

There’s unprecedented demand for multiplayer collaborative products. That is, products with features that support realtime, shared live and collaborative experiences between users. There’s been explosive growth in the unified communications and collaboration (UC&C) sector through the pandemic, but collaboration isn’t just about the Zooms and Slacks of the world.
Remote-first and hybrid workplaces are increasingly common and have fueled growth in apps that provide a shared live experience for project collaborations where users are not physically co-located. Taking an application that’s designed to be single-user and screen-sharing it with a collaborator over a conference call could at best be viewed as entry-level collaboration. The growth of collaborative experiences is highly competitive.
On a technical level, this sounds terrifying. Reading about Figma’s approach to multiplayer and the Google Docs architecture, it’s fair to say both seem pretty infrastructure-heavy. It used to be possible to keep customers happy and productive without hiring a legion of SREs to provide round-the-clock infrastructure support. What happens now?
This article outlines a suggested system architecture to focus teams on building the features that differentiate their product from competitors using the skills and techniques they already have. We’ll introduce a serverless WebSockets realtime messaging platform, which can be relied upon to provide highly available, scalable data synchronization between clients, and high-level abstractions such as user presence and connection management.
The architecture suggested in this article enables you to retain familiar design principles and components yet achieve much more ambitious functionality. It explains how to build on a high-performance serverless WebSockets solution rather than recruit additional teams of skilled infrastructure specialists.
The problem space
A wide variety of the typical SaaS applications we’re using and working on every day were originally designed for a single-user experience. That might include document editing, drawing, presentations, spreadsheets, CRMs, accounting, note-taking, task management and much more. In this setting, the state of the client can be reasonably considered transient or unsaved until it’s sent back to the server.
