
When building AI experiences, choosing between WebSockets and HTTP isn't always straightforward. Which protocol is better for streaming LLM responses? How do you maintain continuity when users switch devices mid-conversation? Should you use both?
The answer depends on the type of AI experience you're building. Modern AI applications often require both protocols, each serving different purposes. The key question is: how do you decide which communication pattern fits each scenario in your AI stack?
Here's everything you need to know.
WebSockets vs HTTP for AI at a glance
This guide explores how these protocols work in AI contexts, how they handle streaming responses and stateful conversations, and offers specific guidance on which to use for AI scenarios.
For a high-level comparison:
HTTP for AI Applications
What is HTTP in AI contexts?
HTTP is the standard protocol for client-server communication on the web. In AI applications, HTTP typically handles API requests where a client sends a prompt and receives a response.
When you interact with an AI chatbot on a website, that interaction often starts with an HTTP request to the LLM backend, which returns the generated response.
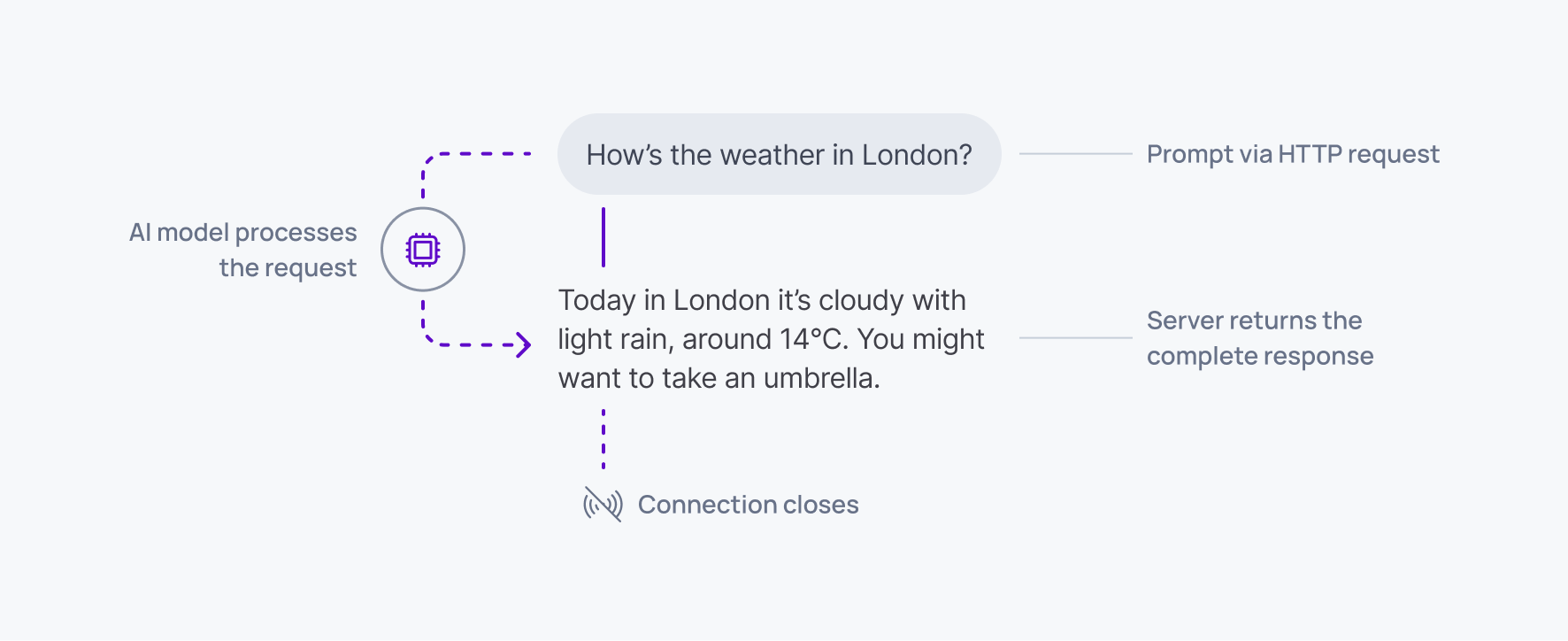
How does HTTP work for AI?
HTTP follows a request-response pattern. For AI applications, this means:
- Client sends a prompt via HTTP request
- AI model processes the request
- Server returns the complete response
- Connection closes
This works well for simple, stateless AI queries where each interaction is independent.
HTTP examples in AI:
- Single-shot question answering
- Batch processing of prompts
- API-based LLM calls for content generation
- Cached AI responses (like FAQ bots)
The stateless nature means each request is self-contained, making it easy to scale horizontally by adding servers without state synchronization. However, this also means you lose context between requests unless you explicitly include conversation history in each call.
Streaming AI responses with HTTP
Traditional HTTP request-response doesn't work well for LLM token streaming, where responses generate gradually over time. Users expect to see tokens appear as they're generated, not wait for the complete response.
