

Start typing, change your mind, and redirect the AI mid-response. It just works. That is the promise of realtime steering. Users expect to interrupt an answer, correct its direction, or inject new instructions on the fly without losing context or restarting the session. It feels simple, but delivering it requires low-latency control signals, reliable cancellation, and shared conversational state that survives disconnects and device switches. This post explores why expectations have shifted, why today’s stacks struggle with these patterns, and what your infrastructure needs to support proper realtime steering.
What’s changing
AI tools are moving beyond static, one-turn interactions. Users expect to interact dynamically, especially in chat. But most AI systems today force users to wait while the assistant responds in full, even if it's off-track or no longer relevant. That’s not how human conversations work.
Expectations are shifting toward something more natural. Users want to jump in mid-stream, adjust the AI’s course, or stop it altogether. These patterns (barge-in, redirect, steer) are becoming table stakes for responsive, agentic assistants.
What users want, and why this enhances the experience
Users want to stay in control of the conversation. If the AI starts drifting, they want to say “stop” or “try a different angle” and get an immediate course correction. They want to guide the assistant’s direction without breaking the flow or starting over.
This improves trust, keeps sessions on-topic, and avoids wasted time. It also brings AI interactions closer to how real collaboration works: iterative, reactive, fast.
Users now expect a few technical behaviours as part of that experience:
- Responses can be interrupted in real time
- New instructions are applied mid-stream without reset
- The AI keeps context and adjusts without losing the thread
Why realtime steering is proving hard to build
Most AI systems treat generation as a one-way stream. Once the model starts producing tokens, the system just plays them out to the client. If the user wants to interrupt or change direction, the only real option is to cancel and resend a new prompt - often from scratch. That’s because most systems today cannot support mid-stream redirection because their underlying communication model does not allow it.