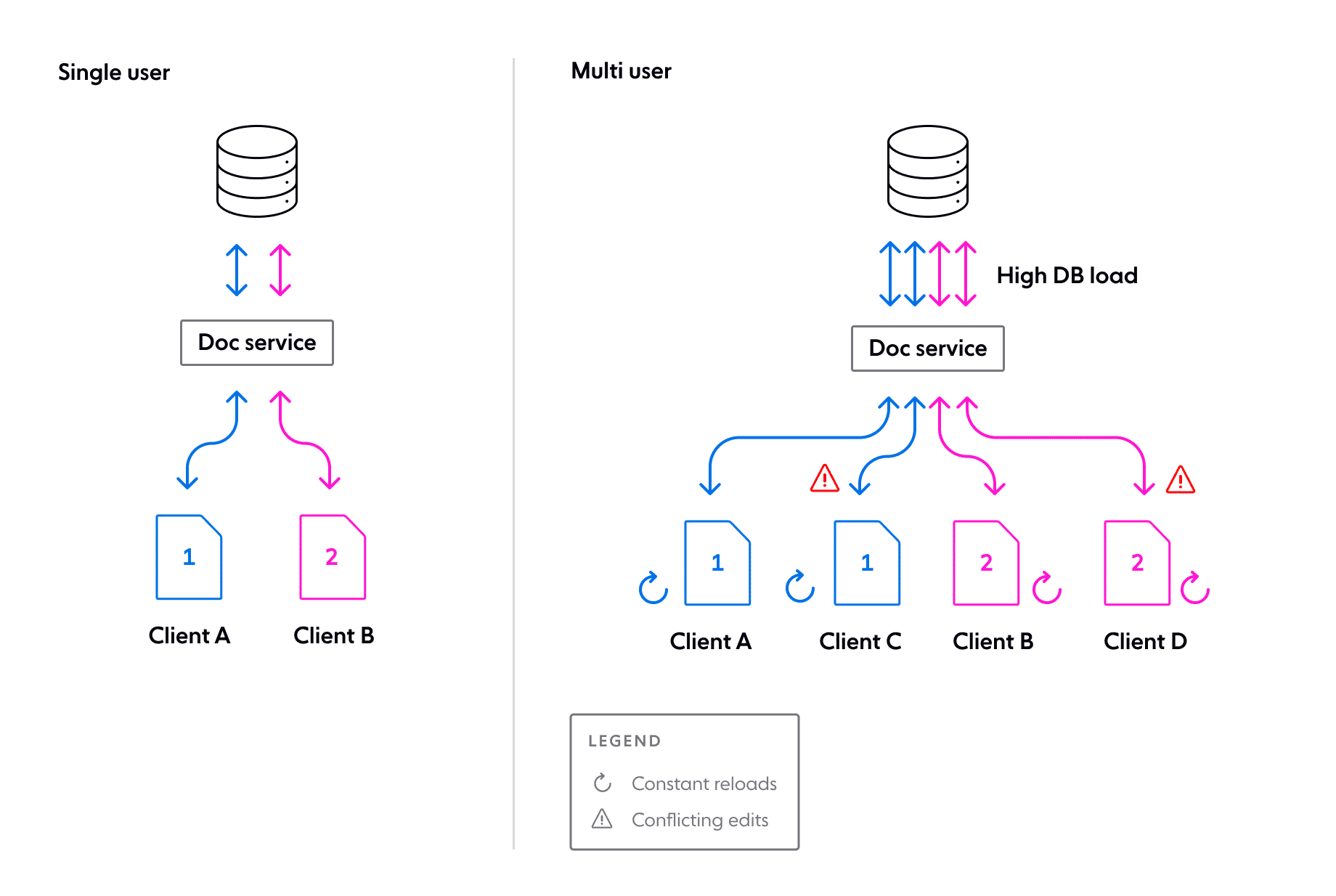
What if we needed to take an application like this and add features to make it a shared, live and collaborative experience for multiple users? Suppose the users want to view the same document, drawing or presentation and make edits together, seeing each other’s changes appear instantaneously.
You can probably predict that it’s not going to be trivial, but let’s enumerate some of the challenges ahead should we attempt to evolve an architecture for a mature, single-user application to extend it for multi-user collaboration.

Those considerations are just to make it work at all. Making it work well is harder still. Users may talk over video chat while working together, so latency requirements will need to be low, even for globally distributed users. For business-critical applications, high availability is another standard requirement. Delivering on these expectations can be extra challenging once realtime collaboration is part of the feature set.
The architecture proposed in this article is all about removing that challenge, hopefully giving your backend developers a chance to breathe!
Serverless WebSockets
One option is to consider is to make use of a serverless WebSockets platform. Engineering leaders will undoubtedly want to consider whether it makes sense to build their own solution or buy a hosted option, like Ably. The State of Serverless WebSockets report contains data from a survey of over 500 engineering leaders about their experiences building their own solutions. Notably, 80% of such projects took at least 6 months, and it’s reasonable to expect that striving for the data integrity, performance, and reliability targets needed to deliver a competitive and smooth user experience would require an even greater commitment in terms of time and resources.
Ably offers reliable, low-latency pub/sub messaging that can enable serverless client-to-client communication. The core concept in this design is to move some of the “smarts” from server to client, enable clients to communicate with each other directly, and make the backend role a little more passive - at least as far as its involvement in collaborative features is concerned.
The diagram below shows the components involved and the role each play. We’ll go through each component in more detail later.
