

Kafka is a highly popular realtime data streaming platform, renowned for handling massive volumes of data with minimal latency. Typical use cases include handling user activity tracking, log aggregation and IoT telemetry. Kafka’s architecture, based on distributed partitions, allows it to scale horizontally across multiple brokers. But although Kafka excels at high data throughput, scaling it to manage thousands of client connections can be costly and complex. Kafka’s architecture is designed for efficient data processing, not for handling high volumes of connections. When Kafka is scaled primarily to support more connections, this can lead to unnecessary resources and scale, ultimately raising costs due to inefficient resource usage.
Many organizations choose to offload client connections to a connection management service to optimize scaling for Kafka. These services can work particularly well for managing high numbers of consumer and producer connections, while optimizing Kafka infrastructure for high data throughput.
This article explores how combining Kafka with WebSockets allows developers to scale Kafka efficiently for throughput by using a WebSocket layer to handle client connections.
We’ll dive deeper into how Kafka and WebSockets complement each other in the next section.
Kafka and WebSockets
Kafka's architectural limitations
Kafka was originally designed for closed internal enterprise environments. This leads to architectural constraints when interfacing with high numbers of external consumers or producers. The architecture becomes especially challenging in scenarios where thousands—or even millions—of concurrent connections are required. Some of those limitations include:
- Broker connection limits: Each Kafka broker has a connection cap, typically handling between 2,000 to 5,000 concurrent connections. When demand exceeds this limit, Kafka adds new brokers, which increases complexity and cost.
- Lack of elasticity: Kafka's architecture isn’t dynamically elastic, meaning it doesn’t automatically scale up or down in response to fluctuating connection loads. Any scaling adjustments require manual intervention, which can lead to delays and additional operational overhead.
- Resource under-utilization: To meet capacity demands when connection limits are reached, new brokers have to be added, even if additional data throughput isn’t needed. This can lead to resource inefficiencies, as brokers are added for capacity rather than throughput.
- Operational complexity and latency spikes: Frequently scaling Kafka brokers in or out introduces operational risk, since scaling requires data rebalancing each time a new broker is added or removed. This rebalancing process can temporarily cause latency spikes, impacting the performance of realtime data streams.
Using WebSockets to stream Kafka messages
To make Kafka work in a public-facing context and address some of its limitations, you could offload client connections by using one of many open-source solutions for streaming messages to internet-facing clients, to offload the burden of managing client connections.
Many of these solutions are WebSocket-based. WebSockets are well-suited for streaming Kafka messages in realtime, thanks to several properties:
- Realtime bi-directional communication: WebSockets support full-duplex connections, enabling data to flow between client and server in realtime. This is ideal for applications like live chat, gaming, dashboards, and collaborative tools, where realtime data flow is critical.
- Single, long-lived connections: Unlike protocols that rely on multiple requests, WebSockets use a single long-lived connection. This approach minimizes the setup and teardown costs associated with high volumes of connections, saving resources and reducing latency, particularly in applications with large numbers of concurrent users.
- Independent scaling for data ingestion and delivery: By introducing a tier of WebSocket servers, you decouple the data processing layer (Kafka) from the connectivity layer (WebSocket servers). This means you can scale each layer independently—Kafka can handle data processing, while WebSocket servers focus on efficiently delivering messages to clients.
- Complex subscription support: Kafka’s pub/sub model aligns well with WebSocket-based subscription handling. By replicating the pub/sub pattern in the WebSocket tier, you can efficiently route data between Kafka and WebSocket clients, ensuring data is only sent to the right consumers.
While WebSockets provide a great choice for integrating with Kafka, and enable you to take advantage of these properties, you then have the problem of how to scale your WebSocket application tier efficiently. This is potentially far more complex than it first seems, as we still have to consider elasticity, persistence, resilience, availability and latency in our infrastructure. WebSockets can also scale with backend technologies like Redis. For more information on scaling WebSockets specifically, check out our engineering blog post and video on the topic.
