A network load balancer (NLB) distributes incoming traffic across multiple targets, automatically scaling the workload to ensure low latency and high throughput.
In this article, we describe how we load-test the Ably workload, which is characterized by high connection counts and high rates of new connection establishment. We offer a highly-scalable and elastic solution so we routinely load test to explore scalability limits and to prove our merit. We hit two limits in using AWS network load balancers: one documented and one undocumented, and we'll describe how to work around the limits to ensure dependability.
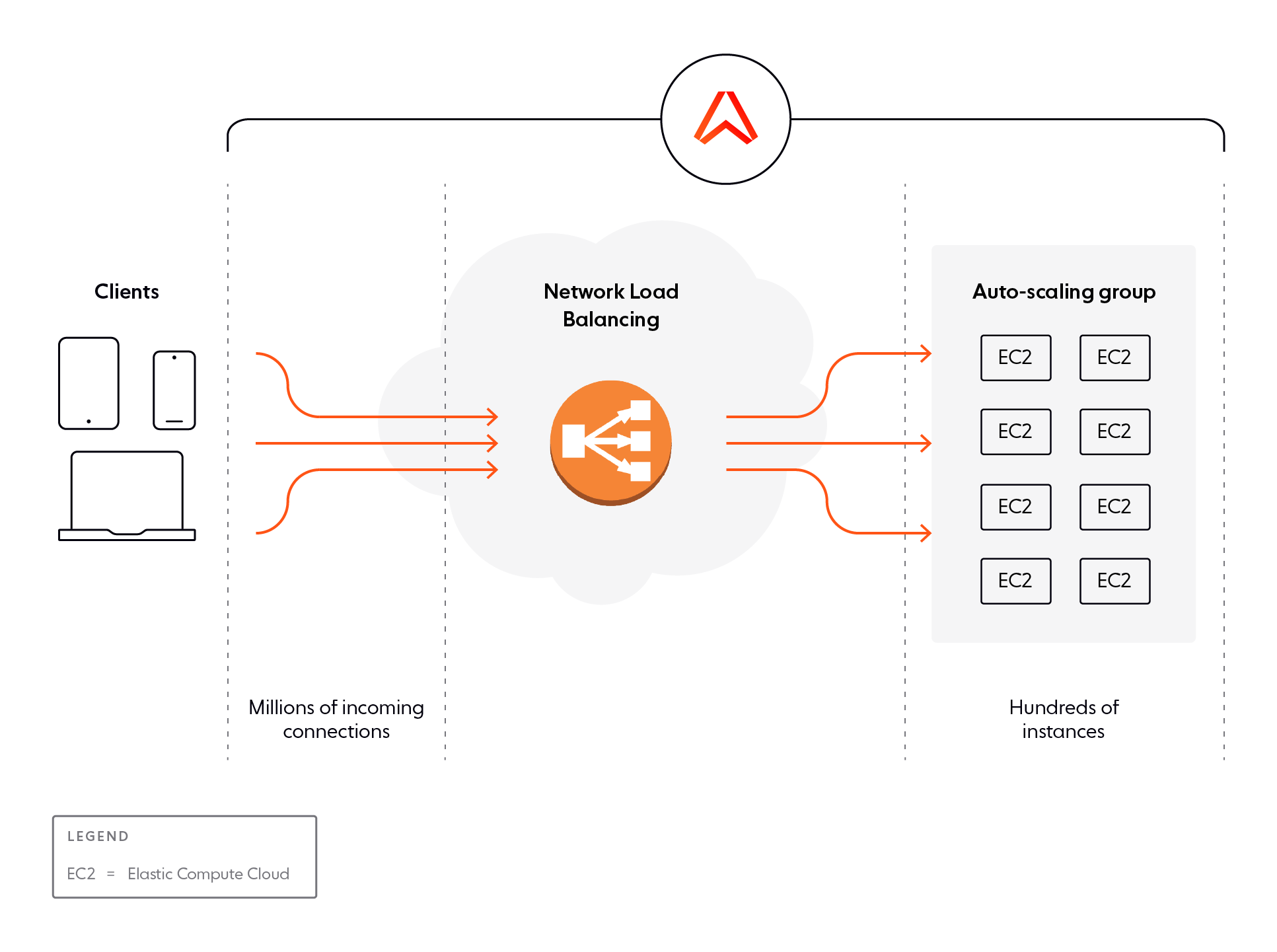
Distributing connections among available AWS instances is the role of one or more load balancers. Each load balancer exposes a single network endpoint externally and forwards individual requests to frontend server instances managed in a pool that scales to match the load.
