Introduction
Data travels at the speed of light, which we cannot control (yet), so when you contact a server, the greater the distance from your location, the slower the network performance.
Cloud providers like AWS locate their physical infrastructure worldwide to provide global coverage. Currently, AWS offers 26 regions, including North America, South America, Europe, China, Asia Pacific, South Africa, and the Middle East. Splitting the cloud into regions helps AWS maintain availability and reliability by keeping services self-contained and isolated. Each region is further comprised of “isolated and physically separate” availability zones, which are independent of each other for power, cooling and security, and connected via low-latency networks with built-in redundancy.
As an AWS customer, you choose which regions to use to host your services. That doesn’t mean that users outside of the geographic area can’t access your services, just that when using them, the data and compute power may be half a world away.
Cloud providers offer a range of highly-optimized multi-region functionality such as DNS routing and content delivery network capabilities, using edge computing to shift data and computation to the edge of the network for better response times.
This article describes how an edge messaging infrastructure works across multiple AWS regions with low latency to support live updates and data synchronization.
A system architecture for multi-region pub/sub
Ably is a WebSocket-based pub/sub messaging platform. Publishers send messages on named channels, and clients subscribed to those channels have messages delivered to them. The main realtime production cluster is deployed to seven regions across the US, Europe, and Asia-Pacific, and pub/sub messaging operates between the regions. If you publish a message on a channel in one region, Ably sends it to subscribers in whichever region they are connected to.
Channel activation
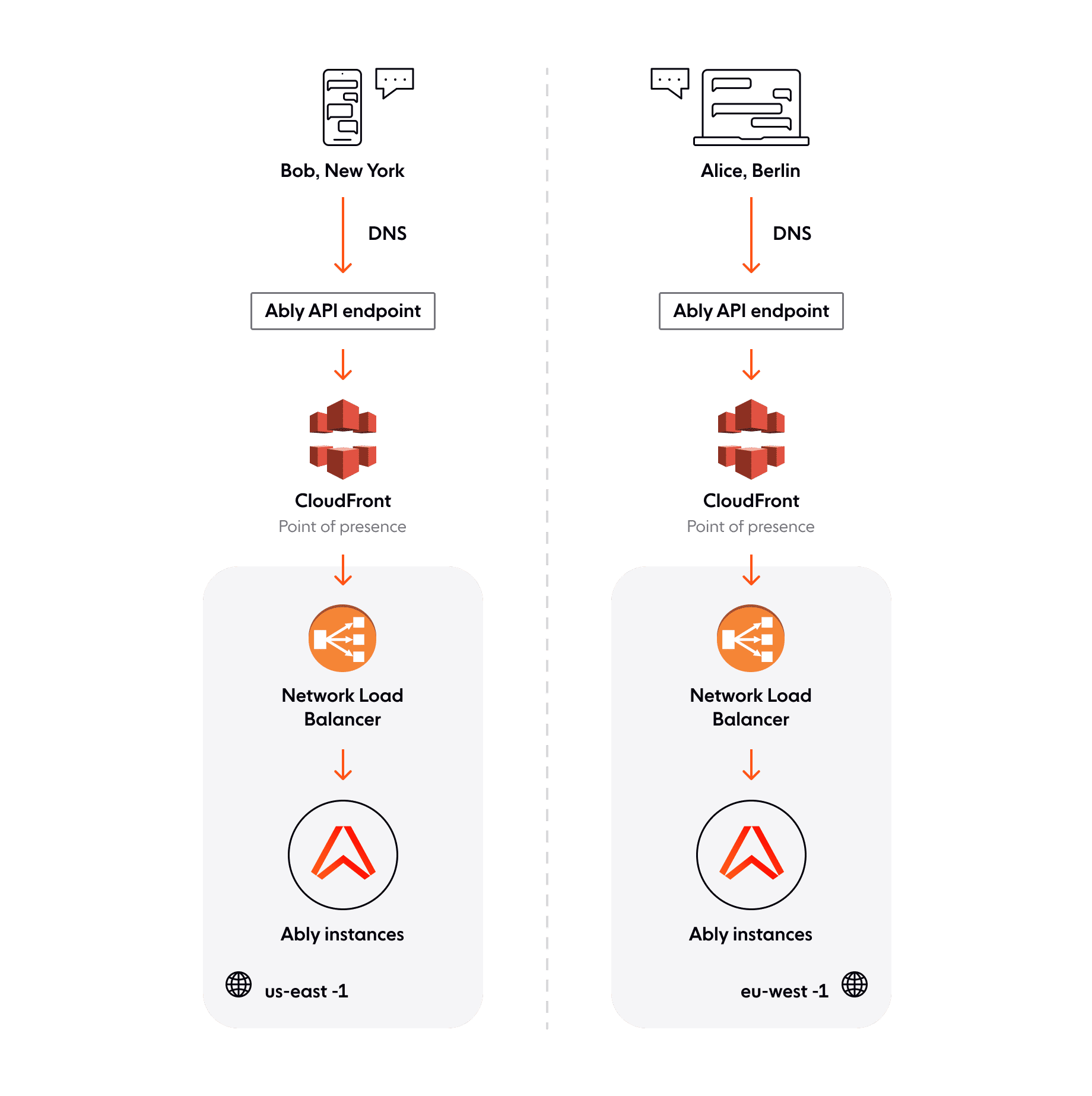
Consider Bob in New York exchanging chat messages with Alice in Berlin via a chat app that uses the Ably client SDK.
