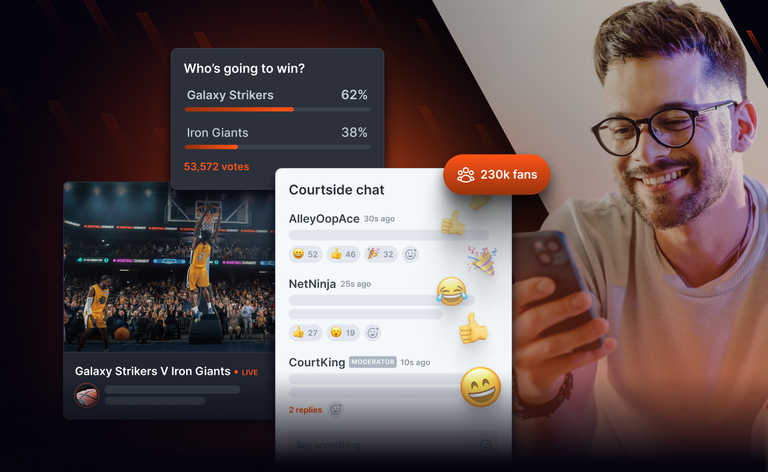
What is audience engagement?
A simple example of online audience engagement could be a livestream with a host and a chat system for audience members to interact with each other in realtime. Other audience engagement solutions include features such as chat or Q&A for participants to communicate while sharing an experience, such as a Watch Party, and polls, quizzes, and leaderboards.
Device and user presence
One aspect of audience engagement is the ability to know who’s participating in a virtual event or a user’s “presence”. Closely linked to presence is the user’s state, for essential functionality such as indicators when someone is typing a message into a chat window, or the realtime location of a device.
Chat
Chat messages are a common way for audience members to interact and send immediate feedback to the host of an online event, such as a livestream. Twitch was an early example; it’s popular with gamers, who stream their gameplay and their webcam feed, so others can watch and comment on gaming in realtime (and leave donations or tips in exchange for a shoutout from the host on the chat channel).
Polls & Q&A
Polls and Q&A are additional aspects of audience engagement. For example, a host may ask a livestream audience, “What’s your favorite flavor of ice cream?” and give participants a short URL to follow, where they can vote online from a list of flavor options. Answers are visualized in realtime as a bar graph, pie chart, or even a word cloud and displayed in the livestream to bring the audience together. This type of poll can cause a surge in responses as the participants submit their votes simultaneously.
Q&A works in reverse; the host of an online event will share a link, and participants can follow it and type in questions and comments to find out more or give feedback in realtime.
Quiz features and gamification
Another way to engage an audience is with a multiplayer quiz, whereby the participants join a live quiz, answer questions, and see their scores on a leaderboard. The quiz could be on a standalone platform or integrated into a livestream, and these are particularly popular in the education sector. Popular products include Mentimeter, Wooclap, Kahoot, Slido, and HQ Trivia.
Participants log into a specific quiz using an invite link, and as questions appear in realtime, they answer on their devices. Their scores are displayed on a leaderboard to add an element of gamification. For fairness, each question has a limited time within which the participants choose an answer. All players need to be sent the question simultaneously (fan-out) with a corresponding surge of responses in return (fan-in) as they complete the challenge before the timer expires.
Realtime updates underpin audience engagement
For the features listed above to be engaging, they need to happen in “realtime”, or near-realtime, which is below the 100 ms threshold of human perception. Technology built on a realtime system uses a series of events, like an asynchronous conversation, rather than the request-response paradigm typical of synchronous communication.
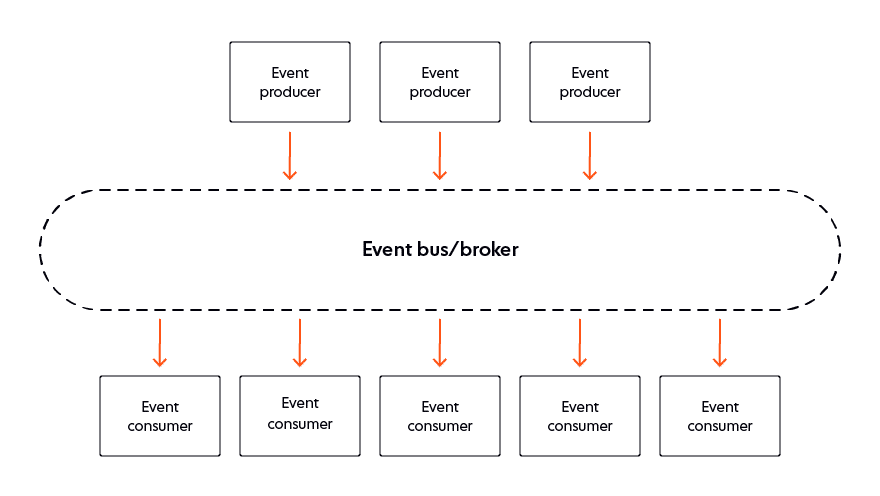
An event-driven architecture serves use cases that need to process data immediately to deliver a satisfactory user experience. It eliminates the need for blocking or constant polling and notifies application code whenever an event of interest occurs.
The publish and subscribe (pub/sub) pattern is typical in event-driven systems. An event producer (publisher) sends event messages when a state change occurs. Event subscribers then consume them. Often, a dedicated broker sits between the publisher and its subscribers, enabling the event producer to offload responsibility to the broker, which delivers notifications at high volume to consumers across different devices and platforms. The broker also records events as messages as they are received from the producer. The event history is retained for a specific period so that subscribers can read event history from any particular point.
Technical challenges of building a realtime architecture
A realtime, event-driven architecture is a distributed system with associated reliability, latency, and bandwidth issues and the unpredictability of the network is a significant challenge.