Load balancers can provide additional functionality. For example, they can perform health checks on the upstream server instances so that requests are forwarded only to healthy instances. They can also terminate TLS, or provide application-level proxying, which can be the basis of other functionality (such as sticky routing based on HTTP cookies).
AWS Elastic Load Balancers
From the earliest days of the EC2 service in 2009, AWS provided an Elastic Load Balancer (ELB) component.
Having this functionality available as a service is attractive because it takes care of one of the difficult scaling points of service architecture. Instances upstream of the load balancer can be stateless and only need to be concerned with handling individual requests without the need for coordination or contention with other instances. A potentially infinitely scalable service can be constructed with a small set of primitives: an elastic load balancer and a scaling group of server instances.
At Ably we used classic ELBs as a core element of the architecture of our AWS-hosted service after a study of AWS's performance and scalability characteristics.
AWS Network Load Balancers
AWS introduced Network Load balancers (NLBs) in 2017. Elasticity of the NLB itself is intrinsic to the NLB service; these are advertised by AWS as scaling effortlessly to millions of requests per second, and being able to automatically scale to meet the vast majority of workloads.
An NLB is a Layer 4 device that can terminate incoming TCP/TLS connections if required. It determines which of the upstream targets to forward it to and ensures there is an onward TCP connection.
The available targets are managed by the NLB as a target group. Elasticity of the upstream target pool is possible by adding and removing targets from the target group.
Scale and elasticity
Our pub/sub messaging service often scales to tens of millions of concurrent, long-running client connections (instead of connect/reconnect polling).

Workloads are characterized by high connection counts, and high rates of new connection establishment. Traffic on individual connections ranges from low (single digit messages per minute) to hundreds of messages per second.
Elasticity is a key characteristic of our loads: applications from live events, sports, audience participation, and social networking experience load fluctuations of multiple orders of magnitude. It’s why our customers outsource connection management to use, and we, in turn, look to a scalable cloud solution.
Keen to improve the scale and elasticity on offer, we migrated the Ably infrastructure to use NLBs. In many respects, NLBs worked very well initially and certainly eliminated the “warming” issues we had always experienced with classic ELBs. However, in testing the scalability of NLBs, we found several substantial challenges.
Load testing AWS NLBs
We routinely load test the Ably service to explore scalability limits and to prove our merit when being competitively evaluated by potential customers.
We use a derivative of the Boomer load generator for Locust for much of our load testing. This enables us to run multiple thousands of load generator processes and coordinate the load projected towards a test service endpoint for various use cases. A basic routine test involves steadily ramping up the number of connections to verify we can support a given client population.
Limit 1: maximum target group size
The first NLB limit we hit was a limit on the number of targets (i.e. frontend server instances) that can belong to a target group. The AWS NLB documentation explains the existence of a number of quotas and explains, “You can request increases for some quotas, and other quotas cannot be increased”.
In direct discussion with AWS, it became clear that, due to architectural constraints, some of the quotas are simply hard limits to be exceeded at one’s own risk. One of these is the maximum size of a target group, which is 500. This places a strict and immediate cap on the size of a system targeted by a single load balancer.
There are various strategies to deal with this limit.
Vertical EC2 scaling
If the server software stack can make use of larger server instances, then it is clearly possible to increase the capacity of a system, with a constraint on the total target group size, by increasing the capacity of each target.
