

As the post-pandemic world emerges, the future of events such as summits, conferences or concerts is brighter than ever. Thanks to hybrid events, in-person events are now doubled by online happenings, which allows event organizers to reach much larger, geographically distributed audiences. For organizers and ticket distributors, providing a great ticket-booking experience to their global audiences has become more important than ever.
Learn how extend Kafka to end-users at the edge with Ably.
In this guide we’ll show you how to build a ticket booking solution that allows you to process and distribute large quantities of ticket data for live, virtual or hybrid conferences, to and from a large number of customers - with reliability and speed.
The guide is divided in the following sections:
- Characteristics of a dependable ticket booking solution
- Tech Stack
- Ticket booking solution architecture
- Building the realtime ticket booking solution
- Conclusion
Characteristics of a dependable ticket booking solution
Building a ticket booking solution that provides an optimum user experience is by no means an easy feat. There are several factors that need to be taken into account and addressed.
Scalability
The ticket booking system will likely have to deal with a very high and unpredictable number of concurrent users. Therefore, you need to ensure that it is dynamically elastic, and can quickly scale to handle up to millions of simultaneous users, without the quality of service being degraded.
Data must flow in realtime
Instantaneous data exchanges are of the utmost importance. The number of remaining tickets must be updated in realtime, so users always have accurate, up-to-date visibility into the status of any given conference. To achieve this immediacy, data must not only be stored and processed in realtime, but it must also flow between client devices and other components as fast as possible, with consistently low latencies.
Data integrity
Guaranteed ordering and exactly-once semantics are critical for any reliable ticket booking solution. If data is sent out of order and delivered multiple times (or not at all), it can negatively impact the user experience. Think, for example, of a scenario where customers need multiple attempts to book a single ticket to a conference, because the system only supports at-most-once semantics.
Tech stack
Let’s cover the various components we will use to build our dependable realtime ticket booking solution. All of the technologies chosen for this demo are freely accessible, and require no more than making accounts.
FastAPI as the API server layer for writing events to Kafka and consuming webhooks from Ably
FastAPI is a high-performance, highly-structured web framework for developing web APIs with Python, based on standard Python type hints. It’s built on top of Starlette and Pydantic, and it enables us to use a REST interface to validate, serialize, and deserialize data. We’ll use FastAPI to build our frontend API component, which is responsible for writing to Kafka topics, and consuming webhooks from Ably.
Apache Kafka on Confluent for internal event streaming and persistent storage
Apache Kafka is becoming the standard for building event-driven pipelines. A distributed pub/sub platform, Kafka has impressive characteristics, such as low latency, high throughput and concurrency, fault tolerance, high availability, and robust data integrity assurances. Additionally, Kafka provides persistent storage (data can be stored to disk indefinitely), and integrates with multiple stream processing components, like ksqlDB.
For our tutorial, we’ll use Kafka as a backend component responsible for reliable storage and realtime distribution of data to the public Internet-facing messaging layer, Ably.
The most convenient way to get started with Kafka is via the Confluent platform. Founded by the original creators of Kafka, Confluent provides fully managed Kafka deployments, and a host of other features, such as stream processing capabilities and sink and source connectors, so you can easily transfer data between Kafka and other systems.
ksqlDB for stream processing
ksqlDB is a Kafka-native database purpose-built for stream processing applications. It allows us to filter, process, and join Kafka topics in order to create new, derived topics.
ksqlDB is an abstraction over the well-known and used Kafka Streams library, allowing us to use familiar SQL to sort, shape, and transform data directly rather than having to write Java code to do it. Though less flexible than Kafka Streams, ksqlDB makes common use cases far simpler and quicker to iterate. In addition, it does directly integrate with Kafka Connect (although, in our case, we’ll be reading from a destination topic rather than pushing data straight to a connector.)
Ably for scalable and dependable data streaming to and from clients at the edge
Ably is a cloud-native pub/sub messaging platform chiefly designed for distributing data in realtime to any number of web and mobile clients, anywhere in the world. You can think of Ably as the public Internet-facing equivalent of your internal Kafka-powered event-driven pipeline. Ably matches, enhances, and complements Kafka’s capabilities. Our platform offers a simple, dependable, scalable, and secure way to distribute Kafka data across firewalls to end-user devices over a global edge network, at consistently low latencies (<65 ms median round-trip latency) - without any need for you to manage infrastructure.
Publishing Kafka records to Ably is easily achieved by using the Ably Kafka Connector, a sink connector that can be self-hosted, or hosted with a third-party provider - the most common being the Confluent Platform.
In addition to distributing data to end-users, Ably is often used for streaming data from client devices to other systems (in our case, we will use Ably to send batched webhooks to the FastAPI component).
Ngrok as a proxy for ingesting webhooks sent from Ably into FastAPI
Ngrok exposes local servers placed behind NATs and firewalls to the public Internet over secure tunnels. We’ll use Ngrok to proxy the batched webhooks sent from Ably into the local FastAPI instance.
