

Your AI assistant is mid-sentence explaining a complex debugging strategy. The user refreshes the page. The response starts over from the beginning, or worse, vanishes entirely.
This isn't a model problem. It's a delivery problem.
What breaks
Most AI applications stream LLM responses over HTTP using Server-Sent Events (SSE) or fetch streams. The connection delivers tokens in order until the response completes. If the user refreshes, closes the tab, or loses network connectivity, the stream ends. When they reconnect, there's no mechanism to resume from where they left off.
The application has two options: start the entire response over (wasting tokens and user time) or lose everything that was streamed before the disconnection (losing context the user already read).
Neither option works in production. Users refresh pages. Networks drop. Browsers crash. Mobile apps background. These aren't edge cases.
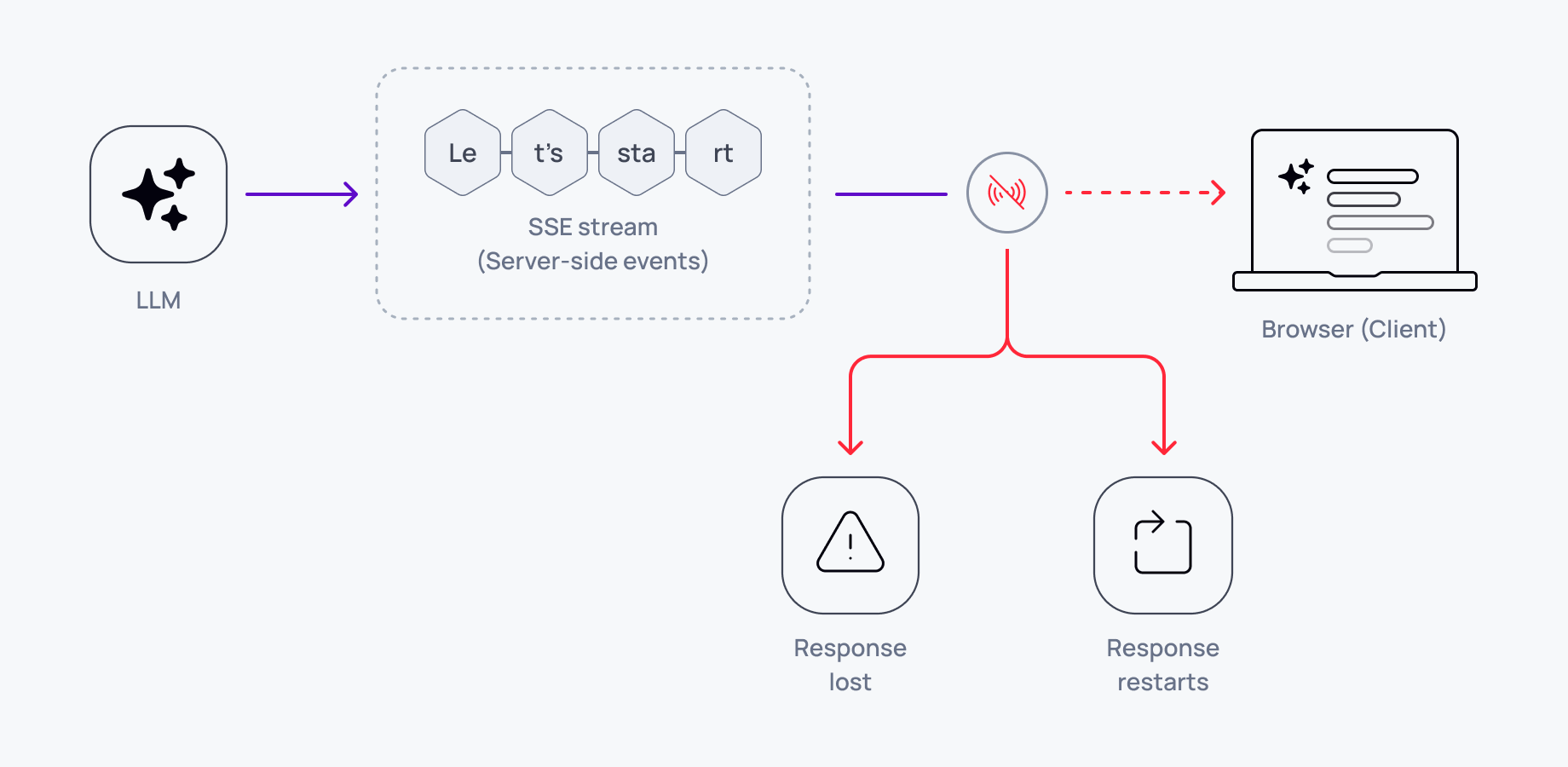
Why naive approaches fail
Client-side buffering: You can cache tokens in memory or localStorage, but this only handles intentional refreshes on the same device. It doesn't help with network interruptions, crashes, or users switching devices mid-conversation.