When Bob and Alice start their apps, the Ably realtime client library on each device establishes a WebSocket connection to Ably. The client library uses this WebSocket to attach to a channel which is then activated, so by the time Bob and Alice start messaging each other, it is ready for low latency pub/sub messaging. Let’s see how this happens.
Ably is hosted on Amazon EC2 and uses its associated services. The DNS for the Ably API endpoint points to the nearest CloudFront point of presence (PoP) distributions to accelerate traffic.
From CloudFront, latency-based routing moves traffic intelligently from the PoP to the closest network load balancer (NLB) along the AWS backbone (in Bob’s case, the nearest NLB is in the us-east-1 region, for Alice, it is eu-west-1).
The NLB forwards the connection request to Ably’s internal routing layer, where it is then routed intelligently to a frontend EC2 instance.
Routing layer
The router is a reverse proxy primarily responsible for load balancing requests across the frontend instances and routing them more intelligently than the NLB.
Consider connection state recovery when a client’s WebSocket connection breaks and later resumes. The router preferentially directs the request back to the previous frontend process since it still holds the connection state in memory. For HTTP-based requests, i.e., REST or WebSocket requests, the router inspects the request headers to support this connection stickiness. However, there may be occasions where a resumed connection is routed elsewhere, for example, to rebalance the load.
Frontend request processing
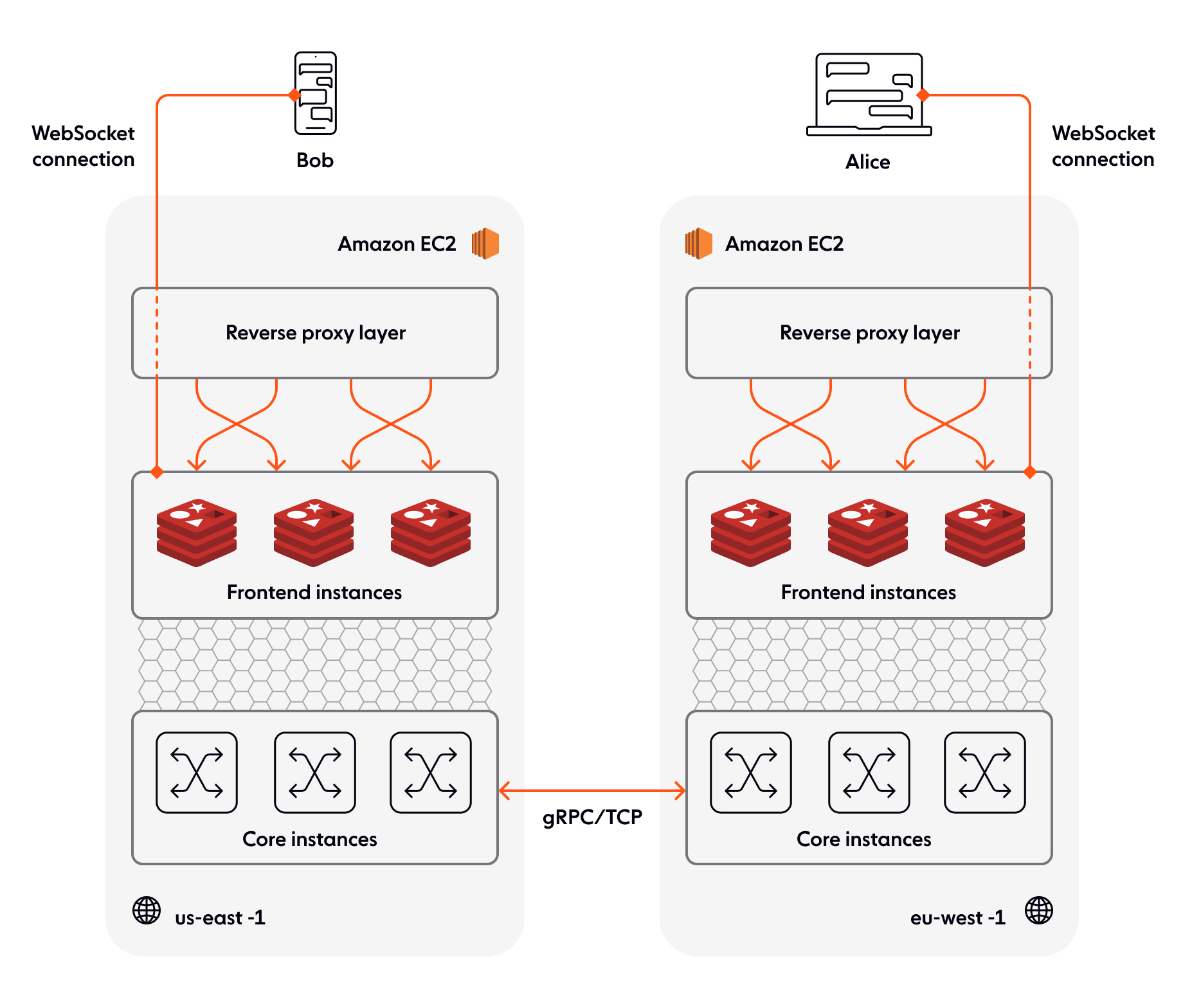
The WebSocket connection between a client and Ably terminates at the frontend instance. The WebSocket connection is both multiplexed, allowing multiple channels to share a single connection, and bi-directional, allowing realtime messages to be sent to and from the Ably service. The frontend is responsible for attaching the appropriate channels: it de-multiplexes and maps them out.