The limitations of this approach are the following:
- You can only scale so far with vertical scaling: once you have reached the largest instance type, you cannot scale any further.
- The server software stack might be unable to take advantage of larger instance types transparently. In particular, server technologies such as NodeJS are unable to take advantage, transparently, of higher numbers of CPU cores. Running multiple server processes on a single server instance can help, but then there needs to be a further mechanism, such as another intervening reverse proxy to load balance traffic among the server processes on the instance.
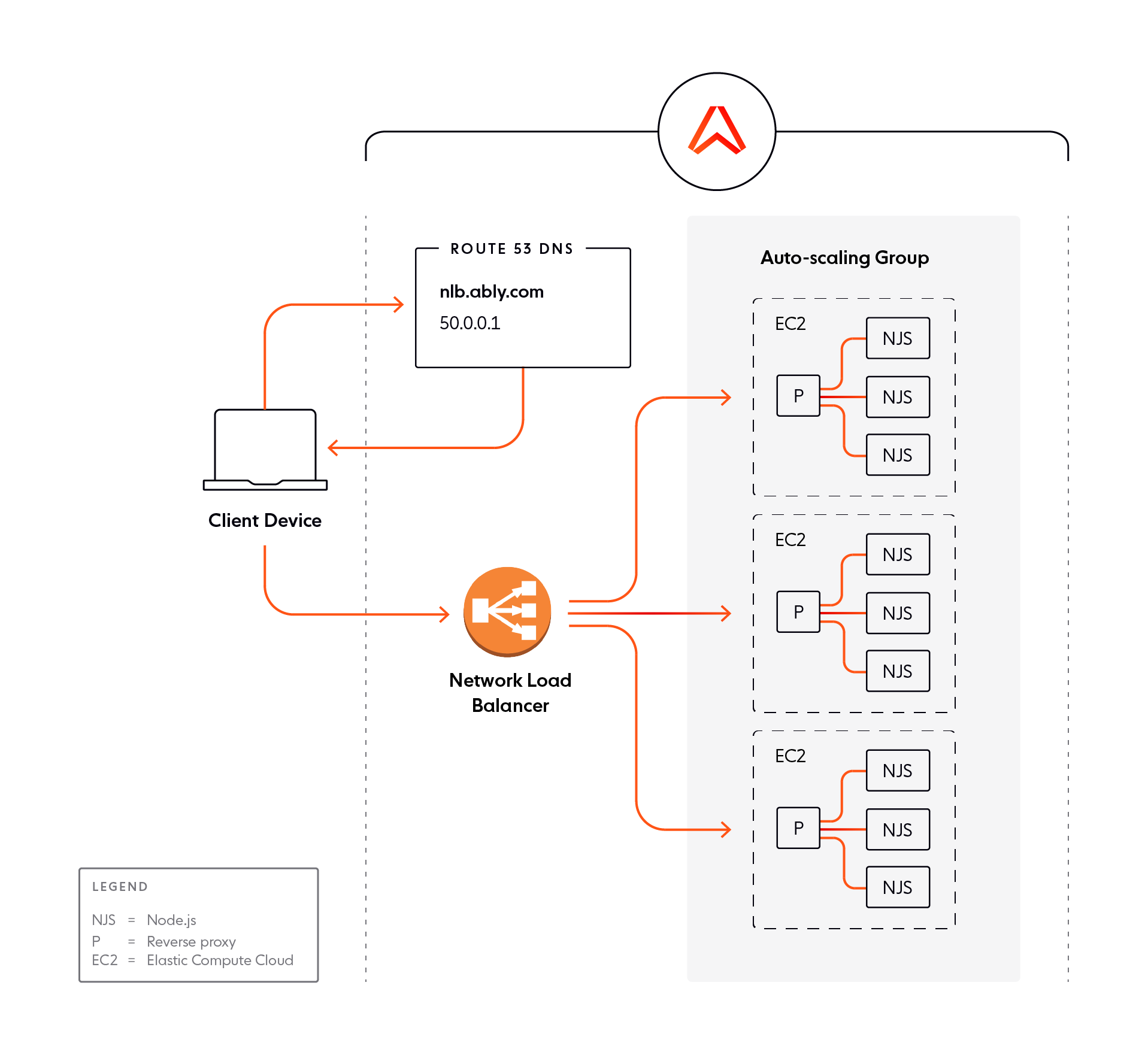
Multiple, sharded NLBs
An alternative approach is to have multiple NLBs beyond the 500 target group limit and to shard traffic between them. Each NLB then targets an independent scaling group of server instances. We can route traffic to multiple NLBs by creating a DNS-weighted set; the policy can route requests to all the NLBs, for example, by distributing them in a round-robin manner.