Ticket booking solution architecture
This diagram presents the high-level architecture of our realtime ticket booking solution:
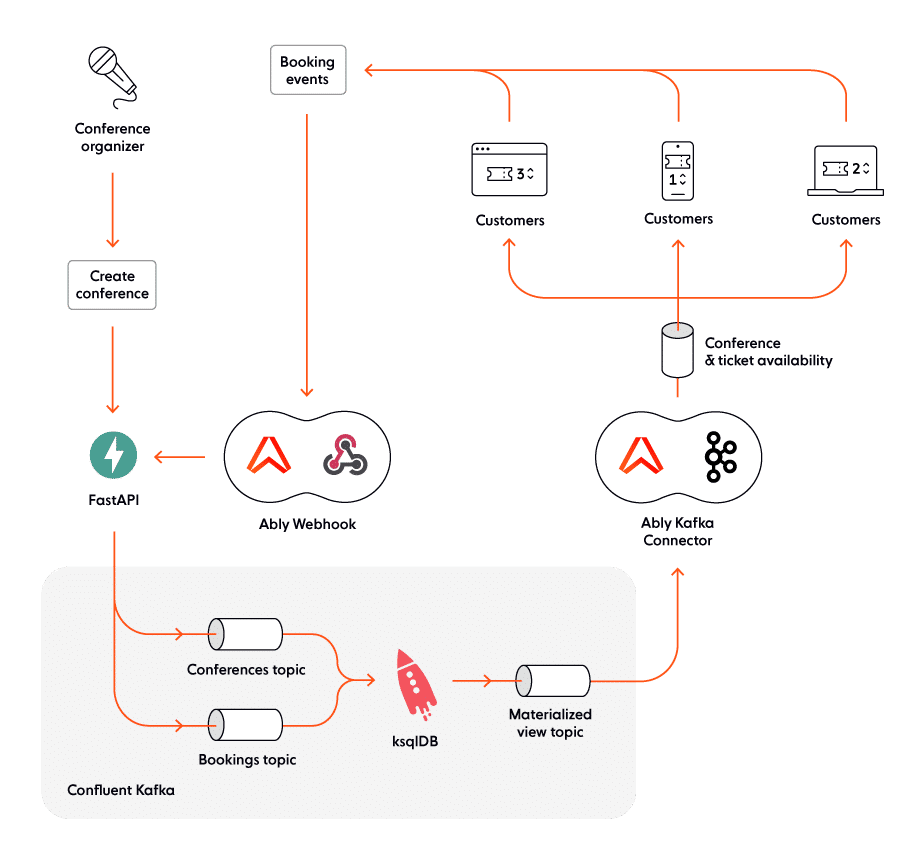
Now, let’s dive into details and see how the system works, end-to-end.
- Whenever a new conference is planned, the organizer sends a “Create conference” API request to the frontend API component (FastAPI).
- Next, the frontend API publishes the conference-related data as a record in the “Conferences” topic in Kafka. To make an analogy, a Kafka topic can be thought of as a folder in a filesystem, while the record can be regarded as a file in the respective folder.
- Records stored in the “Conferences” topic are then processed by ksqlDB, the stream processing component in our architecture. The output is written to the “Materialized view” Kafka topic. Note that Kafka can persist records to disk for as long as needed, and guarantees that they will be sent downstream in the same order as they were written.
- Kafka data from the “Materialized view” topic is sent to the “Conference & ticket availability” Ably channel, via the Ably Kafka Connector.
- Ably then broadcasts the data in realtime to all client devices who are subscribed to the “Conference & ticket availability” channel. Ably guarantees ordering and exactly-once semantics, and ensures data is distributed at consistently low latencies (<65 ms median round-trip latency), over a globally distributed and fault-tolerant global edge network. Furthermore, Ably is dynamically elastic and can quickly scale horizontally to handle millions of concurrent subscribers.
- Whenever a user books a ticket for a conference, a webhook is triggered; webhooks are sent in batches to the FastAPI component over Ngrok secure tunnels.
- FastAPI publishes the booking-related data to Kafka. However, this time, data is written to the “Bookings” topic instead of the “Conferences” topic.
- Each time a new record is written to the “Bookings” or “Conferences” topics, ksqlDB merges the changes into a unified view, the “Materialized view” topic - which reflects the latest state.
This architecture ensures that:
- Users have an accurate, always up-to-date view of all upcoming conferences, together with the number of available tickets for each conference.
- Data travels in realtime, with last-mile ordering and exactly-once semantics ensured by Ably.
- The system can scale to handle a significantly high and rapidly changing number of concurrent users.
Building the realtime ticket booking solution
Now let's walk through all the steps required to configure the constituent components and build our realtime ticket booking solution.
Out of scope
A complete ticket booking solution would involve payment processing, account management, and additional features, but these are out of scope for our demo. However, due to the decoupled nature of the project, with Kafka and Ably acting as message busses, adding these features later through microservices would be a straightforward process.