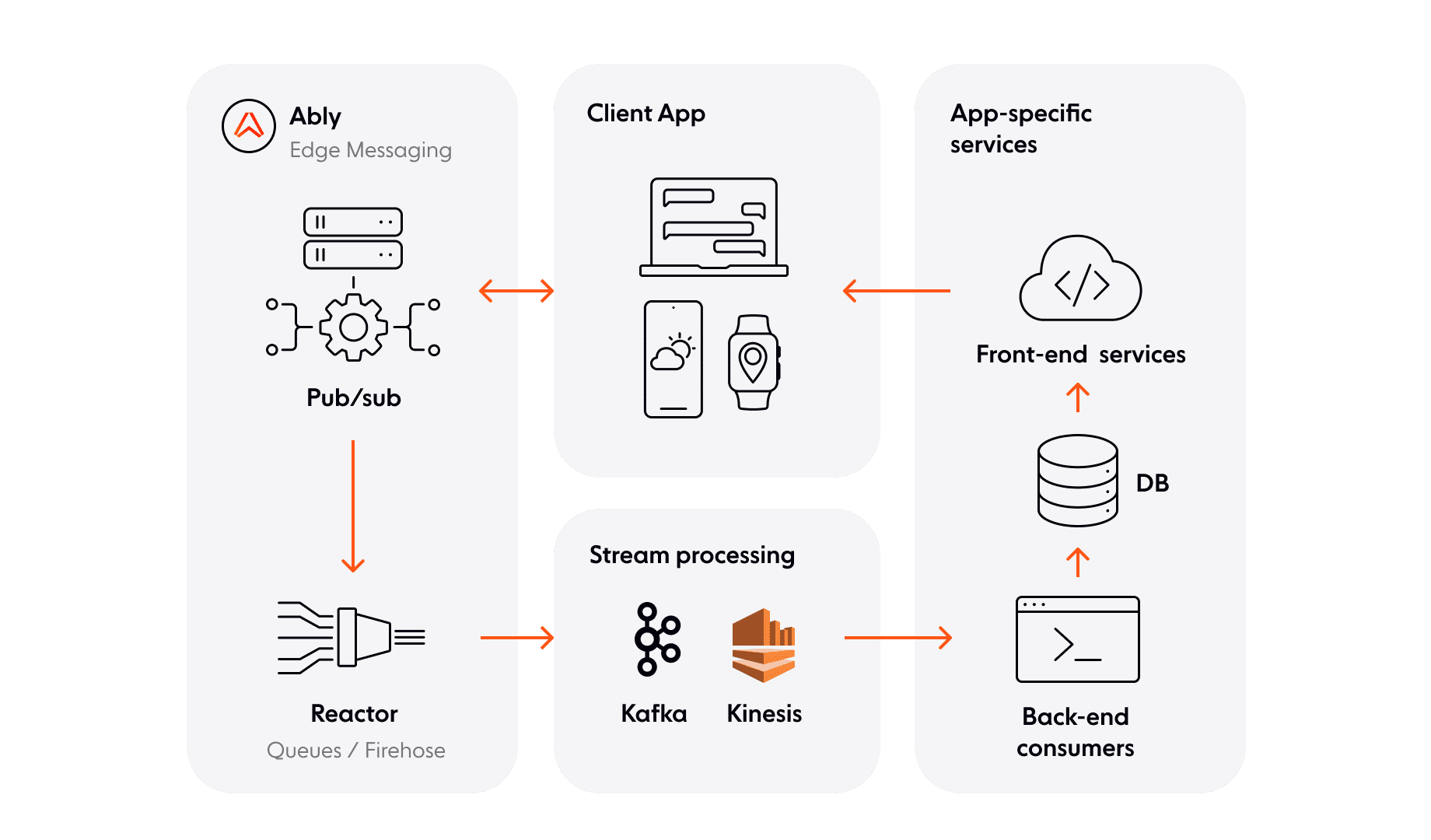
Note the following:
- Clients communicate with other clients through the serverless WebSocket messaging layer using pub/sub channels. All edits to shared record state are, in effect, communicated peer-to-peer in this fashion.
- Backend services do not connect to the messaging layer directly. Instead, they make use of integrations offered to have all record edit events forwarded to a message broker such as Apache Kafka or Amazon Kinesis. This enables a cluster of competing consumer workers to process incoming events in a reliable and scalable manner.
- Collaboratively edited record updates are not triggered by the frontend services that clients communicate with, but by backend consumer workers processing incoming events from stream processing services.
- The role of the frontend service here is to serve long-lived record snapshots to clients, but no interface to mutate those records is exposed. More discussion on this to follow!