Message integrity
In an event-driven system, lost, duplicated, or out-of-order messages can have significant consequences. Consider, for example, chat messaging, which relies on a well-defined sequence of messages. If they arrive unordered or are lost, the user experience is flawed.
Lost messages
A user’s connection can drop and reconnect: say if their power fails or a system problem occurs on the network, if they are on the move, or close the chat app and later relaunch it.
Losing messages because of an unstable connection is not acceptable from the user’s perspective. So, when the user reconnects, the app needs to pick up with minimal friction from the point before they disconnected. Any missed messages need to be delivered without duplicating those already processed. The whole experience needs to be completely seamless.
Most event-driven systems use at-least-once delivery. When the broker sends a message to an event consumer, it requires acknowledgment that it was received. If the broker doesn’t receive acknowledgement, it sends the message again to ensure it wasn’t lost on the first send (and will continue to send the message until it receives the acknowledgement). However, what if the message was received and the acknowledgment got lost? Any recent messages are now duplicate copies of the original.
Message duplication and ordering
Message duplication is acceptable if the event-driven system uses idempotent messages, which can be processed multiple times but don’t change the system after the first time. An example of this is programming a heating thermostat. If you type in the exact temperature you require your room to reach before you get home, it doesn’t matter if the instruction is sent multiple times. The thermostat will set to your required temperature, maybe repeatedly, but it will still be the temperature you want. However, if you ask for the heating to be turned up by five degrees and the request is sent more than once, you could be in for a tropical homecoming!
Message duplication in a chat app is almost as annoying for the user as lost messages or those that come out of order. A common approach is to use unique IDs to order messages if they cannot be processed successfully in any order.
Alongside idempotent message types, many event-driven systems use an exactly-once processing guarantee to reconcile issues associated with duplicate messages. A de-duplication process is applied so that previously processed messages are detected and discarded.
Related article: Achieving exactly-once delivery with Ably
Performance
Network latency, which is the time it takes for data to get to its destination, is a critical factor for successful audience engagement. In a large-scale distributed system, latency deteriorates the further it travels between nodes.
High latency can completely ruin live audio communication and video quality. It’s increasingly important to consider performance for a global audience or are hosting users in areas with poorer internet infrastructure.
Low network latency comes from geographic proximity. Data should be kept as close to the users as possible via managed data centers and edge acceleration points. It isn’t sufficient to minimize latency, however. The user experience needs latency variance to be at a minimum to ensure predictability.
There’s also a strong correlation between server performance (processing speed, hardware used, available RAM) and latency. To prevent a congested network and server overrun, it must be possible to dynamically increase the capacity of the server layer and reassign load.
Related article: A global edge network to power digital experiences in realtime
Availability
One particular aspect of audience engagement is the unpredictability of knowing how many participants there will be. For many events, the audience size won't be known until the hours or minutes before the event. The technical challenge this presents is that it is difficult to plan and provision sufficient capacity in any systems that are supporting the event.
A realtime solution for audience participation needs to be highly available to support surges in data and bursts of high volume engagement across the network. When the system does not have the capacity, issues can arise, such as queuing delays, bottlenecks, network congestion, or overall system instability.
Under load, achieving availability and elasticity to meet stringent uptime requirements isn’t just traditional mechanics like failover; it’s about managing capacity. The challenge is to scale horizontally and swiftly absorb millions of connections without the need for pre-provisioning.
To ensure a network can cater to this type of circumstance, monitor metrics such as:
- Global percentage of operating load
- The elasticity and distribution of that load
- The maximum number of connections and throughput
Having ways to automatically and dynamically provision additional capacity when certain thresholds are exceeded is critical to ensure exceptionally high levels of uptime.
Optimization should include minimizing the amounts of data transferred, for example, with a reduced message size that sends only the changes to data (the deltas) rather than entire payloads.
Related article: Availability and uptime - guaranteed
Reliability
Reliability is essential because of the embarrassment caused to a host if the event cannot run, or drops out halfway through, because of a fault. A realtime platform for audience engagement needs to be fault-tolerant so that it can continue to operate even if a component fails.
To achieve fault tolerance, there need to be multiple components capable of maintaining the system if some are lost. Redundancy at a regional and global level ensures continuity of service even in the face of multiple infrastructure failures.
There should be no single point of congestion and no single point of failure.
When one or more components fail, the remaining components need to support the service on their own. It’s essential to understand how many regional failures can be tolerated (for example, the number of instance failures per second). If one region goes offline with failover to another, there needs to be sufficient capacity to absorb the additional traffic, even under peak loads.
Related article: Engineering dependability and fault tolerance in a distributed system
Ably: The four pillars of dependability
To build a system that provides the foundation for realtime audience engagement requires a fault-tolerant infrastructure capable of low latency, scalability, and elasticity, alongside architecture that ensures the integrity of message delivery.

Should you build a custom solution to meet the exact requirements of your business? You could spend several months and a heap of money. And you’d end up burdened with the high cost of infrastructure ownership, technical debt, and ongoing demands for engineering investment.
It makes more financial sense for many companies to pass on the responsibility for scale, latency, data integrity, and reliability to a third-party vendor.
Ably has fault-tolerant, highly-available, elastic global infrastructure for effortless scaling and low complexity. Our platform is mathematically modeled around the Four Pillars of Dependability. We can ensure that messages are reliably delivered at low latency over a secure, reliable, and highly available global edge network. And, there’s zero DevOps overhead, so there is no infrastructure to provision or manage.
The Ably platform abstracts the worry of building a realtime solution to support audience engagement at scale so that you can focus on your core product, prioritize your audience engagement roadmap and develop features to stay competitive.