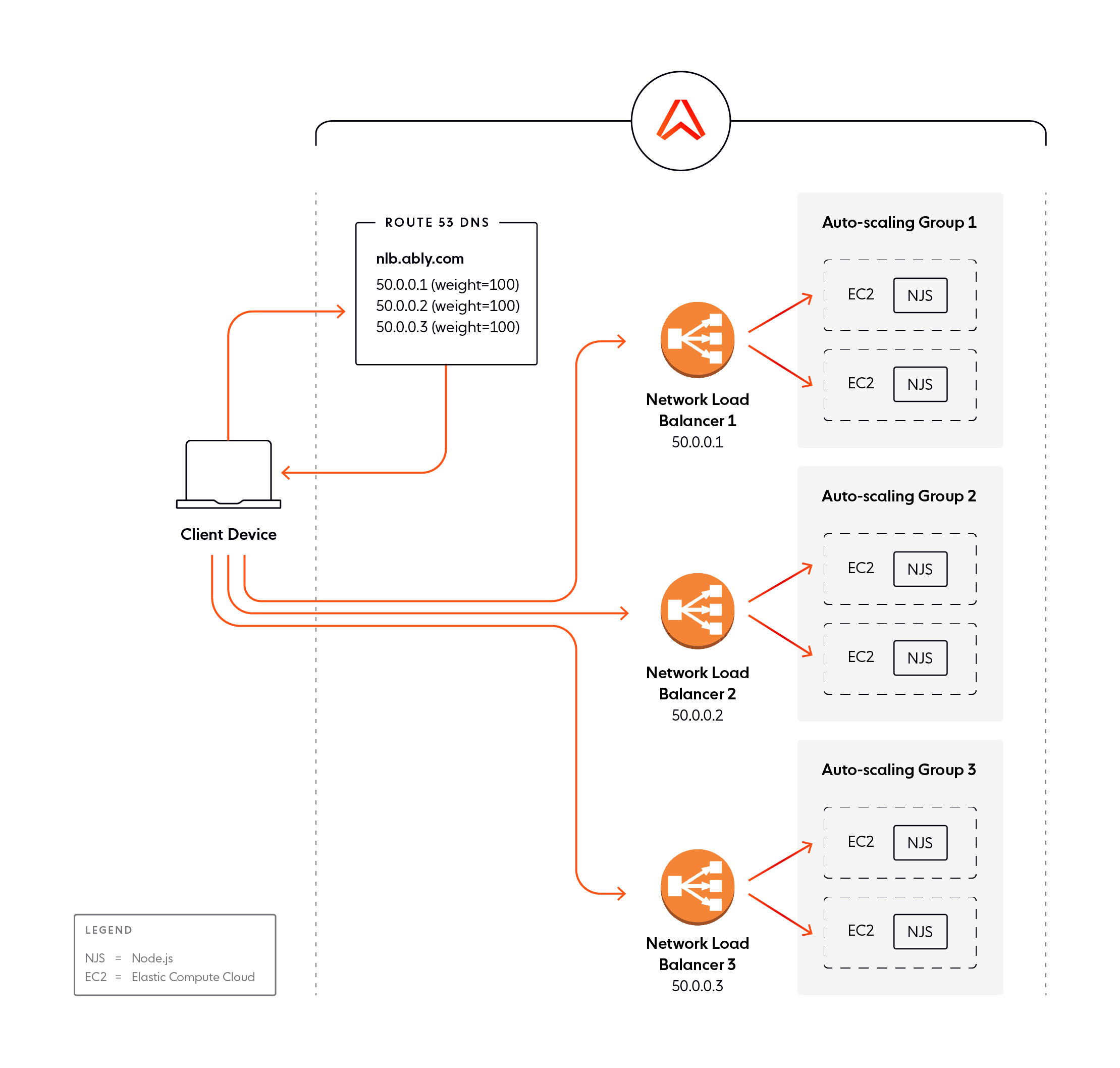
The limitations of this approach are:
- Increased cost – having multiple NLBs means paying for multiple NLBs.
