
Streaming tokens is easy. Resuming cleanly is not. A user refreshes mid-response, another client joins late, a mobile connection drops for 10 seconds, and suddenly your “one answer” is 600 tiny messages that your UI has to stitch back together. Message history turns into fragments. You start building a side store just to reconstruct “the response so far”.
This is not a model problem. It’s a delivery problem.
That’s why we developed message appends for Ably AI Transport. Appends let you stream AI output tokens into a single message as they are produced, so you get progressive rendering for live subscribers and a clean, compact response in history.
The failure mode we’re fixing
The usual implementation is to stream each token as a single message, which is simple and works perfectly on a stable connection. In production, clients disconnect and resume mid-stream: refreshes, mobile dropouts, backgrounded tabs, and late joins.
Once you have real reconnects and refreshes, you inherit work you did not plan for: ordering, dedupe, buffering, “latest wins” logic, and replay rules that make history and realtime agree. You can build it, but it is the kind of work that quietly eats weeks of engineering time.
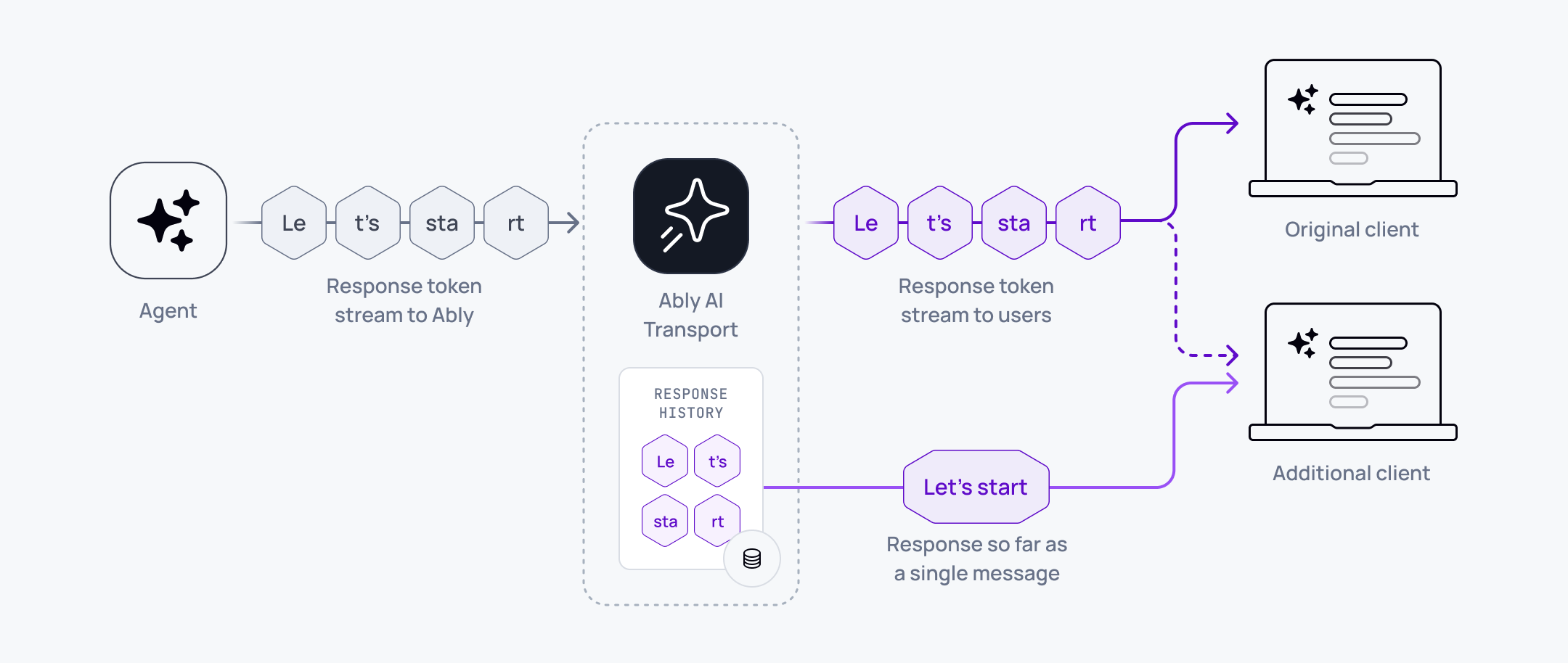
With appends you can avoid that by changing the shape of the data. Instead of hundreds of token messages, you have one response message whose content grows over time.
The pattern: create once, append many
In Ably AI Transport, you publish an initial response message and capture its server-assigned serial. That serial is what you append to.
It’s a small detail that ends up doing a lot of work for you:
const { serials: [msgSerial] } = await channel.publish({ name: 'response', data: '' });
Now, as your model yields tokens, you append each fragment to that same message:
if (event.type === 'token') channel.appendMessage({ serial: msgSerial, data: event.text });
What changes for clients
Subscribers still see progressive output, but they see it as actions on the same message serial. A response starts with a create, tokens arrive as appends, and occasionally clients may receive a full-state update to resynchronise (for example after a reconnection).
Most UIs end up implementing this shape anyway. With appends, it becomes boring and predictable:
switch (message.action) {
case 'message.append': renderAppend(message.serial, message.data); break;
case 'message.update': renderReplace(message.serial, message.data); break;
}
The important difference is that history and realtime stop disagreeing, without your client code doing any extra work. You render progressively for live users, and you still treat the response as one message for storage, retrieval, and rewind.
Reconnects and refresh stop being special cases
Short disconnects are one thing. Refresh is the painful case, because local state is gone and to stream each token as a single message forces you into replaying fragments and hoping the client reconstructs the same response.
With message-per-response, hydration is straightforward because there is always a current accumulated version of the response message. Clients joining late or reloading can fetch the latest state as a single message and continue.
Rewind and history become useful again because you are rewinding meaningful messages, not token confetti:
const channel = realtime.channels.get('ai:chat', { params: { rewind: '2m' } });
Token rates without token-rate pain
Models can emit tokens far faster than most realtime setups want to publish. If you publish a message per token, rate limits become your problem and your agent has to handle batching in your code.
Appends are designed for high-frequency workloads and include automatic rollups. Subscribers still receive progressive updates, but Ably can roll up rapid appends under the hood so you do not have to build your own throttling layer.
If you need to tune the tradeoff between smoothness and message rate, you can adjust appendRollupWindow. Smaller windows feel more responsive but consume more message-rate capacity. Larger windows batch more aggressively but arrive in bigger chunks.
Enabling appends
Appends require the “Message annotations, updates, appends, and deletes” channel rule for the namespace you’re using. Enabling it also means messages are persisted, which affects usage and billing.
Why this is a better default for AI output
If you are shipping agentic AI apps, you eventually need three things at the same time:
- streaming UX
- history that’s usable
- recovery that does not depend on luck
Appends are how you get there without building your own “message reconstruction” subsystem. If you want the deeper mechanics (including the message-per-response pattern and rollup tuning), the AI Transport docs are the best place to start.


