigger machine at it, right?
Disadvantages of vertical scaling for WebSockets
Vertical scaling has its pros and cons, as we’ve seen. But is there anything specific to WebSockets that makes vertical scaling a poor choice?
The two key issues are availability and whether your tech stack can actually take advantage of a larger single server.
With some stateful services, such as a relational database, you can fail over to read-only instances should your primary machine go offline. But products built using WebSockets typically require two way communication to make any sense. Vertical scaling piles all your WebSockets connections onto one machine. If it fails, there’s no plan B.
But modern infrastructure hardly ever fails… Even if that were true, your tech stack might not be able to handle ever more threads and RAM. That, in turn, means the potential number of clients connected to the server has an upper bound. Take NodeJS, for example. A single instance of the V8 JavaScript interpreter eventually hits an upper bound on how much RAM it can use.
Not only that but NodeJS is single threaded, meaning that a single NodeJS process won’t take advantage of ever more CPU cores. You could run multiple NodeJS instances but then you’re already introducing some of the complexity of horizontal scaling––you’ll need a load balancer, for example––without the benefits.
Challenges of horizontal scaling for WebSockets
Perhaps, then, a scale-out approach is right for WebSockets. With horizontal scaling, your WebSockets infrastructure could be more resilient and handle many times more clients than a single server ever could.
But horizontal scaling brings with it greater complexity. Let’s look at four of the most common challenges.
Challenge 1: Connection state synchronization
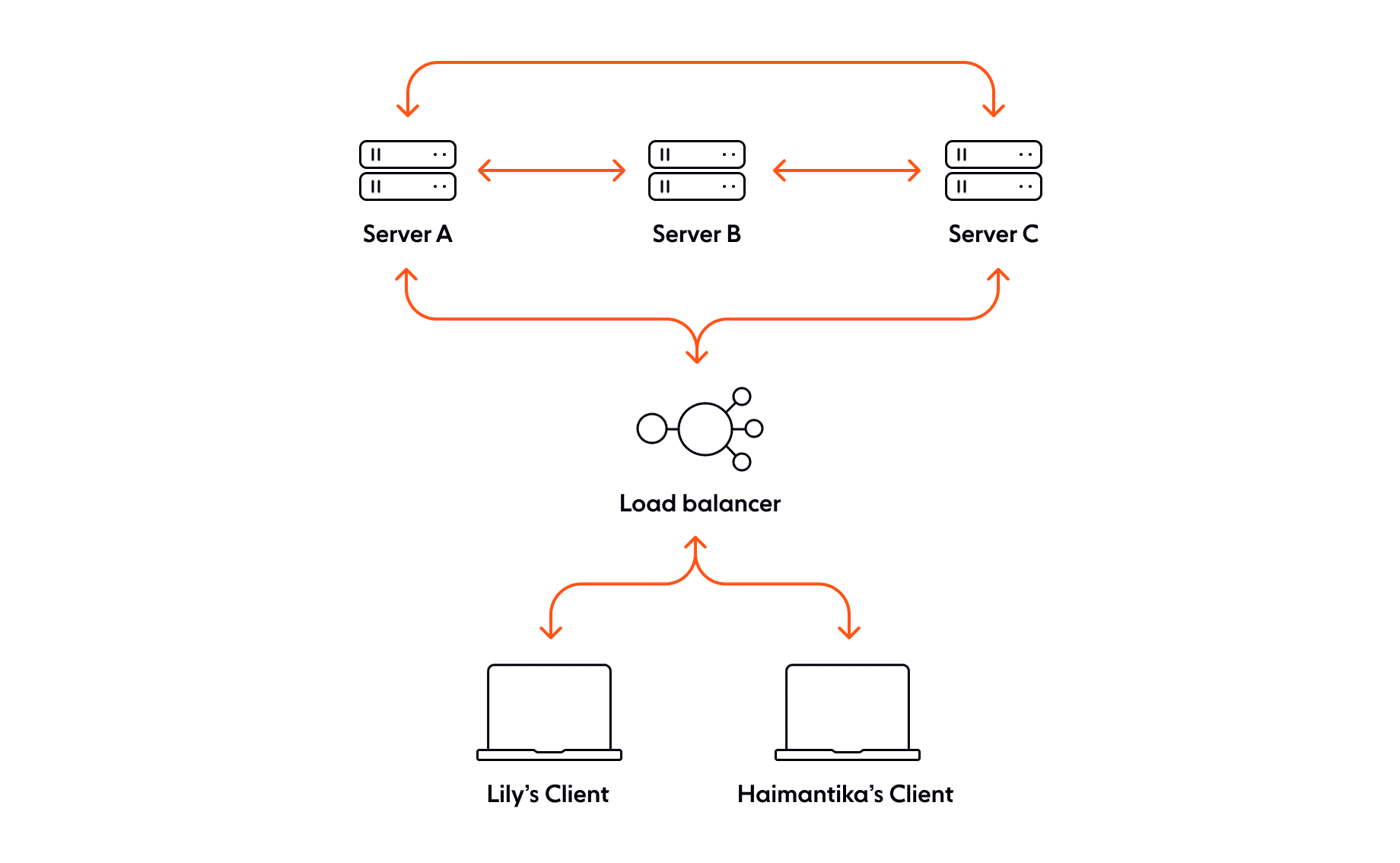
Let’s go back to our conference chat example and say that you’re running three WebSockets servers; we’ll call them A, B, and C. Each server has a persistent connection open to roughly one third of the conference attendees.