- No elasticity – the individual target groups can be elastic, but the number of NLBs itself cannot be elastic: the set of NLBs needs to be sized statically for the maximum anticipated load. It then remains fixed, even when the load would not have required additional NLBs. This exacerbates the cost issue above.
- The number of NLBs needs to be a multiple of the number of Availability Zones (AZs) targeted. As such, if you want to have instances spread across 3 AZs, you need a multiple of 3 NLBs.
Having multiple NLBs and sharding the traffic between them is the only way to scale beyond the fixed target group size limit, so we have adopted this approach despite the challenges above.
Limit 2: Connection drops
A typical load test has a continuously growing set of subscribers targeting a single endpoint while monitoring various performance parameters such as connection time and message transit latency. During our tests, we occasionally found that most or all currently established connections would suddenly drop for no apparent reason.
This specific problem occurred consistently when the number of established connections through a single NLB reached 2 million: connections dropped, and reconnection attempts failed for a period of several minutes before the NLB re-admitted traffic.
Increasing other parameters of the configuration had no impact, whether it was the number of server instances, or the number of client instances (so there were fewer client connections per instance).
It seemed impossible to maintain that many connections stably through a single NLB. We discussed the issue with AWS, and it was confirmed that this is also due to architectural limits in the NLB design, which limits the number of connections that can be maintained.
Unlike the target group limit, this constraint is not stated explicitly. There is no warning when this limit is reached. Passing the stable capacity of the NLB just results in tens of thousands of existing connections dropping as the NLB crumples under the load.
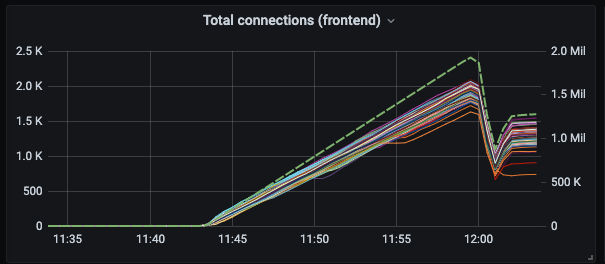
Unfortunately, there didn’t appear to be a clear point at which this occurs. Under 1 million connections, things were generally more stable, but mass connection drops would still occasionally happen: in these cases, up to a third of all connections dropped. It was unclear when to deem the NLB reliable.
AWS’s advice was to attempt to support no more than 400K simultaneous connections on a single NLB. This is a more significant constraint than the target group limit. If each server instance is handling 10K connections, that limits each NLB to no more than 40 fully-loaded server instances.
Not only does this impact cost, but it also imposes a significant elasticity constraint. Absorbing 1 million unexpected connections on demand is no longer possible if sufficient NLB provisions aren’t made ahead of time.
Even below the 400K connection threshold, we would occasionally see situations where some 20% of the connections spontaneously dropped. Those connections can successfully reconnect, but nonetheless, this causes unwanted latency for the client, and more work for the backend system.
