Introduction
This is an article about the complexity of maintaining data consistency in distributed environments. It introduces conflict-free replicated data types (CRDTs) as a way to resolve concurrent data changes.
What is a CRDT? It's a conflict-free replicated data type (which is also sometimes known as “convergent replicated data type or commutative replicated data type). Using a CRDT can help to resolve replication conflicts when concurrent operations occur on replicas within a decentralized environment.
In this article, we answer the following questions:
- What is strong consistency? What is eventual consistency?
- What is replication conflict?
- How does Google Docs resolve conflicts?
- What are operational transformations (OTs)?
- What are conflict-free replicated data types (CRDTs)?
- Why use CRDTs?
- Do CRDTs simplify software design?
- What are the disadvantages of CRDTs?
- What are the use cases for CRDTs?
- Where can I find out more about CRDTs?
Common data consistency challenges
Consider a situation where there are several distributed entities that each hold a copy of the same data. Data consistency is maintained if those copies continue to match each other, even when one or more of them are updated.
If a single entity updates its copy of the data, there is no dispute about the latest ’source of truth’ for that data, but there may be temporal differences in the state of each distributed entity. Network latency will affect the rate that each peer receives updates; network or system failures mean that some peers may never receive updates.
Aside from simply causing some updates to fail to reach some peers, those failures result in a data consistency challenge. For example, the distribution of some updates can fail, but others succeed; this causes consistency and ordering problems. A system design needs to accommodate such cases to ensure consistency.
There are further challenges if multiple entities make independent updates concurrently to the data. Now, there isn’t necessarily a single, canonically “correct” version of any data. Updates created by one peer in one state might conflict, or not make sense, to other peers that have visibility of other updates.
What is strong consistency? What is eventual consistency?
Strong consistency is the propagation of any update to all copies of data. In the most simple case, a series of updates to the data come from a single source, and all other entities that hold a replica of the data are guaranteed to receive those updates in the same order.
When multiple copies of the data can be updated at the same time, there needs to be a way to agree upon the correct version of the data. With strong consistency, once one entity makes any updates, all other replicas are locked until they’ve been updated to the same new version. The source of truth pushes updates to all entities in the same order to keep them ‘in step’.
The design constraints imposed by strong consistency are unacceptable in an increasing number of use cases. Consider realtime collaboration (as seen in online productivity tools that permit users to make concurrent edits). Every entity can potentially make and receive updates, so there is no way to ensure that each replica receives the same sequence of updates. Eventual consistency is the property where the state of the data is eventually reconciled, regardless of the order of update events that reach each replica.
What is replication conflict?
Replication conflict occurs when it is not clear how to reconcile changes to reach data consistency. For example, which update takes precedence? There needs to be a common agreement on how to resolve the conflicts.
Consider the simple case where Alice and Bob are using a collaborative coloring application. Both select the same area of the image to fill with color: Alice chooses to fill it with yellow; Bob fills it with blue. Should the area be colored yellow or blue (or green: a combination of both updates)?
The most common solution is to have a single arbitration policy that resolves such conflicts using a set of rules, like the “last write wins,” which uses the timestamp of each update to apply changes in the order in which they occurred. In the above case, if Bob made his edits after Alice, they’ll trump hers, and the color of the section stays blue for Bob and changes to blue for Alice, or vice versa if Alice made the last edit.
What happens if replication conflict cannot be resolved?
When timestamps are equivalent and cannot be used to resolve the conflicts, the resolution policy could be a rule such as, “Which account has the lowest ID number?” or, “Which username comes first in the alphabet?”, resulting in one update taking precedence. The policy can be somewhat arbitrary as long as it is applied consistently by all peers.
Occasionally, a brute force approach is needed, which, for example, abandons the effort to reconcile the conflicting changes, and it neither combines the updates nor arbitrarily selects one. In the case of Bob and Alice, a brute force approach might be to override both changes, discard them, and revert the section to its original color, which makes for a poor user experience but ensures data consistency. Alice and Bob have to make further updates and effectively reconcile the conflict themselves.

How does Google Docs resolve conflicts?
Consider the case where Alice and Bob concurrently edit the same Google document. Alice types in “Hello World!”. Then she removes “World”. Bob also types in “Hello World!”.
Alice has made an addition and a removal. Bob has made an addition, which is the same as Alice’s. When we think about how to reconcile their changes, there are two potential interpretations.
First, let’s combine Alice’s addition, Bob’s addition, then Alice’s removal:
Alice’s addition + Bob’s addition + Alice’s removal:
Hello World! + Hello World! - World.
Sensible conflict resolution detects that the two additions are identical. It discards one of them to avoid duplication. Then the word “World” is removed:
Hello World! + Hello World! - World = Hello!
But what if you change the order of the edits? Consider Alice’s addition, Alice’s removal, then finally Bob’s addition:
Hello World! - World + Hello World!