Two attendees, Lily and Haimantika, are conducting a private chat. Lily is connected to server A, Haimantika to server C. Haimantika loses her connection. In a modern chat system, we’d expect that Haimantika’s changed connection status would be reflected on Lily’s machine almost instantly.
How do you build your system so that connection state is synchronized in realtime between each of your WebSockets servers? One way might be to track connection state in a data store located elsewhere in your network. Or to avoid relying on yet another system, you might establish a pub/sub communication layer between your WebSockets servers. Both solutions bring with them the additional complexity of implementing and maintaining another tool within your network.
Challenge 2: Data synchronization
Connection state synchronization is just one part of a larger problem. How do you ensure that the right data gets to each client, no matter which server they’re on, in realtime?
The people using a conference chat tool expect that everyone in a chat room will be able to see the messages they send. Each message must go from the client to the server and then out to every client connected to that chat room. How do you distribute messages across the cluster, before pushing them out to clients? What happens to the order of the conversation if two clients send a message at the same time but through different servers? Would clients connected to one server see the conversation in a different order to those connected to another server?
Similarly to synchronizing connection state, the two most likely solutions would be to use a data store elsewhere in your network or to implement pub/sub between servers. Neither comes for free, either in setup or maintenance.
Challenge 3: Load balancing strategy
Distributing traffic across your WebSockets servers requires more thought than load balancing HTTP requests, for example. Selecting an appropriate load balancing strategy will depend on the shape of your traffic, the types of data you’re serving, and so on.
One of the first decisions you’ll need to take is whether sessions are sticky or not. If yes, you save some complexity when it comes to state and data synchronization but you might introduce other challenges.
For example, what happens if a single server becomes unavailable? At its most basic, any clients connected to that server would lose service. So, you’d need to configure clients to request a fresh connection from the load balancer after a number of failed requests.
Or what if clients disconnect in an unbalanced way and a handful of servers become very busy while others sit largely idle? That, and other scenarios where some servers get more than their fair share of traffic, leads to a hotspot in the cluster.
One way to balance load evenly across a cluster of WebSockets servers is to hash the requests using some characteristic of the request. That could be the channel identifier, for example.
This approach, often called consistent hashing, divides a hash space evenly between each node in the WebSockets cluster. If the hash space were an alphabet, server 1 might be responsible for A-F, server 2 for G-O, and server 3 P-Z. Applying the hash function to the request’s channel ID would consistently send those requests to the same server. If one of those servers goes offline, the load balancer can redistribute the hash space among the remaining nodes.
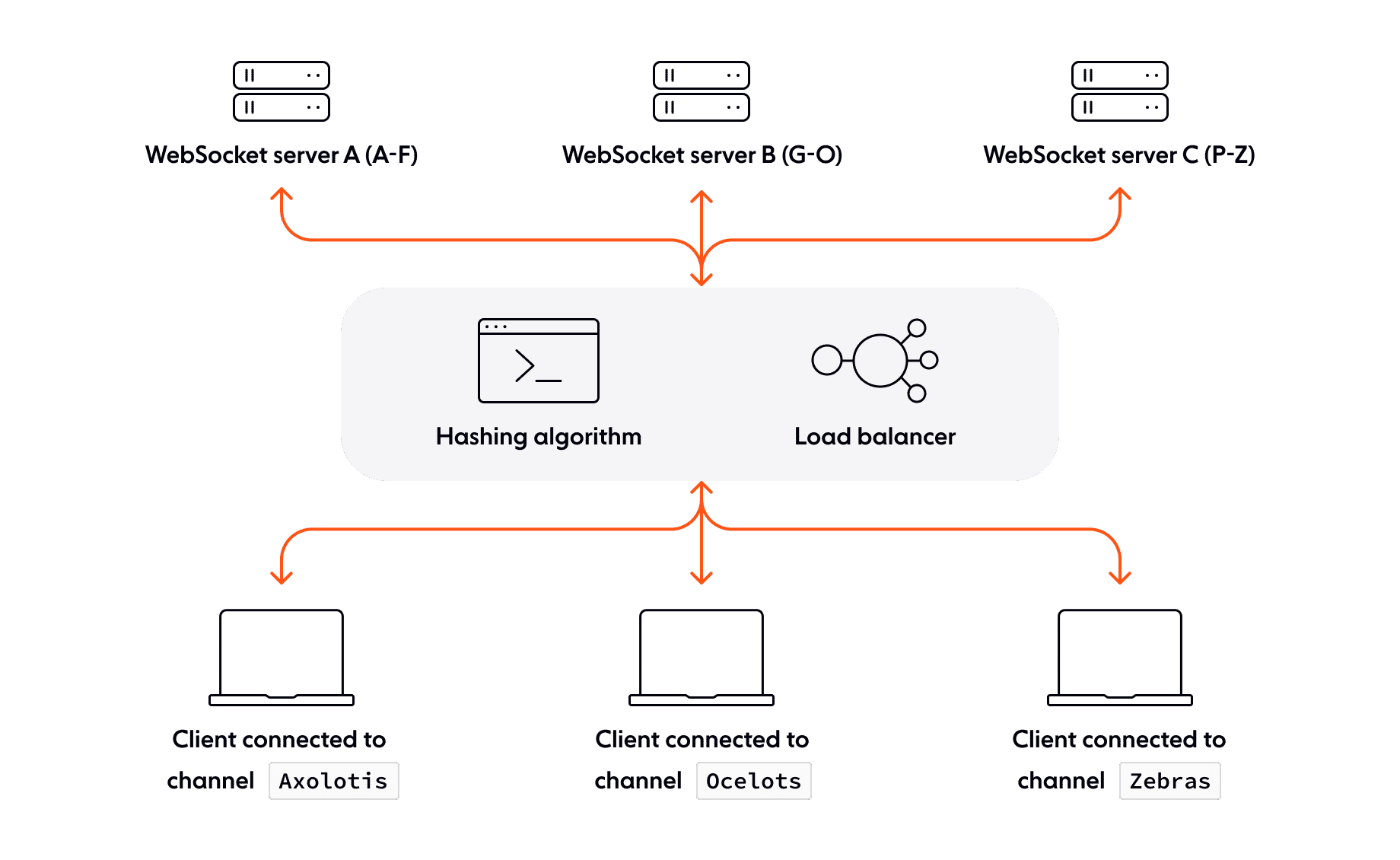