The frontend is also responsible for handling the messages published over the connections and feeding any messages received on that channel to all connected subscribers. Any given message shared between Bob and Alice is associated with a channel, and the frontend communicates with the core instance that manages that particular channel.
Frontend instances need to discover which cores are responsible for which channels. A gossip-based protocol layer ensures that all nodes within the Ably frontend and core share a single consistent view of the network.
Core message processing
The core layer is responsible for channel processing. When a message is published, the core responsible for their channel receives it. It replicates it to multiple instances in at least one other location before acknowledging back to the publishing client.
This ensures that once a message is acknowledged as accepted by Ably, its delivery to subscribers is guaranteed.
| Read more: Message durability and quality of service across a large-scale distributed system |
The core layer also persists data to longer-term storage (message history) from EC2, and performs any pre- and post-processing on messages.
The core manages all associated channel and system states, such as presence and channel state across all regions.
Within a single region, between the frontend and the core instance that maintains a particular channel, there’s a bidirectional gRPC connection to transfer metadata and lifecycle events and a TCP connection between the frontend and core instances for message data transfer.
Peer-to-peer channel communication
Channel state is synchronized between regions to provide a single global service and maximize availability in case of cross-region network disruption. Cores are responsible for subscribing to other regions and making those remote messages available to local frontends.
A channel running in a region needs to know in which other regions it is already active so it can communicate with them. When it first becomes active in any region, the channel employs a peer-to-peer discovery procedure, interacting with the calculated channel location in other regions, to determine the channel activity in each other region. It then starts a gRPC connection to any equivalent channels that are active in other regions, and existing active channels set up subscriptions back to the newly active channel for bidirectional communication.
| Read more: Channel global decoupling for region discovery |
The transfer of messages between the channel in region eu-west-1 to the same channel in region us-east-1 is also peer-to-peer. It does not need to transit through or be coordinated by, any central coordinator. In the case of the channel for Alice and Bob, there will be bidirectional peer-to-peer communication between their regions.
Ably functions as a federated system where each region operates independently, but the channel state is synchronized between regions to provide a single global service. This brings some challenges for features such as presence and idempotency because state is maintained independently in each region and needs to be synchronized for consistent replication.
Benefits of a multi-region solution
Performance
Ably is engineered to mediate peer-to-peer interactions and reduce latency to the bare minimum. While not an edge service with hundreds of points of presence near client devices, Ably is globally distributed and much closer to clients than a conventional single-region service. When two clients connect to Ably, their interactions pass from one region to another peer-to-peer without the overhead of a central coordinator.
The latency of messages between publisher and subscriber when transiting through our global network is as follows:
- Round trip latency within a datacenter: < 30ms for the 99th percentile (measured from the point a message arrives from a publisher at an Ably datacenter to the point it leaves en route to a subscriber within the same region).
- Round trip latency from any of our 700+ global points of presence (PoPs) that receive at least 1% of our traffic: < 50ms for the 99th percentile (measured at the PoP boundary within the Ably access network, which will be closer than a datacenter).
- Mean roundtrip latency: < 99ms from all 700+ PoPs (this is the transit latency for all PoPs, including those that are remote and rarely used).

Reliability
With distribution across multiple regions, it's possible to ensure fault tolerance by combining redundancy with a set of mechanisms to detect and remediate failure. We use standard mechanisms such as a load balancer to distribute connection requests and load in combination with our own approach for channel and connection state management.
| Read more: Engineering dependability and fault tolerance in a distributed system |
Find out more
Performance and reliability are crucial to the realtime user experience of any online app or service. The four pillars of Ably engineering enable us to guarantee that our customers can build and deliver a predictable experience to their users. For more information, look at the Ably website for case studies and articles about the platform’s benefits and solutions, or get in touch with us with any questions.