Now, conflict resolution needs to work out whether Bob’s addition should be merged with Alice’s two contributions. Should the data read “Hello!” (discarding all of Bob’s addition” or should it read “Hello World!” (adding in the piece of Bob’s text that differs from the data after Alice’s pair of edits)?

Google Docs uses operational transformations to solve this data consistency challenge. Based on a client-server model, each user is a client that holds a replica of the document, and Google Docs acts as a central server. A client’s changes propagate back to the server, which passes them on to the other clients.
What are Operational Transforms (OTs)?
When a data replica changes, the client represents the updates as one or more “operations” (each one encapsulates the change that was made, not the outcome of that change) and shares them with a central server. Multiple clients make concurrent changes, so they will each be in different states. They send their operations to the server, which accommodates these different starting states by deciding on the order the outstanding set of operations should be applied (using rules such as last write wins). It then transforms the operations before propagating them to each client to apply to their copy of the data.
What is a CRDT?
We gave the definition of a CRDT at the start of this article, as offering the potential to resolve replication conflicts when concurrent operations occur on replicas within a decentralized environment. How does this work?
With a CRDT it is mathematically always possible to merge or resolve concurrent updates without conflicts or a central arbiter. A key approach is to reduce all edit operations to just commutative ones so that the order of the changes no longer matters. In practice, this takes care of changes that arrive “out of order” because either there is no fixed order for independent changes occurring on different replicas or, when there is a valid order, there is no guarantee that changes can propagate to every recipient to adhere to it.
For example, if the data type is a counter value that can only be incremented, the order in which two operations occur is unimportant. If the value starts at 0 and one replica (Alice) sends an increment of 12, while another replica (Bob) sends an increment of 6, the combined updates on other replicas amount to the same value (18) regardless of the order of changes applied. Although all replicas may diverge temporarily, the data will eventually return to consistency (strong eventual consistency).
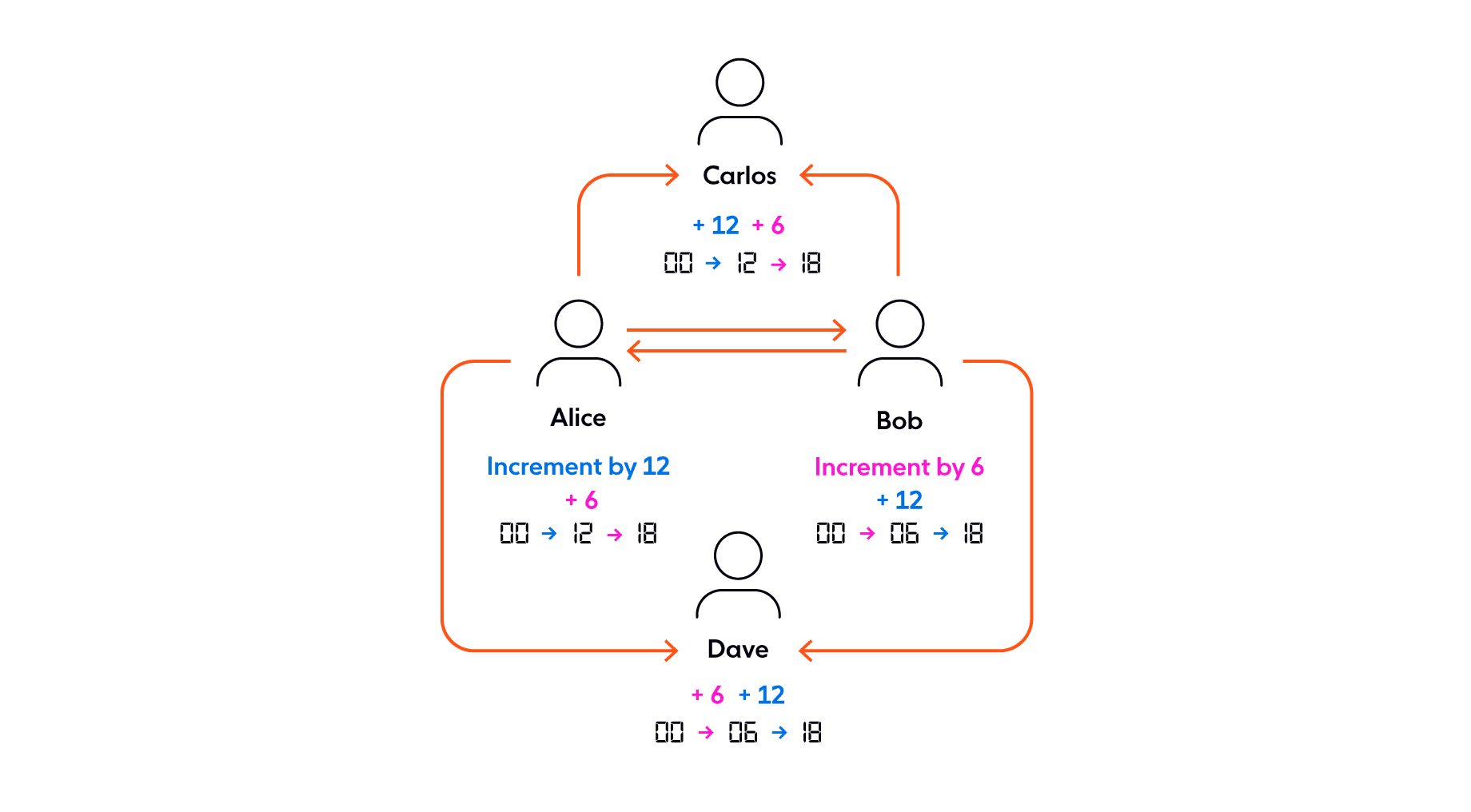
With state-based CRDTs, the client doesn’t pass on the operation(s) it applied to change the data. Instead, it sends the new state of the data (as a CRDT) to all other clients. Clients can merge with their own changes because the CRDTs conform to a consistent policy to resolve conflicts and eventually converge.