Stateless HTTP cannot carry steering signals
Traditional request–response models push output in one direction only. Once a long-running generation begins, there is no reliable way to send control signals back to the server. Cancelling or redirecting usually means tearing down the stream and starting again.
Browser-held state breaks immediately
Most apps keep the state of an active generation in the browser. If the user refreshes or switches device, the in-flight response loses continuity. Any client-side steering logic tied to that state vanishes too, which forces a full reset.
Backend models often run without shared conversational state
If the orchestration layer is not tracking what the AI is currently doing, it cannot apply corrections cleanly. The model receives a brand-new prompt instead of a context-preserving instruction layered onto an active task.
The default stack was never designed for low-latency control loops
Steering requires coordinated signalling between UI, transport, orchestration, and model inference. That means ordering guarantees, durable state, and fast propagation of control messages. Without these, the AI continues generating tokens after a user says stop, causing confusion and wasted compute.
Steering mid-stream looks like a simple UX gesture. It is not. It is a distributed-systems problem sitting under a conversational interface.
Why you need a drop-in AI transport layer for steering
Delivering realtime control requires more than token streaming. It requires a transport layer that keeps context alive, supports low-latency bidirectional messaging, and ensures that user instructions and model output remain synchronised.
Bi-directional, low-latency messaging
Client-side signals such as “stop” or “try this instead” must reach the backend quickly and reliably. WebSockets or similar long-lived connections make this possible by enabling client-to-server control while the AI continues to stream output.
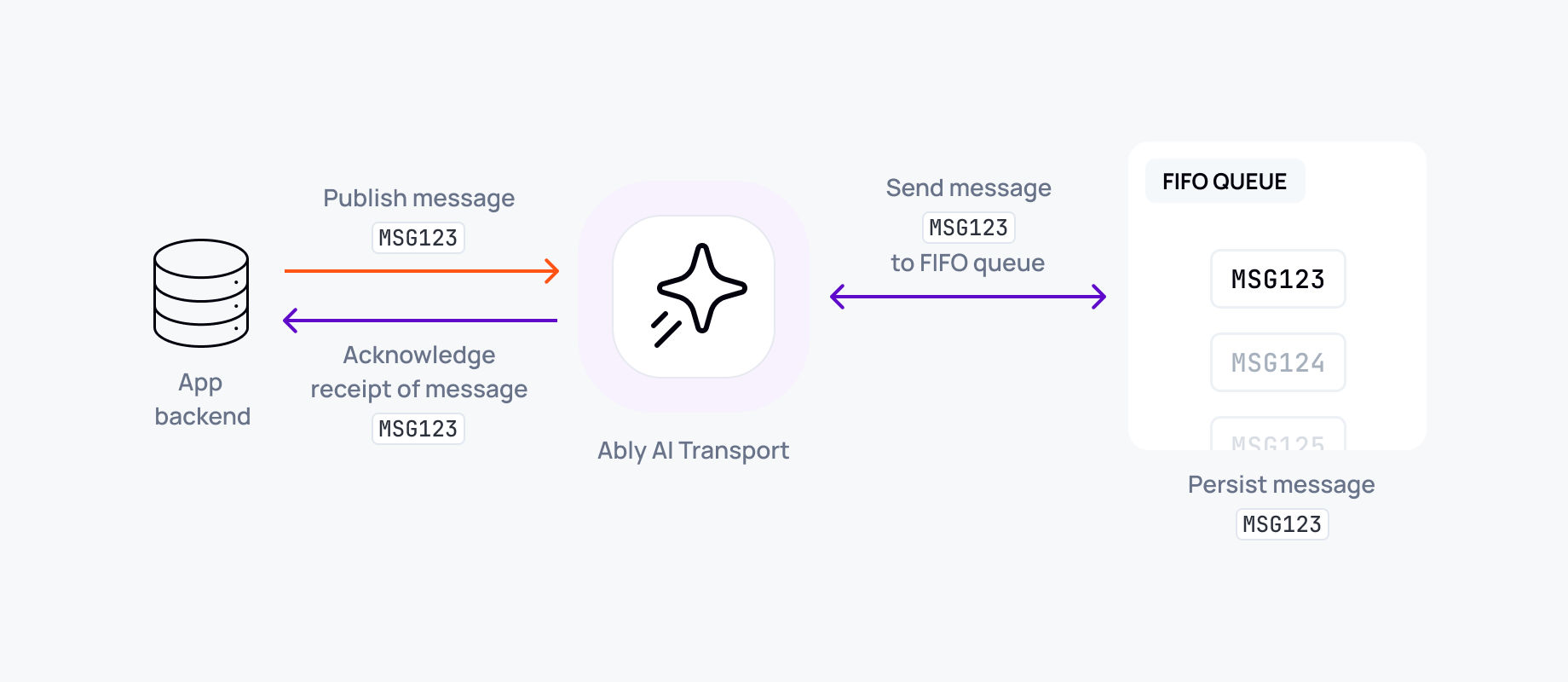
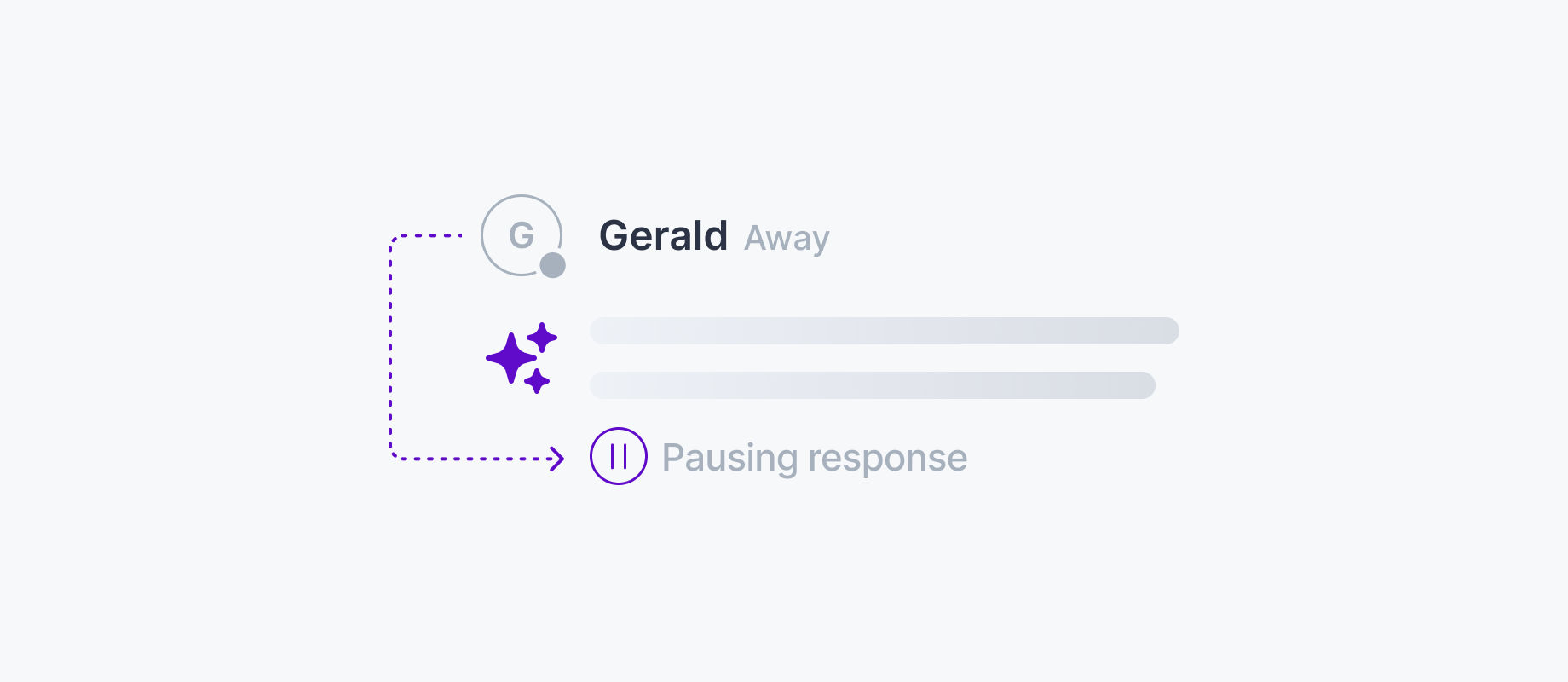
Reliable interrupt and cancellation primitives
Stopping generation must be instant and clean. The transport must carry cancellation events with ordering guarantees so the backend halts inference exactly where intended, without corrupting state.