Ably offers the following advantages as a realtime pub/sub messaging layer:
- Median round-trip latency of ~60ms in most regions is comfortably low enough to ensure edits resulting from human interaction feel smooth to all collaborators.
- High availability guarantees mean that users see each other’s edits and may also be able to work completely unaffected, even if the backend is down!
- Channels are low cost, making it feasible to create a channel per session or record being edited, even if there are millions in flight at once.
- Messages are also low cost, so edit events can be broadcast in high volumes to capture user activity as it happens.
- Channel rewind and persistence simplify the problem of joining an editing session “late” and needing to catch up on edits.
- Automatic reconnection and event replay ensure a good user experience through connectivity blips and avoids unnecessary reads
- SDKs exist for a wide range of client platforms, covering web, mobile and desktop.
- Ably supports a wide range of options for the backend to listen in and persist changes asynchronously, ranging from Web Hooks to Lambdas and various Firehose integrations.
Let’s now visit each component in more detail to get a better understanding of how this could be used in practice.
Client applications
As mentioned above, clients effectively communicate peer-to-peer through the realtime messaging layer to ensure changes made during collaborative editing are replicated to all users in the same session. This ensures that backend services are not a bottleneck for the realtime editing experience, relieving them of the tough latency and availability requirements that come with that.
We probably don’t want all users seeing edits to all records; just those they have explicit permission to access. Common pub/sub abstractions such as channels offer a good level of isolation. Ably channels are lightweight and we can reasonably create a channel per open record and issue tokens to users that are authorized to collaborate on the corresponding record so they can publish and subscribe to that channel. The following diagram illustrates this channel to record mapping across users.
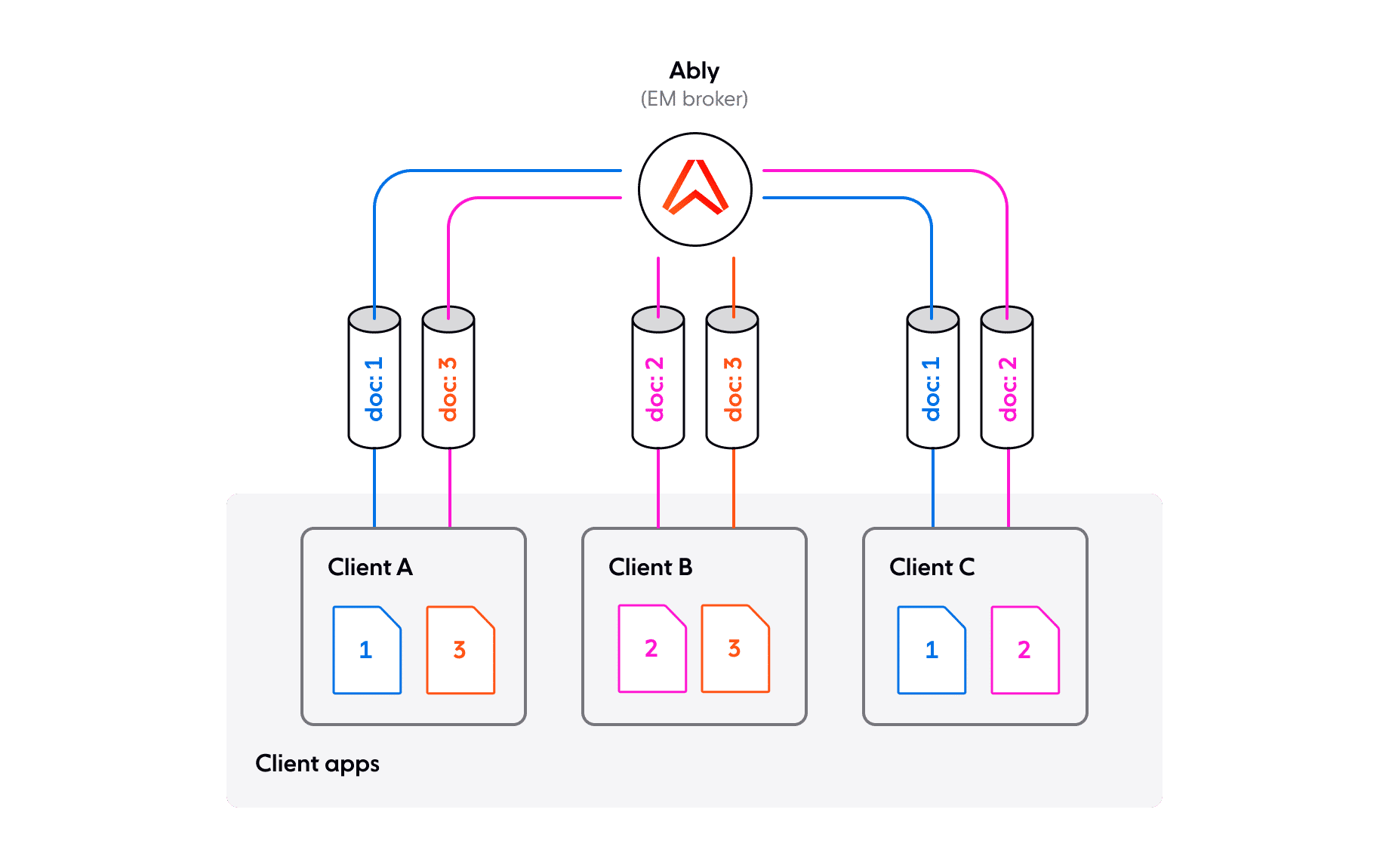
Which messages need to be sent over pub/sub to achieve conflict-free state synchronization at the model layer in the client application if there is no authoritative server for coordination?
This is where we’re reminded that there’s no such thing as a free lunch. Increased client application complexity is what we pay for the reduction in backend headaches, but we were going to face this one way or another, and thankfully there are tried and tested approaches to managing it.