Schemas and specifications
API and data definition specifications allow developers to easily build services that can communicate with each other reliably, and validate data. For our REST API component (FastAPI), this means using an OpenAPI Specification (Swagger), with a JSON schema. The REST API uses Pydantic to provide the information needed to create the OpenAPI Specification and generate the functions required to validate and deserialize the inbound data.
Just like Ably, Kafka can transport any type of data type you want, but it’s best known and configured for Apache Avro-encoded data. Avro is an efficient, open-source, schema-driven binary encoding library (similar to Apache Thrift or Protobuf). In the Confluent ecosystem, Avro is the standard way to encode your Kafka data, and it’s very well supported.
The Confluent platform comes with Schema Registry, a convenient tool for storing the schemas for Kafka records. As long as you use Avro as your wire format, ksqlDB can access the schemas to reduce the boilerplate code required per query. In addition, ksqlDB’s output can be in JSON format, so end-users can easily consume it.
Getting started with Ably
Ably allows you to effortlessly scale to millions of concurrent users, without having to manage or even think about messy infrastructure for last mile delivery. All you need to do is:
Setting up the Confluent ecosystem
Setting up Confluent can be done in different ways - for example, with Docker, or by running it locally. For our demo, we’ll be running it locally.
Start by downloading the Confluent Platform.
Note: Be sure to have your local JDK set to version 11, which is required by the Confluent Control Center (more about this later).
Assuming you’re working on a Mac, you can install the JDK by using brew with the following command:
brew cask install java11Once this is done, run:
export JAVA_HOME =/usr/local/Cellar/openjdk@11/11.0.12/libexec/openjdk.jdk/Contents/Home
export CONFLUENT_HOME=~/confluent-6.2.0
export PATH=$PATH:$CONFLUENT_HOME/bin
confluent local services start
These commands ensure that the Confluent platform sees a compatible JDK, and adds Kafka, ksqlDB, and other Confluent components to your session, making it easier to command and control the system.
You should see the following response:
Starting ZooKeeper ZooKeeper is [UP] Starting Kafka Kafka is [UP] Starting Schema Registry Schema Registry is [UP] Starting Kafka REST Kafka REST is [UP] Starting Connect Connect is [UP] Starting ksqlDB Server ksqlDB Server is [UP] Starting Control Center Control Center is [UP]
To confirm, visit http://localhost:9021/, where you should see a Confluent Control Center cluster:
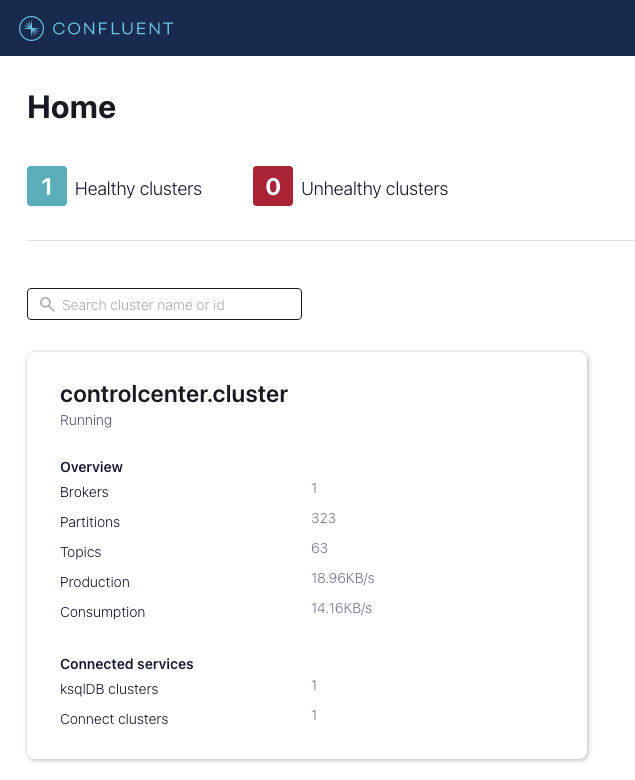
The cluster comes with some pre-made Kafka topics and data, which are used to manage the Connect cluster and the ksqlDB instance. Note that there is only a single broker; this would not be the case for any production system, which involves multi-broker deployments. However, for the purpose of our demo, one broker is all we need.
Now, download and install the Ably Kafka Connector, a sink connector used for streaming data from Kafka topics into Ably channels.
After running the install command in your terminal session, you’ll have added the Ably ChannelSinkConnector to your local confluent-hub. The tool will walk you through a series of instructions which you’ll need to follow in accordance with your system. The defaults are fine here, but if you have multiple clusters, please select the ones you need.
Once you've completed this step, let's check the connector is indeed installed by going to the Confluent Control Center (http://localhost:9021/), and navigating to the Connect cluster:

Now, select the ChannelSinkConnector.