HTTP streaming solves this through Server-Sent Events (SSE) or chunked transfer encoding. Instead of sending a complete response, the server keeps the connection open and streams partial responses as tokens are generated.
Limitations of HTTP streaming for AI
While HTTP streaming enables token-by-token rendering, it has fundamental constraints for modern AI experiences:
- Half-duplex limitation: HTTP is inherently half-duplex. Once streaming begins, the client cannot send steering commands, interruptions, or tool call results back to the agent without closing the stream and starting a new request.
- No cross-device continuity: If a user refreshes the page or switches devices, the stream breaks and context is lost. There's no native way to resume a streaming response.
- Stateful connection management: Despite HTTP being stateless, streaming requires the server to maintain long-lived connections, introducing scaling challenges and single points of failure.
- Limited multi-participant support: Broadcasting AI responses to multiple clients (for collaborative AI experiences) requires custom infrastructure.
For simple token streaming in single-device, single-user scenarios, HTTP streaming suffices. But for conversations that need steering, multi-device continuity, or collaborative AI, you'll need WebSockets.
WebSockets for AI Applications
What are WebSockets in AI contexts?
WebSockets provide persistent, bi-directional communication between clients and servers. For AI applications, this means maintaining a live connection throughout an entire conversation, enabling realtime token streaming, user steering, and stateful interactions.
Unlike HTTP's request-response pattern, WebSockets create an ongoing dialogue between user and AI agent, where messages can flow in either direction at any time.
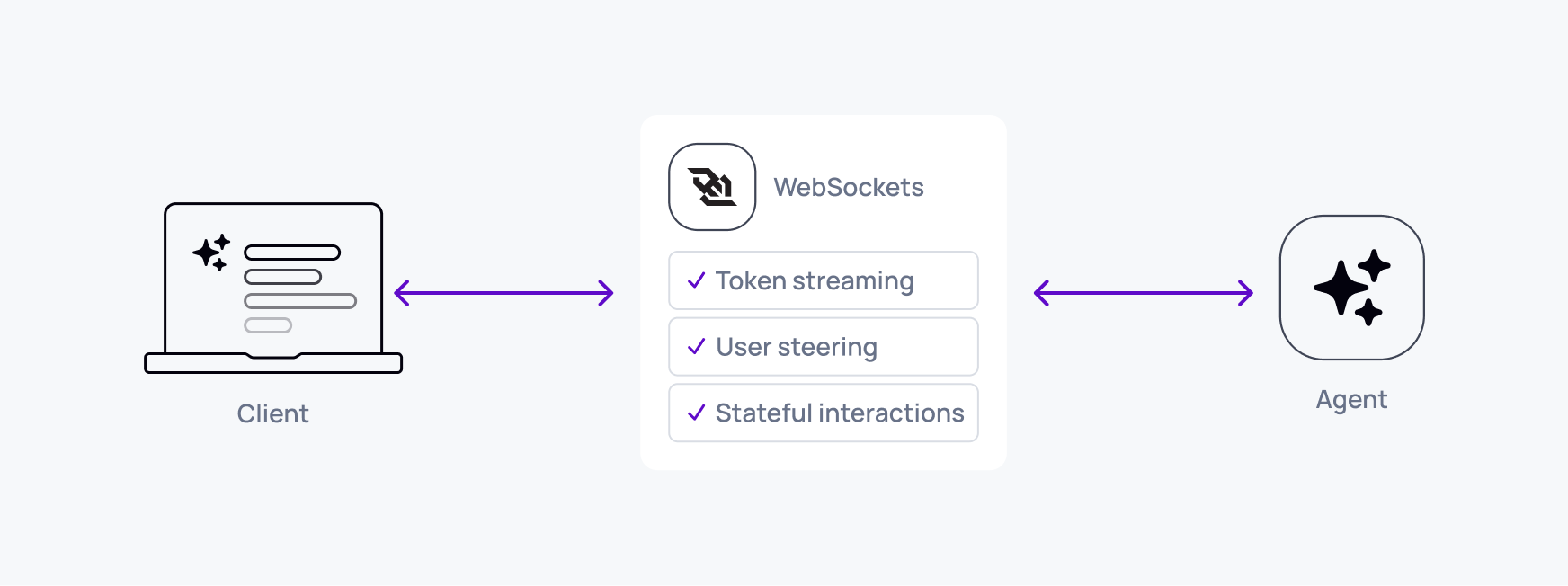
How do WebSockets work for AI?
WebSockets upgrade an HTTP connection to a persistent socket connection through an opening handshake. Once established:
- Client and AI agent maintain an open connection
- Agent streams tokens in realtime as they're generated
- Client can send steering commands, interruptions, or tool results anytime
- Connection persists across the entire conversation
- Either party can close when the conversation ends
Why WebSockets excel for conversational AI
The persistent, bi-directional nature of WebSockets makes them ideal for modern AI experiences:
Real-time steering and interruption: Users can redirect an agent mid-response, approve tool calls, or provide additional context without breaking the flow.