Hashing also helps prevent hotspots in a couple of ways. To go back to our alphabet example, the servers handling the more common letters would be busier than the others. Scrambling the distribution of letters across the cluster would help reduce that risk. Similarly, you can choose to hash on something that is less likely to be influenced by popularity. So, rather than hashing only on channel name you might also hash on the UUID of the client making the request. So long as the outcome of the hash is deterministic, it almost doesn’t matter what you use to create the hash.
Challenge 4: Managing WebSockets connections
Load balancing can do only so much. As part of the bigger challenge of managing connections between clients and your WebSockets cluster, you need to consider what to do if demand on your cluster outstrips its capacity. Load shedding is one way to maintain your service’s ability to serve end users within the expectations you’ve set.
Ideally, you’d add servers to your cluster and thereby avoid the need for load shedding. But reality isn’t always so kind. If you don’t have the ability to scale at precisely the right moment, then you have to choose between chaos or gracefully degrading your service.
Depending on your priorities, the approach you take to load shedding can vary. For example, you might choose some mix of the following:
- Continue to serve those clients connected but refuse new connections with a 503 Service unavailable response.
- Cut existing connections in favor of allowing new clients to connect.
- Continue to accept new connections on the understanding that service will degrade for everyone; this can go only so far before the entire service collapses.
Load shedding enables you to manage demand by managing the volume and/or quality of connections.
Conclusion: Horizontal and vertical scaling a WebSocket solution for production is complex
WebSockets have made it possible for us to deliver rich live experiences to people across the world through their browsers, native apps, and other connected devices. And although they solve many issues, scaling a WebSockets infrastructure is necessarily complex.
If you scale up, or vertically, you might save some initial headaches but you’ll soon hit the limits of what’s possible within a single machine. You’ll also compromise fault tolerance in favor of simplicity.
If you scale out, or scale horizontally, then you future proof your product but you also introduce more work in developing strategies to make your various servers behave as a single service.
Ultimately, horizontal scaling is the only sustainable way to expand the capacity of WebSockets but the extra work of maintaining that infrastructure risks taking your focus away from solving your end user needs. In almost everything we build, we stand on the work of others. Rather than build out your own horizontally scaled infrastructure, one option could be to focus your efforts on creating the unique value of your own offering and using a managed solution to deliver WebSockets on your behalf.
About Ably
Ably is a serverless WebSocket platform designed for last-mile data delivery to web and mobile clients. We make it easy for developers to build live and collaborative experiences for millions of users in a few lines of code, without the hassle of managing and scaling infrastructure.
We offer:
- Roust and diverse features, including pub/sub messaging, automatic reconnections with continuity, and presence.
- Dependable guarantees: <50 ms round trip latency for 99th percentile, guaranteed ordering and delivery, global fault tolerance, and a 99.999% uptime SLA.
- An elastically-scalable, fully-managed edge network capable of streaming billions of messages to millions of concurrently-connected devices.
- 25+ client SDKs targeting every major programming language.
Sign up for a free account and see what Ably can do for you.