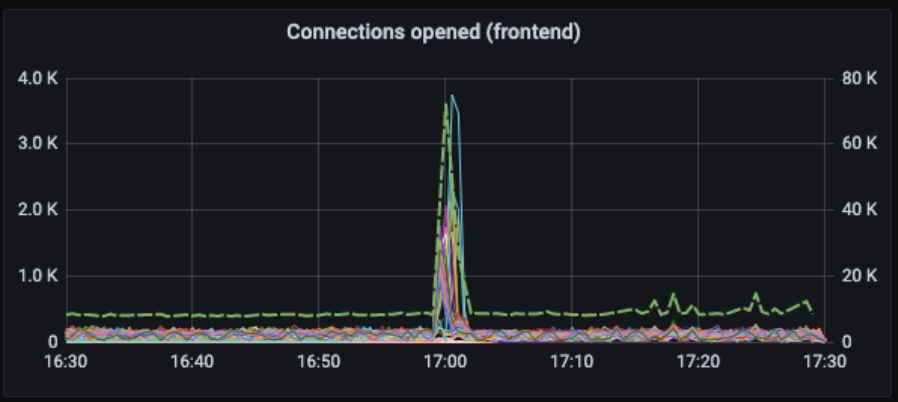
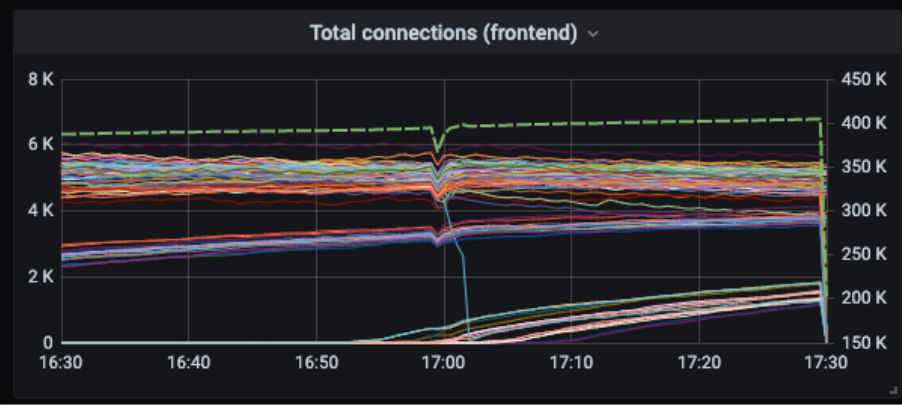
Working within the limits of AWS NLBs
From our experience, NLBs do not yet fully handle the scale we need in terms of requests per second and automatic scaling. We can use NLBs to achieve the workloads we need, but only by adding complexity to our architecture.
The limit in the upstream targets that a single NLB can address means we have to use multiple NLBs at higher scale, pushing horizontal scaling further out toward the client, with the client’s address resolution playing a part in the load balancing process.
However, achieving effective elasticity of higher scale systems requires not only the ability to handle a large number of connections but also connection stability at those higher counts.
It is possible to handle single-digit millions of connections with a small fixed number of NLBs. These configurations can be effectively elastic since the principle resource pools – the frontend server scaling groups – are fully elastic. But to build systems that scale up by a further order of magnitude, up to 100 million connections, the NLB proposition strains under serious testing.
In our experience, anything over 200,000 connections per NLB becomes a challenge. Many of our individual customers require much greater scale, and on aggregate, Ably certainly needs massively greater scale.
Our goal is to provide truly scalable connectivity for our customers’ applications. Achieving that scale dependably is an ongoing and significant engineering challenge. We make it our job to take care of this kind of issue so our customers don’t have to.
Ably has scale covered. We have confronted difficult real-world systems engineering problems such as horizontal scalability, elasticity, and global distribution, so our customers don’t have to.
To learn more about how we can help you simplify engineering, reduce DevOps overhead, and increase development velocity, talk to our Technical Experts.