For simple additive operations, you may not need anything special. For example, imagine a shared drawing canvas where it’s only possible to add new elements - no edits or deletes. Though it doesn’t sound very exciting, it would be easy to create a simple protocol of events on top of pub/sub that ensures replication of each element to all users as they’re added. This works fine, because the resulting model state would be the same no matter what order the edits are made. Local changes made by a user therefore won’t conflict with edits from others yet to be received on the channel.
Of course, most applications have more complex requirements, and need more sophisticated tools, such as CRDTs, which support state transformations in a conflict-free and eventually consistent manner. The idea is that you model your application state using specially designed data structures that guarantee conflict-free merges. You can then use pub/sub to share state changes to peers knowing that they will eventually arrive at the same resulting state.
Backend reducing function
You may have noticed already that the client application seems like it should “work”, for the most part, with no backend at all in this architecture. That is, you could edit records and share state among peers without the backend writing any record changes to the database at all. That’s all OK until everyone logs off and then someone tries to recall the same record a few days later.
Ably can persist event history for up to 72 hours, which we’ll now see gives us a generous grace period for backend availability, but it’s no substitute for long-term storage. Most applications want database records in their final states - not as a sequence of edit events. Given that all the information to produce that resulting state already exists in the Ably messaging layer and the customers have already seen it, however, the pressure is off for trying to get it into a permanent store as the changes happen.
At an abstract level, all that’s really required to turn this stream of events into the desired output is a reducing function:
reduce(old_state, next_event) -> new_state
While that covers the base requirement of getting data stores, it may also be a good idea to introduce some data validation at this point, as we want high confidence in the reduced record state before we persist it permanently. If it’s necessary to make a correction, this can be achieved by publishing an appropriate message type to clients using the REST API.
On a more practical level, we need some infrastructure to make this happen. There are several approaches to getting event streams out of Ably and into a convenient place for backend consumer processes.
For lower event volumes, it’s probably simplest to make use of webhooks or Lambda functions and skip the infrastructure altogether with a completely serverless backend option. This could get costly for higher volume use cases, where options instead include Firehose integrations for Apache Kafka, AWS Kinesis, or AWS SQS.