Session continuity
The system needs persistent session identity so instructions and outputs are tied to the same conversational thread. Redirection should extend the session, not rebuild it.
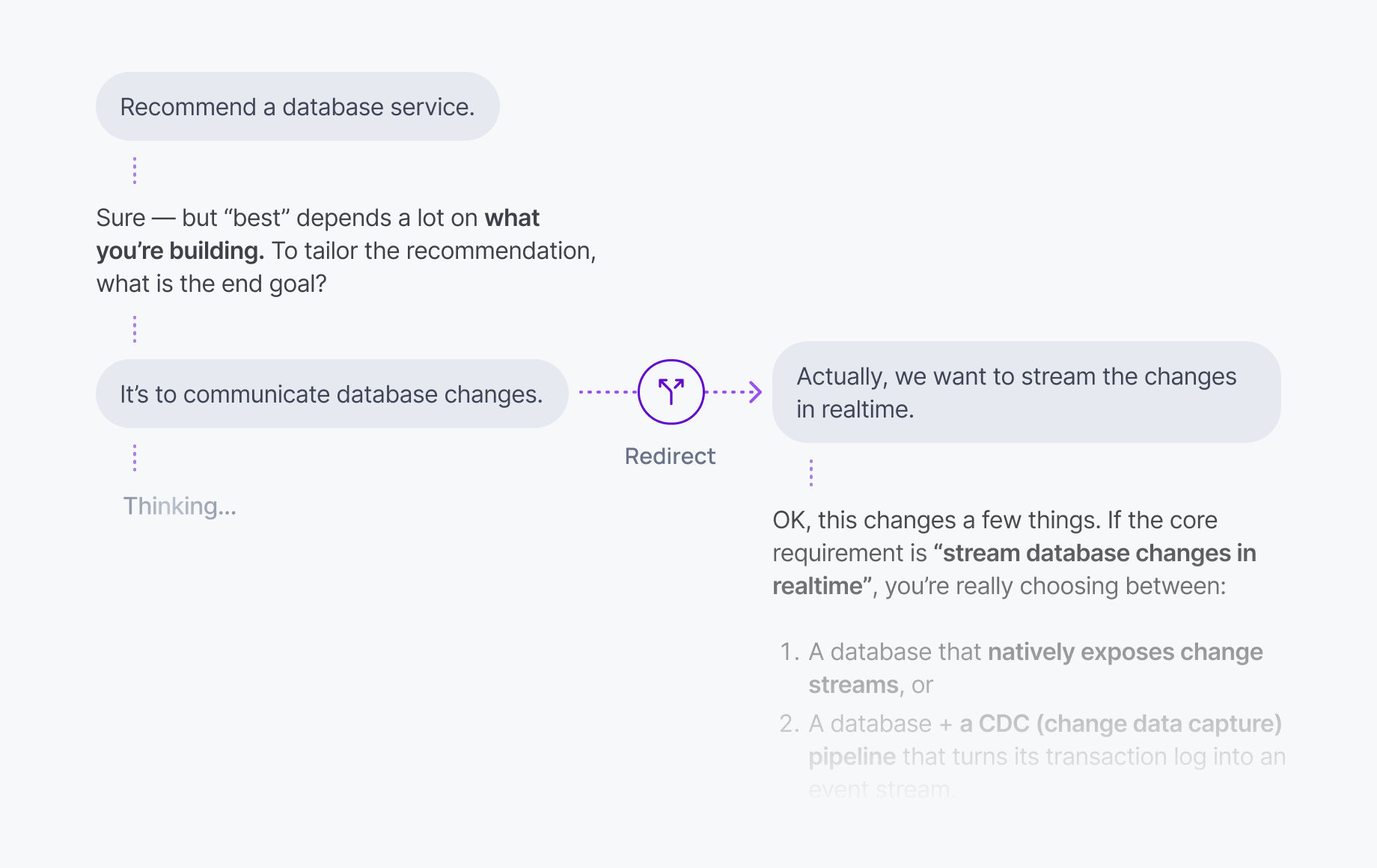
Presence and focus tracking
If users have multiple tabs or devices open, the system needs to know where instructions are coming from. Steering messages must route to the correct active session without collisions.
Realtime steering relies on a transport layer designed for conversational control, not just message delivery.
How the experience maps to the transport layer
Realtime steering for AI you can ship today
You don’t need a new architecture to support real-time steering, cancellation, or recovery. You need a transport layer that can keep the session alive, deliver messages in order, and preserve state across disconnects. Ably AI Transport provides those foundations out of the box, so you can build controllable, resilient AI interactions without rebuilding your entire stack.
Sign-up for a free account and try today.