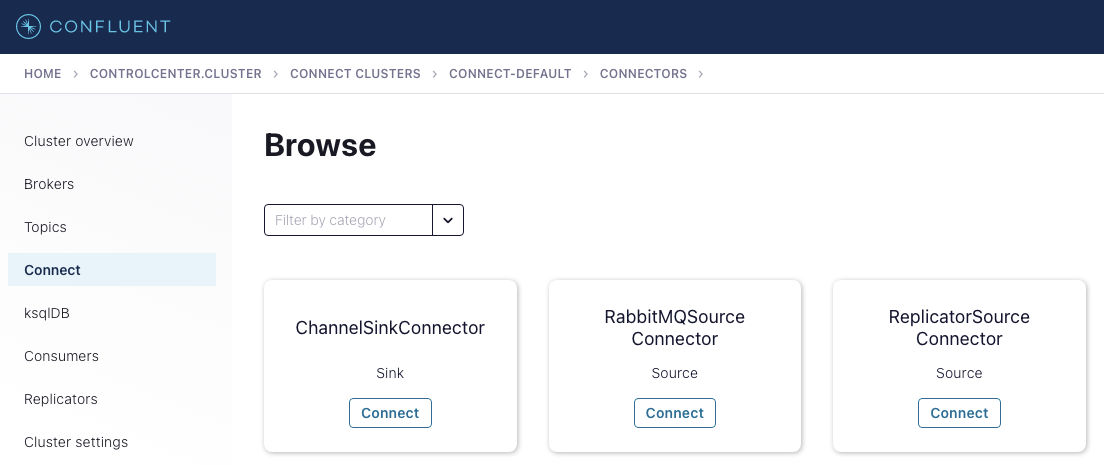
Kafka Connect is effectively a no-code solution; you just have to select the topic you wish to use as the source of the outbound messages, add in your Ably API key, and you’re ready to go. We’ll be walking through this later once we have the data ready to go.
Setting up FastAPI
Note: For this demo we recommend using Python 3.9.
To install FastAPI, run:
$ pip install fastapi
FastAPI is built on top of two key libraries: Starlette and Pydantic. Starlette was developed by one of the creators of the Django REST framework in an attempt to simplify and speed up the process of building REST APIs in Python. Starlette is fast and asynchronous by design, giving FastAPI runtime speed, and a simple, extensible foundation.
The other library, Pydantic, is designed to handle serialization and type enforcement. It provides a clean way to make and expose type-safe Python classes to API users, and helps validate data coming in and out. You can even use this library to generate Pydantic classes from JSON Schema to use in your codebase.
In FastAPI, Pydantic allows for simple serialization and deserialization of requests to and from JSON and Python objects. Due to its type enforcements, Pydantic can validate data over any of the API routes, and is used to auto generate all of the OpenAPI documentation for our Python API.
FastAPI requires an Asynchronous Server Gateway Interface (ASGI) server to power it. Popular choices include Uvicorn, Gunicorn, and Hypercorn. In production, it’s probably worth using Hypercorn, which comes with HTTP/2 support, increasing performance (this is especially useful for outbound webhooks received from Ably). However, for this demo we are going to use Uvicorn, since it has a friendly debugging setup.
This is how you install Uvicorn:
$ pip install "uvicorn[standard]"
Schemas represent the core of our ticket booking solution. With pydantic, we have a series of Python objects that define the Ably webhook schema, and also the schema for the REST API we’ll be exposing for conference creation.
We need to import the parts we are going to use and add BaseModel as the parent of our data classes. The data class depicted below defines a conference in the system and on the API:
class Conference(BaseModel):
eventId: str
eventCapacity: int
eventDate: int
bookingStart: int
bookingEnd: int
timestamp: int
pass
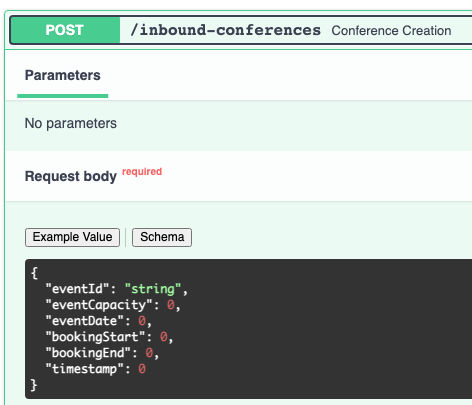
Pydantic gives these classes a series of methods, allowing us to expose them as dictionaries, and validate input. The Conference class is a parameter in the post request handler function on the API:
@app.post('/inbound-conferences')
async def conference_creation(data: Conference, request: Request):
try:
conference_producer.produce(conference_topic, None, data.dict())
conference_producer.poll(0)
conference_producer.flush()
print(data.dict())
except Exception as e:
print(e)
return 400
return 200
This makes it easy to add it to the OpenAPI specification generated by FastAPI:
Next, let’s cover the Avro schema. Avro is a tool that performs binary serialization of data defined by a schema, and it’s the canonical way to serialize and store data in Kafka. The Confluent Platform includes a tool called Schema Registry, which:
- Makes it easy to store and validate data published into Kafka topics.