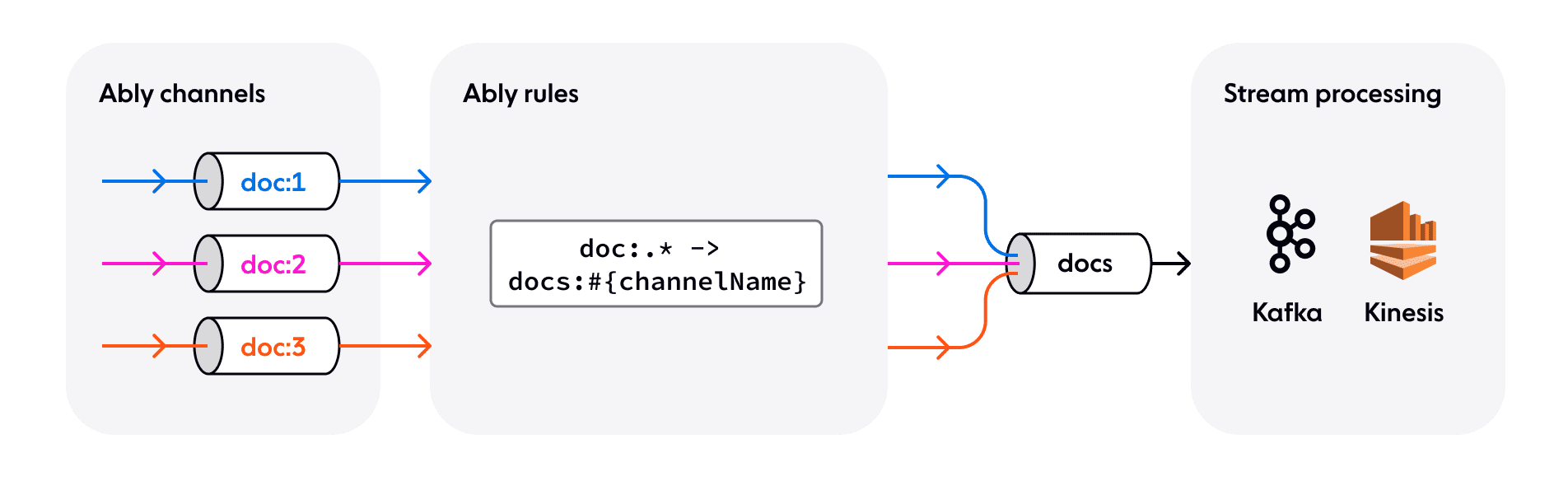
As a recent GartnerⓇ report explains, event brokers like Apache Kafka and AWS Kinesis have a different set of strengths to edge messaging brokers like Ably. The equivalent of the channel abstraction (topics or streams) is more expensive and has higher throughput. This suits the backend processing use case better than edge messaging, as we generally want to work with all events across all users and sessions as quickly as possible in the backend. Ably provides Firehose Rules so that developers can selectively forward groups of channels to backend event brokers, using regex to select channels by name.
Frameworks for consuming data from these services at scale are very mature. Kafka supports partitioning within topics and Kinesis has an equivalent concept of shards within streams as a mechanism for safe parallel processing of event data. Using the record ID to partition events forwarded to those systems ensures exclusivity over that record to the consumers processing data in the backend. This opens up possibilities for smarter caching in consumer processes to reduce database load as the reducing function is applied and new states calculated. Additionally, both event brokers support checkpointing to enable processing to resume in the event of failures or redeployments.
Note that the length of time the messaging layer retains event data is effectively the maximum downtime tolerable by this component. In practice, it may be suboptimal for clients to replay days of events retained in the channel to recreate the latest state. Nevertheless, processing the event stream is much more forgiving than the obligations on backend services where the server is relied upon to instantly arbitrate state changes.
Frontend services
Client applications need a way to load the stored state of records from the permanent store.