Multi-device continuity: The connection represents a session, not a physical network pipe. Users can switch devices and reconnect to the same session, continuing exactly where they left off.
Agentic workflows: Agents can request user input, wait for approval on sensitive actions, or coordinate with other agents in realtime, all over the same connection.
Presence awareness: The agent knows when users are actively engaged versus idle, enabling smart cost controls like pausing generation when no one's watching.
Tool calling patterns: When an agent needs to execute a tool, it can send the request over the WebSocket, wait for the client to execute it (with user permission), and receive results back without complex callback mechanisms.
Comparing HTTP vs WebSockets for AI
A helpful analogy: HTTP is like email, WebSockets are like a phone call.
HTTP for AI: When LLMs first became mainstream, most implementations used HTTP because they followed the pattern of traditional APIs: send a prompt, get a response. This works fine for one-off queries where context doesn't matter and users don't need to steer mid-generation.
WebSockets for AI: Modern AI experiences are conversational, long-running, and stateful. Users expect to interrupt agents, continue conversations across devices, and see transparent tool execution. WebSockets enable this by maintaining an open, two-way channel where the conversation unfolds naturally with minimal latency and maximum flexibility.
Which to choose: WebSockets or HTTP?
When HTTP is better for AI
- Stateless AI queries: Single-shot questions where each prompt is independent and doesn't require conversation history.
- Cacheable responses: FAQs or common queries where responses can be cached and reused, saving LLM costs.
- Batch processing: Processing large volumes of prompts asynchronously where realtime interaction isn't needed.
- Simple integrations: Quick prototypes or integrations where you just need basic LLM completion without advanced features.
- API endpoints: Building AI-powered APIs where clients expect traditional REST patterns.
When WebSockets are better for AI
- Conversational AI: Chat applications, virtual assistants, or any experience where context flows across multiple turns.
- Agentic workflows: AI agents that execute tools, require approvals, or coordinate with users in realtime.
- Live steering: Experiences where users need to interrupt, redirect, or provide feedback mid-generation.
- Multi-device AI: Applications where users start conversations on one device and continue on another seamlessly.
- Collaborative AI: Multiple users or agents participating in the same AI conversation simultaneously.
- Cost-aware agents: Systems that need presence awareness to pause generation when users aren't watching.
- Human-in-the-loop: Workflows requiring user approval before agents take actions, with full conversation context preserved.
WebSocket vs HTTP for AI: FAQ
Should I use WebSockets or HTTP for LLM streaming?
For basic one-way token streaming in single-device scenarios, HTTP streaming (SSE) works adequately. However, WebSockets are preferable when you need bi-directional communication for steering, tool calls, multi-device sync, or collaborative AI experiences.
Can I use HTTP for agentic AI workflows?
While technically possible, HTTP's request-response model makes agentic workflows complex and fragile. Each tool call, user approval, or steering command requires a new request, making it difficult to maintain conversational context and handle interruptions gracefully. WebSockets provide the persistent, bi-directional connection that agentic systems need.
How do I handle conversation state with HTTP vs WebSockets?
With HTTP, you must explicitly pass conversation history with every request or maintain state in external storage (database, cache). WebSockets can maintain state within the connection lifecycle, though production systems still benefit from durable state storage for crash recovery and cross-device continuity.
Do modern AI frameworks prefer WebSockets or HTTP?
Most modern AI frameworks support both. OpenAI, Anthropic, and others offer HTTP streaming APIs by default because they're simpler to get started with. However, frameworks like LangGraph, Vercel AI SDK, and others increasingly provide WebSocket patterns for building stateful, steerable AI experiences that feel continuous and responsive.
Building production AI experiences with Ably AI Transport
While WebSockets provide the right communication pattern for modern AI, building production-ready infrastructure involves significant complexity beyond the protocol itself: session continuity, multi-device sync, delivery guarantees, presence awareness, human handoff, observability.
Most teams start with raw WebSockets but quickly realize they're rebuilding the same infrastructure challenges that every AI application faces. Ably AI Transport provides a drop-in solution for these challenges, giving you:
- Durable, resumable token streaming that survives refreshes and reconnects
- Multi-device continuity so conversations follow users across tabs and devices
- Bi-directional session fabric for live steering, interruptions, and tool calls
- Presence-aware cost controls so agents know when to pause
- Framework-agnostic architecture that works with any LLM or agent framework
Whether you're building copilots, customer support agents, or collaborative AI tools, AI Transport handles the infrastructure complexity so you can focus on the AI experience itself.
Learn more about Ably AI Transport and how it provides the missing infrastructure layer for production AI applications. Get started with our AI Transport technical guides.