- Acts as a source of truth for what the schema of the data in a Kafka topic is.
When combined with ksqlDB, the Schema Registry offers the added benefit of providing it with the types, keys, and structure of the data you can query.
We have schemas for two Kafka topics: “Conferences” and “Bookings”, the latter containing records about the number of places being reserved for the conference in question. They have a userId, an eventId, and a number (of available tickets left).
The Kafka producers (FastAPI) are serializing producers; they write data as Avro in the two Kafka topics. Note that there are two separate producers, since each topic requires a different schema. Currently, although the Confluent Kafka Python producer SDK can serialize to Avro, it does so by using a dictionary rather than just an object. However, as our data objects are Pydantic models, we can just call the dict() function and go from there.
The “Bookings” endpoint is a bit more complex. Ably allows you to send a large number of messages into a single endpoint via webhooks. We’ll be using batched webhooks, since this allows us to collate individual messages (up to 1000) into a single call. The first Pydantic model converts this batch into a Python object called an Ably_webhook. As the payload JSON data is serialized to strings in Ably webhooks, we need to do a second step, with a simple list comprehension to deserialize these to objects before they can be published into Kafka.
Configuring Ngrok
Ngrok is one of the most helpful developer tools out there for building systems that make use of webhooks. It provides you with a URL that serves as a proxy for external traffic to an internal API. Once you match the ports and the routes, you’re good to go.
First, you have to download and set up Ngrok.
Once that’s done, start it up with this command:
ngrok http 8000 You should now see a window with your new URL:
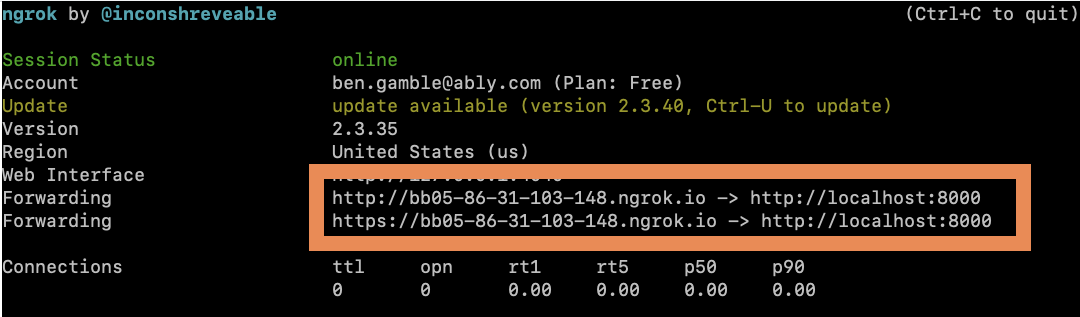
Once you have your URL, you need to set up a new Ably Reactor rule.

Add your Ngrok URL as the target, set it to batched mode, and add bookings:* in the Channel Filter field. What this does is add a filter to all the channels created by your application; any channel that has a name starting with “bookings:” will be automatically processed by this rule.

When you test the new rule, you should see data hit your API. Note that it will throw an error, due to the empty message payload:
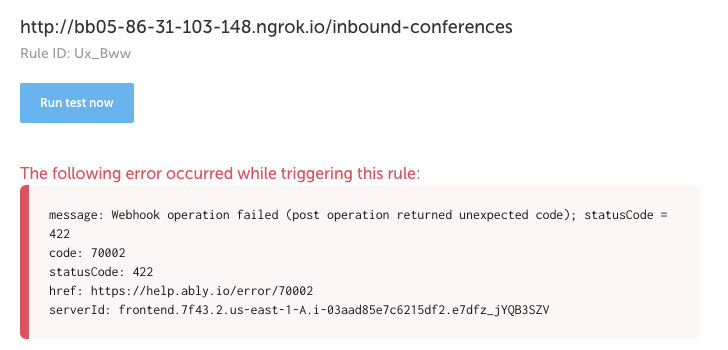
On your console, you should see the following message, which confirms that the webhook has reached the API (but has been rejected for not conforming to the specification):

Don’t worry that you are getting errors at this point; the purpose is simply to test that the webhooks are indeed reaching their destination endpoint.
Putting it all together
It's time to see how the components of our system interact with one another, and how data travels in realtime.
Let’s start by generating some conferences! We can do this by using the generation script called event-creation.py, which you can find in the testing folder. The script creates a defined set of JSON payloads - these are events (conferences) that start from the current date. All of them have random names and ticket numbers. The conferences are offset through time to make it a bit easier to see the streaming window in action.