As far as collaborative editing goes, that is the only requirement this architecture really has of the frontend services - a simple database read. There are likely other things that will happen within this component in practice, such as authentication or exposing APIs relating to non-collaborative features, but it’s the other components that are doing the heavy lifting to enable realtime collaboration.
Ably provides the Channel Rewind feature, which can assist client applications in rejoining a live session after retrieving a state snapshot from this component.
Other approaches
Operational transforms are a well-known approach to collaborative editing of documents, applied to great success in Apache Wave and Google Docs. The basic idea is to represent all edits to a piece of shared state in the form of parametric operations. Clients work independently on their own local copies of that shared state, but instead of sharing the resulting updated state with other participants, they share the transformation they made. When a client receives operations from remote participants, they are expected to transform the parameters passed to that operation to allow for any edits made since.
The main criticism for OTs stems from the complexity of implementing them correctly as the operation inventory expands. The combinations of operations a client may see and the order in which they are applied will be numerous and hard to predict, making it difficult to gain confidence through test coverage.
Note also that infrastructure is still required for the exchange and coordination of operations among clients. Successful implementations (such as Google Docs) have significant custom infrastructure and backend services to make them work well. Taking this approach on a modest budget would be brave!
Figma wrote in detail about their novel approach to “multiplayer”, using their terminology. While the approach takes inspiration from CRDTs, the service implementation is clearly tailored very carefully to the desired user experience. Conflict resolution rules have been chosen that limit functionality in ways that won’t impact users too much, such as causing objects to disappear and reappear briefly in rare situations.
While a well-chosen limitation is often the better engineering decision over increased algorithm complexity to cover these corner-cases, engineers in the market for a collaborative editing solution can take little from this apart from inspiration. The architecture is designed for a specific product.
The striking difference with an serverless WebSockets-based architecture is that developers looking to build collaborative experiences in applications have a “buy” option for most of the incidental complexity, particularly on the infrastructure side.
The price for this will sometimes be increased client-side complexity, such as needing to deploy CRDTs for advanced collaborative editing requirements. For many businesses, however, this is the right trade-off, as that complexity will be manageable by the team already building the product. Setting up and expanding a team to build and maintain globally distributed and highly available infrastructure will usually be a deal-breaker if it’s not already required for the product in question.
Putting it all together
By introducing a realtime messaging layer and eventually consistent data models within client applications, developers can build scalable and reliable collaborative experiences without building extensive new infrastructure. For some use cases, it may even be realistic to use entirely serverless components.
The serverless WebSockets pub/sub messaging layer in this architecture ensures that customer experience is responsive and reliable, even at planet scale. Part of what makes this attractive is that developers benefit from the serverless (or very low Dev Ops) nature of using a PaaS product, while still having the flexibility of lower-level messaging APIs to make their own decisions about application architecture.
The consequence of having a backend as a passive listener, designed to fall behind the clients’ editing behavior, makes for a very forgiving and fault-tolerant system. The application code has to be capable of loading a snapshot that will be outdated by the time it arrives, given the realtime nature of collaborative editing. Solving this using channel rewind means that, actually, the snapshots can be pretty old before anyone would notice. That means your Kafka cluster can have a bad afternoon without your customers also having one.
All server-side components here scale using conventional, well-tested approaches. Event brokers like Kafka and Kinesis both have recommended best practices for designing scalable consumers that merge and sink incoming data to a database.
The frontend component is stateless - as far as the requirements here are concerned - meaning they can be trivially replicated for scalability and availability. There are also hosted and serverless options available for these components, which may take away even more of the scalability headaches.
Customers including Webflow, Mentimeter, and MobyMax have built reliable multiplayer products that serve global audiences on top of Ably’s realtime infrastructure. Visit our Spaces product page to learn more about how you can add collaborative experiences with Ably.

Further reading
- Ably's globally-distributed architecture for reliable, low-latency edge messaging
- How do CRDTs solve distributed data consistency challenges?
- Engineering dependability and fault tolerance in a distributed system
- Everything you need to know about publish and subscribe
- Ably's four pillars of dependability