For a deeper comparison of buffering approaches, see AI chat stream resumption.
Response regeneration: Re-requesting the full response from the LLM costs tokens, adds latency, and often produces different output. The user sees the response change on reload, breaking continuity.
Stateless HTTP streaming: Standard SSE and fetch streams have no concept of session recovery. When the connection closes, the client has no way to tell the server "resume from token 847."
How resumable streaming actually works
The system needs three components:
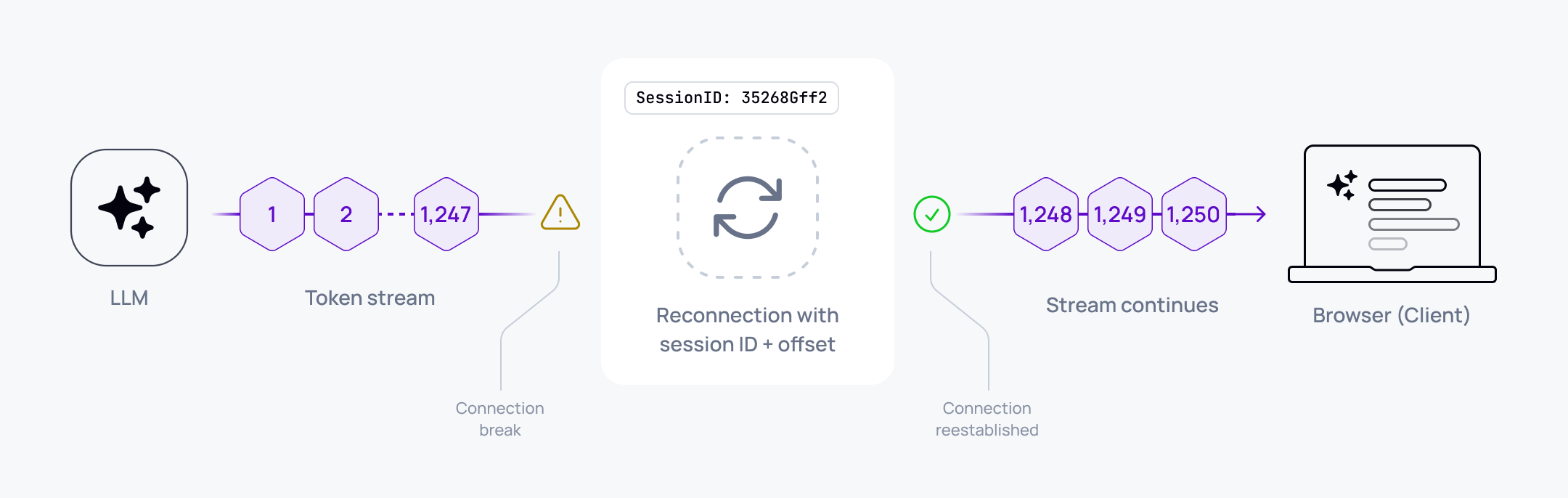
Session identity: Each AI response gets a unique session ID that persists across connections. When the client reconnects, it presents this ID to resume the same logical response.
Offset tracking: The server tracks which tokens have been delivered. The client tracks which tokens it has received and rendered. On reconnect, the client requests "start from token N."
Ordered delivery with history: The transport layer guarantees token ordering and maintains a replayable history. When a client reconnects with an offset, the server resumes delivery from that point without re-invoking the LLM.
Tradeoffs
Building this yourself means managing session state, handling offset synchronization across multiple connections, and ensuring tokens arrive in order even if network packets don't. You'll need persistent storage for token history and logic to handle race conditions when users reconnect from multiple tabs.
A concrete example
User asks an AI assistant to explain a codebase. The LLM streams 2,000 tokens over 30 seconds. At token 1,247, the user's network drops for eight seconds. Without resumability, the user sees a frozen response, then either loses everything or watches it restart.
With resumable streaming:
- The client detects the disconnection and stores offset 1,247
- Network recovers, client reconnects with session ID and offset
- Server resumes delivery from token 1,248
- User sees the response continue exactly where it stopped
The user never knows that there was an interruption.