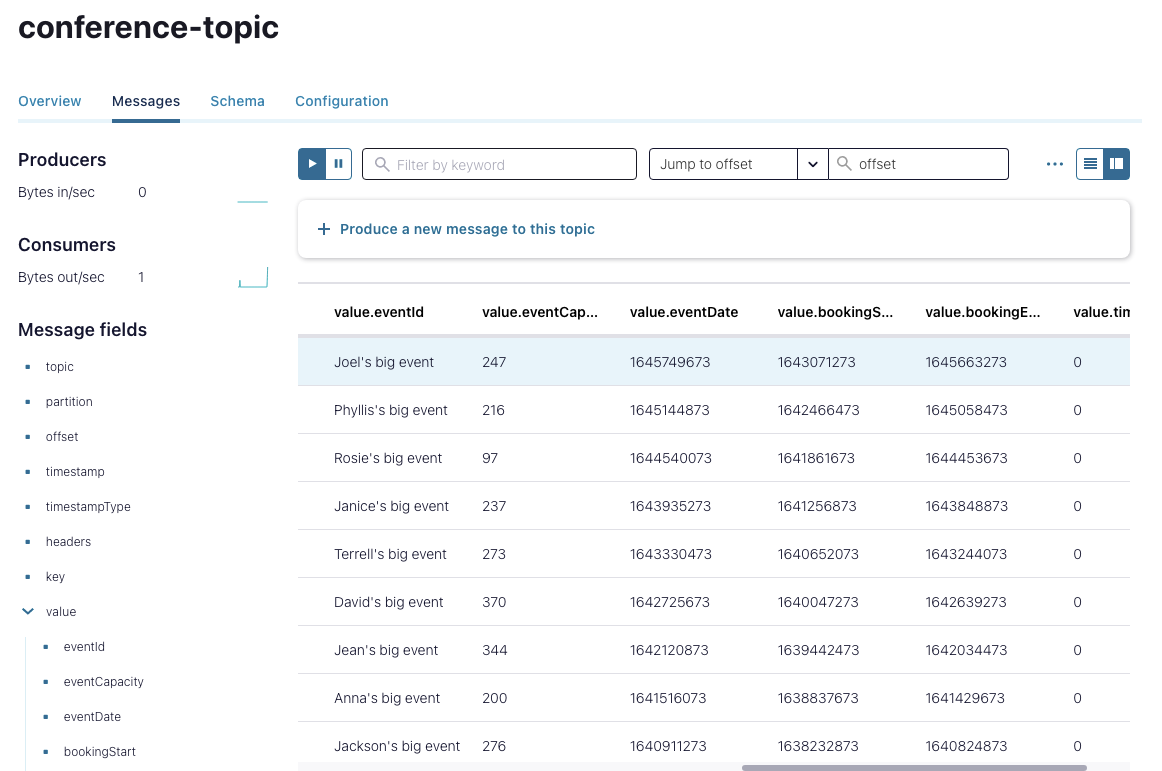
Once you’ve run the script, you’ll see the data hit the API, create the “Conferences” topic in Kafka, and add the schema to the Confluent Schema Registry.
You can see the list of conferences in the Confluent Control Center:
Now that we have created some conferences, we can start working with ksqlDB, a powerful tool that allows you to explore and learn about your data by creating tables and streams; additionally, ksqlDB also provides enrichment and data transformation features. For our demo, we'll only use a small subset of ksqlDB’s capabilities. You can find all of the queries in the queries folder.
First, we must create a stream from these conferences so we can act upon them. Use the following query:
CREATE STREAM conferences WITH(
KAFKA_TOPIC = 'conference-topic',
VALUE_FORMAT = 'AVRO'
);
This is how it looks in the Confluent Control Center:
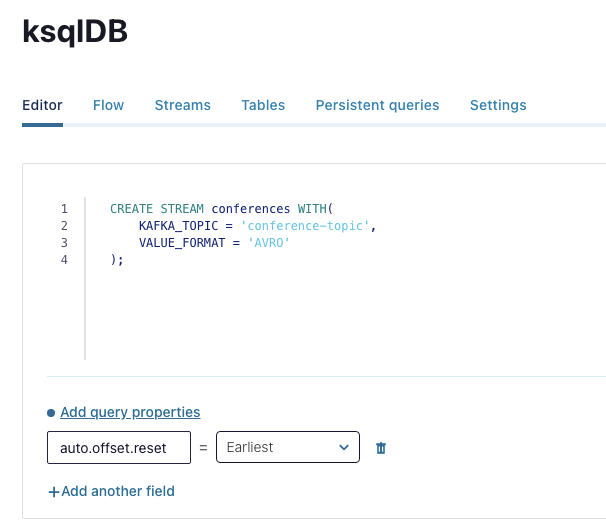
Now we need to query which of these conferences are bookable, and put them into another stream.
Like any good SQL engine, we can get the current time, and then compare that against the booking windows, by using another query:
CREATE STREAM current_conferences AS SELECT * FROM conferences
WHERE BOOKINGSTART < (UNIX_TIMESTAMP()/1000)
AND BOOKINGEND > (UNIX_TIMESTAMP()/1000)
EMIT CHANGES;
If you now query this new stream, you’ll see just the subset of the conferences that are actually accepting bookings.