In operation-based CRDTs the update operation is propagated and applied locally. There are some delivery requirements to ensure that every update operation is transmitted just once to a replica because, in some formulations of CRDTs, operations are not always idempotent. Once they arrive at the replica, like state-based CRDTs, they can be applied in any order.
Why use CRDTs?
The purposeful removal of the need for a central coordinator creates a distributed environment that allows concurrent data interchange among large numbers of users. Under these circumstances, a central server may be impractical for reasons of scale.
Additionally, the lack of assumptions about any central servers means CRDTs can be used whether or not any such servers happen to be a part of the topology.
Do CRDTs simplify software design?
CRDTs have a lenient approach to the order of operations. In theory, this reduces the design complexity of distribution mechanisms since there is no need for strict serialization protocols. By tolerating out-of-order updates, the distribution mechanism has to meet simpler integrity guarantees. However, some complexity arises for an application using the CRDT, because that data structure might not be as expressive as the application needs, which we’ll describe as follows.
What are the disadvantages of CRDTs?
To be order-agnostic, CRDTs are limited to a simpler, reduced set of permissible operations on shared data, and this means that some compromise in the feature set and user experience is almost inevitable.
The classic example from a paper by Martin Kleppmann is as follows. Alice and Charlie are concurrently typing into the same document at once. The data already reads “Hello!”. Alice decides to insert her name in the text, to make the data read “Hello Alice!”. Meanwhile, Charlie has the same idea and inserts his name, so the text reads, “Hello Charlie!”.
Each individual character they add is treated as a separate insertion into the document, and they are simply added, at the same insertion point, ordered by timestamp.
Adding the typed characters in insertion order means that everyone sees the same copy of the data, but the jumble of edits that results (H e l l o A l C i h a r c l i e e !) isn’t what either person intended.
To avoid this scenario, and other similar issues when users invoke ‘undo’ or mark up their text, it requires the CRDT algorithm to preserve historical state to compare changes against as they arise. An intuitive conflict resolution strategy is technically complex and raises a resource efficiency problem by the amount of storage needed for the document’s state.
Where can I find out more about CRDTs?
Marc Shapiro, Nuno Preguiça, Carlos Baquero, and Marek Zawirski outlined CRDTs in 2011, and their paper is fundamental to understanding the concepts.
Martin Kleppmann has continued to move the topic forward, and his lectures and talks are accessible to the casual enthusiast.
Alan Gibson maintains a comprehensive list of resources on Github, as does Nikita Voloboev. If you want to get lost in the underlying theory, A Comprehensive Study of Convergent and Commutative Replicated Data Types should be on your reading list. For a layperson, these video introductions to CRDT concepts are somewhat more accessible.
What are the use cases for CRDTs?
The use cases for CRDTs include: chat applications; productivity tools for online collaboration; tools where there is a competitive element such as ticketing systems, online auctions, and other realtime stock market systems; presence awareness; global data centers.
A growing list of CRDT implementations includes a range of enterprise-grade solutions such as Redis Enterprise, Microsoft Azure CosmosDB, Concordant, Soundcloud, Figma, Facebook, PayPal, League of Legends, Bet365, Akka, OrbitDB/IPFS, Apple Notes, and Ably.
Ably and CRDTs
Ably is the high-performance infrastructure that powers synchronized experiences for millions of users worldwide. We already use CRDTs to simplify the engineering problem of disseminating information and we also engage in use-case research. We sponsor work in the CRDTs field (and are particularly excited about Yjs, which has a strong algorithm to support text editing, and Automerge).
We want to enable the full range of collaborative applications that use Ably. We are actively researching how to exploit CRDTs as one of the building blocks of real-life, realtime applications, and would be interested in hearing from you if you have any suggestions: just contact our technical experts!
Further reading
- Scale up to a collaborative and multiplayer architecture with edge messaging
- Channel global decoupling for region discovery
Acknowledgements
I’d particularly like to thank Paddy Byers and Martin Fietkiewicz for their help in writing this article.