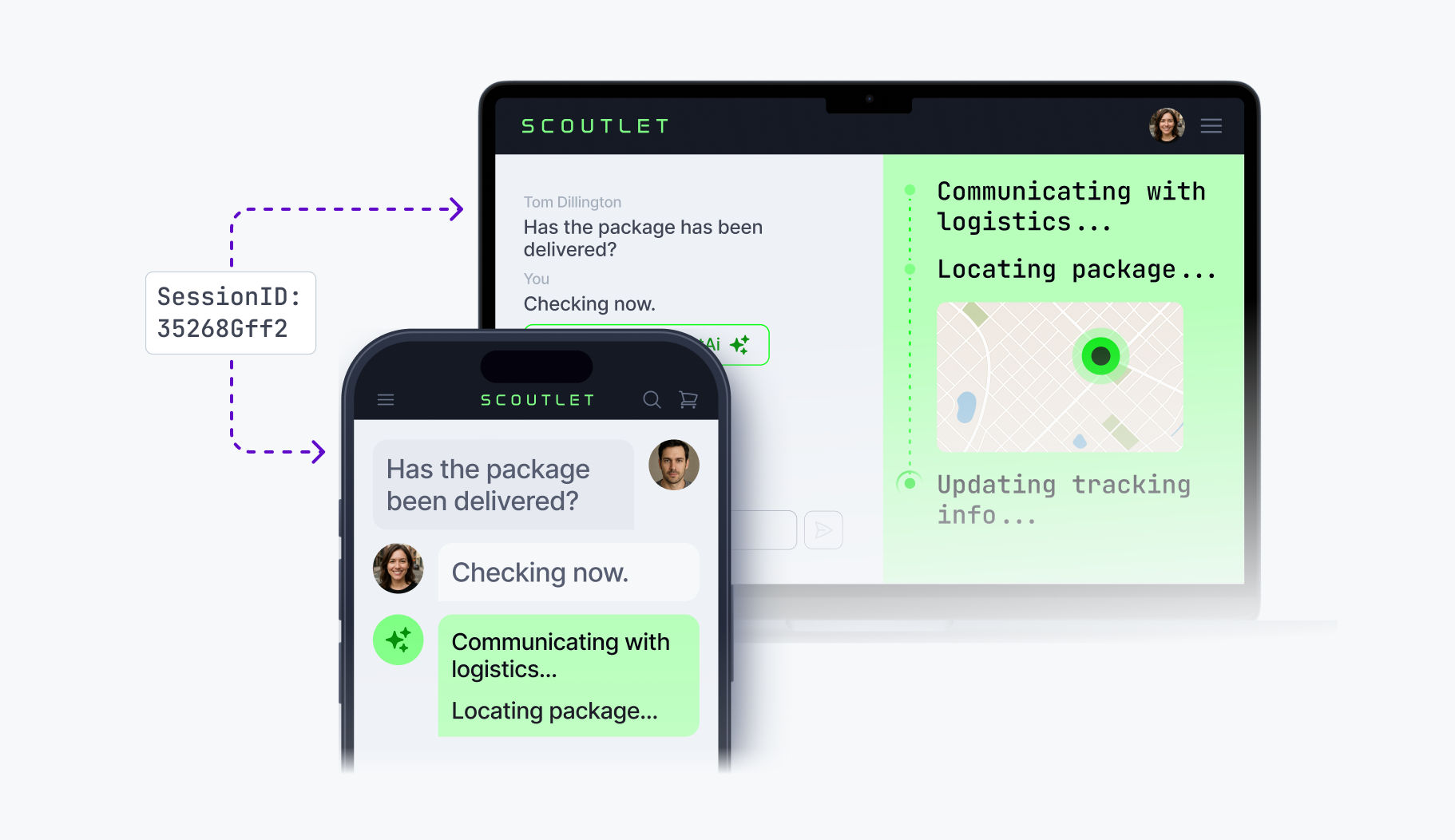
Multi-device continuity
Resumable streaming also enables conversation continuity across devices. The user starts a question on their laptop, switches to their phone, and sees the AI response pick up mid-stream. Same session ID, same offset tracking, different client.
This matters for AI workflows that span locations: research started at a desk, continued on a commute, finished in a meeting room. Without transport-level session management, each device restart loses context.
Next steps
If you're building AI features where responses take more than a few seconds, or where users might switch devices or encounter network issues, you need resumable streaming. You can build session management and offset tracking yourself, or use infrastructure like Ably AI Transport that handles it for you. The getting-started guide walks through the implementation with Vercel AI SDK.
For the conceptual overview of why streams break, see resumable token streaming. For the Redis build-vs-buy decision, see AI chat stream resumption.
Either way, design for reconnection from day one. Your users will refresh. Your network will drop. Production isn't a stable connection.
Frequently asked questions
How does Vercel AI SDK handle resumable streaming?
Vercel's resumable-stream package uses Redis to buffer tokens during page reloads. It covers single-device, same-tab recovery. For multi-device continuity or mobile backgrounding, you need infrastructure that decouples session state from the connection. Vercel designed a pluggable ChatTransport interface for this.
Does resumable streaming work across devices or just page reloads?
Page-reload recovery and multi-device resumption are different problems. Reload recovery reconnects to the same server-side buffer using a stored stream ID. Multi-device resumption requires a different architecture: Device B has no position in Device A's stream, so session state must be decoupled from the connection entirely. See cross-device AI sync for the full breakdown.