As these queries are continuous, if you then add more conferences to the system, you’ll get more of the current events. If you modify the upstream windowing query by adding a time offset to the current timestamp, you can move the window through time and see the events in the current_conferences stream change.
Next, we have to make a table of bookings. For this purpose, we will join a stream of current conferences with a summation of all of the bookings for these conferences. To do this, first we sum up all of the bookings for each conference into a table with this query:
CREATE TABLE booking_list(
id bigint PRIMARY KEY
) WITH (
KAFKA_TOPIC = 'booking-topic',
VALUE_FORMAT = 'AVRO'
);
Then, to join them with the conferences stream, we only want the total number of bookings per conference (the user details should be dropped). The following query counts them up into buckets, using the eventID and the number of bookings:
CREATE TABLE bookings_per_event AS
SELECT eventID,
SUM(TICKETNUMBER) AS TOTAL_BOOKINGS
FROM BOOKINGS
GROUP BY eventID;
Now we have a table and a stream that share a common key which we can do a left join on. This is an example of classic enrichment-type processes that ksqlDB supports. There are many fancier ways to do this, and ways to include far more detailed data per message, but for the sake of simplicity and brevity, I won't go into additional details.
The join we are looking to do builds a new Kafka topic, which we can use as an output for the Ably Kafka Connector:
CREATE STREAM output_stream
WITH (kafka_topic='out-topic',
value_format='json') AS
SELECT current_conferences.EVENTID as id, EVENTCAPACITY, TOTAL_BOOKINGS, EVENTDATE, BOOKINGSTART, BOOKINGEND
FROM current_conferences
LEFT JOIN BOOKINGS_PER_EVENT ON current_conferences.EVENTID = BOOKINGS_PER_EVENT.EVENTID;
Note that we are using JSON as the output format; although we could send any data format into Ably, JSON is an open standard, and the default choice for web and mobile applications. It also makes the output human-readable.
Another thing worth mentioning is that ksqlDB is sending the output to an explicitly defined Kafka topic. We could configure ksqlDB to output directly to the Ably Kafka Connector; however, it makes more sense for the data to be written to a Kafka topic, since in a real-life scenario, you might have additional, non-Ably services connected to Kafka that are consuming that data.
We can now visualize the data stream in the “Flow” tab on the ksqlDB page in the Confluent Control Center.
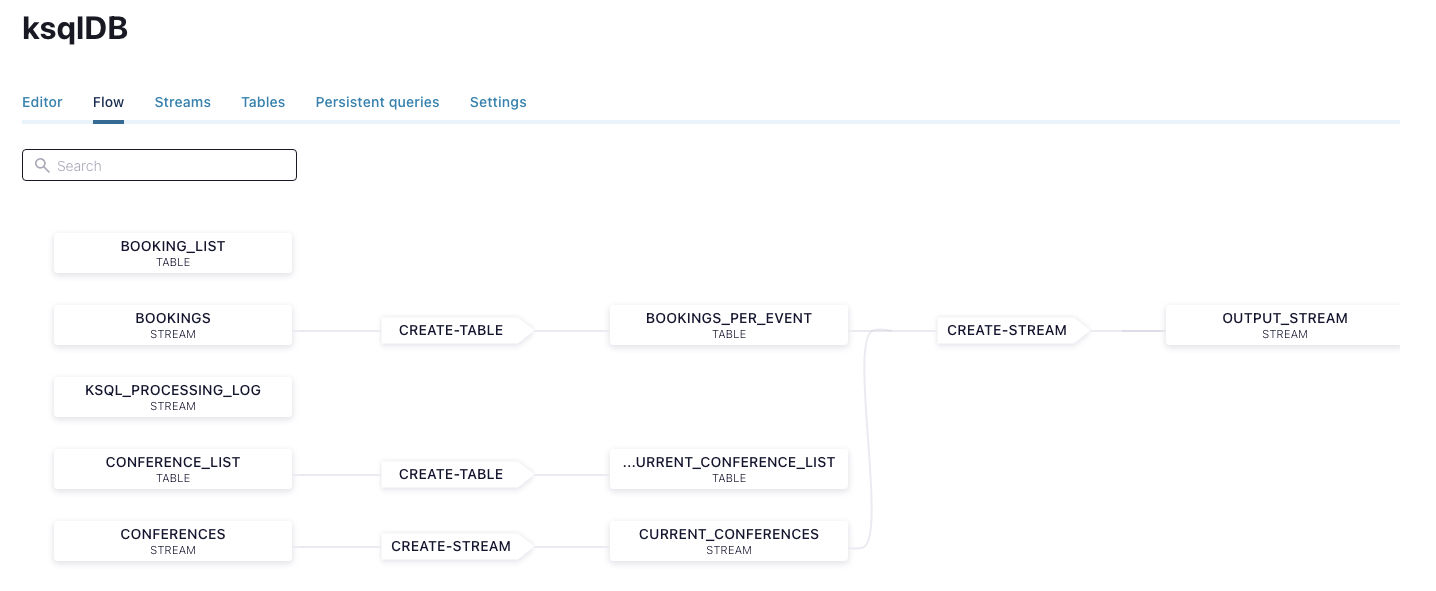
Finally, let’s now see how to configure sending data from Kafka into Ably via the Ably Kafka Connector. Once you’ve configured the ChannelSinkConnector we mentioned earlier in the guide, you need to select a name for the connector, and choose the topic(s) it should read from.
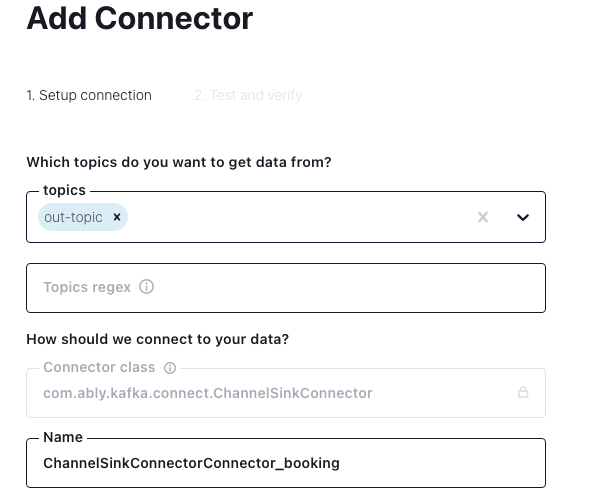
Then, there are several optional steps that we’ll skip, as the data we are dealing with is rather simple, and we already used ksqlDB to filter and enrich it.
The next required step is to add an Ably API key, choose an Ably channel to publish on, and give the connector an Id:

Once you have completed these mandatory steps, scroll to the bottom and click the Next button; you should see this screen:
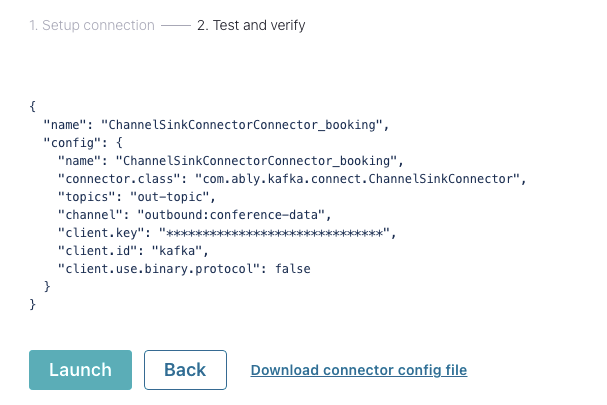
Note that you can download the connector config file in case you plan to use this setup outside of the Confluent Platform, or self-host the connector yourself.
Now, whenever conferences are added to your system and bookings are made, you’ll see the enriched stream of always-up-to-date data traveling through the Ably channel, ready to be delivered in realtime to any number of concurrent browsers and mobile app users.
Conclusion
The ticket booking solution we just built is deliberately simplistic. Several moving parts are involved: a REST API to create conferences, a realtime API to book tickets, and an event-driven layer to store and process data related to conferences and any changes it goes through.
Since the Kafka + ksqlDB engine allows you to do realtime processing on a continuous stream of conference-related data, it’s easy to add more functionality, such as waiting lists and the ability to cancel conferences.
Due to Kafka’s pub/sub nature, it’s also low-risk to add steps for handling payments and user management; all you have to do is put in some additional microservices (consumers and producers) between Kafka topics.
The dependability of the system is guaranteed by both Kaka and Ably. When hosted right, Kafka provides features such as low latency, high throughput and concurrency, fault tolerance, and high availability.
By using Ably as your public Internet-facing messaging layer, you benefit from a massively scalable global edge network built for high performance, unique data ordering and delivery guarantees that ensure seamless end-user experiences, and legitimate 99.999% uptime SLAs thanks to our fault tolerant infrastructure.
I hope this guide serves as a helpful description and walkthrough of building a dependable realtime ticket booking solution. Next, you can dive into the GitHub repository. You might also want to check out Ably Labs on GitHub, for more examples of what you can do with Ably.
Ably and Kafka resources
- Confluent Blog: Building a Dependable Real-Time Betting App with Confluent Cloud and Ably
- Extend Kafka to end-users at the edge with Ably
- How to stream Kafka messages to Internet-facing clients over WebSockets
- Dependable realtime banking with Kafka and Ably
- Building a realtime ticket booking solution with Kafka, FastAPI, and Ably
- Ably Kafka Connector
- Ably’s Kafka Rule
- Introducing the Fully Featured Scalable Chat App, by Ably’s DevRel Team
- Building a realtime chat app with Next.js and Vercel
- Ably pub/sub messaging
- Ably’s Four Pillars of Dependability