An example
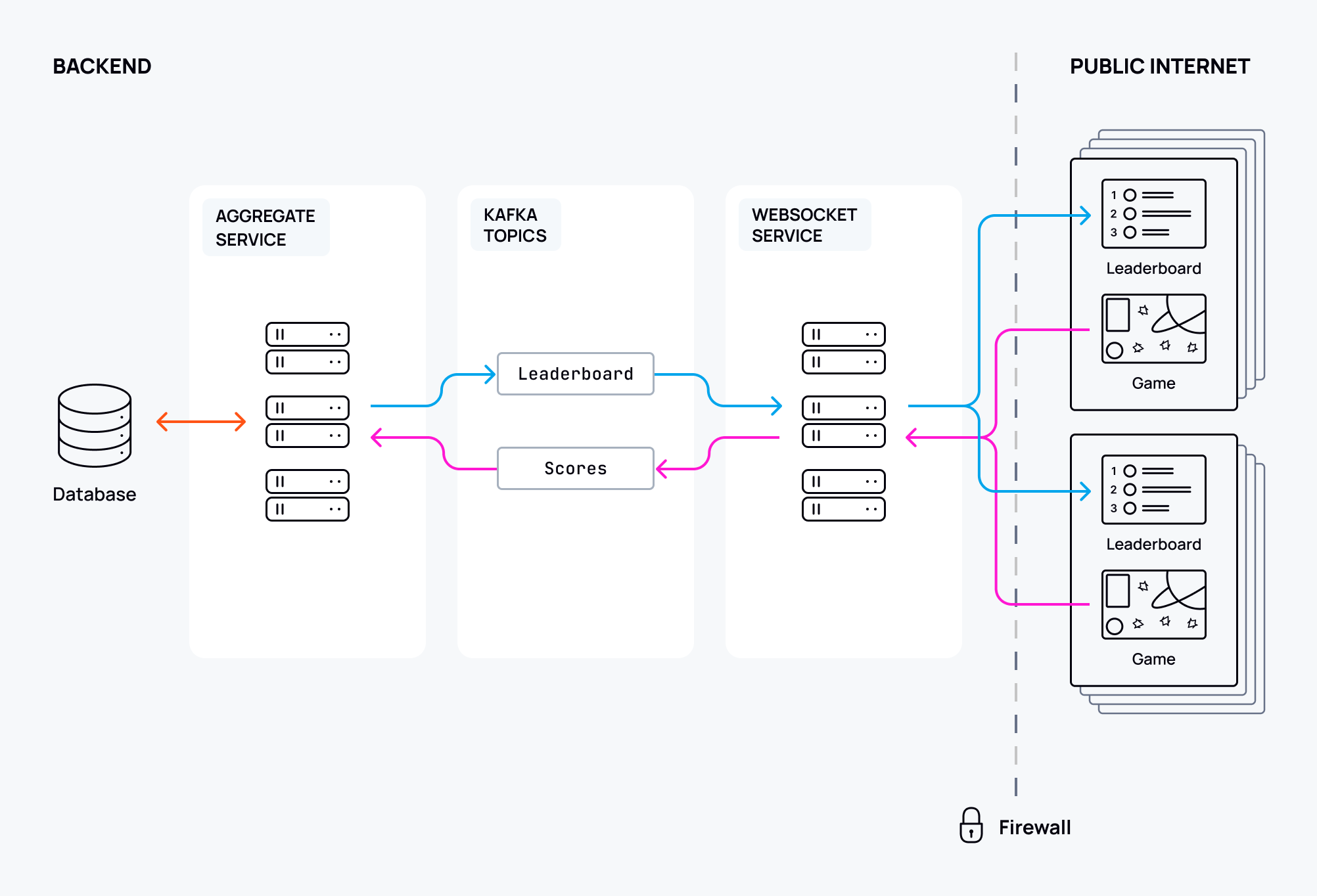
Imagine we have a simple gaming application where player scores are updated on a shared leaderboard. The leaderboard displays the current top ten players. I’ll leave the nature of the game to your imagination, but let’s assume that we have thousands of players, and the competition is strong.
In terms of the architecture required, we’ll need a central service that aggregates user scores and maintains the leaderboard, posting updates at regular intervals.
We’ll use Kafka to process incoming scores from players, and to push leaderboard updates to players. So, the aggregation service will:
- consume score messages from the
score-ingestiontopic, - update player scores,
- store the scores in a database, and
- calculate a new leaderboard at regular intervals and push to the
leaderboard-updatetopic.
In this example, you could use a scalable WebSocket application tier to distribute leaderboard updates to players and push score updates for aggregation. This WebSocket layer allows players to publish their score messages directly to the score-ingestion topic, and receive score updates by consuming messages from the leaderboard-update topic. Here’s what that looks like:
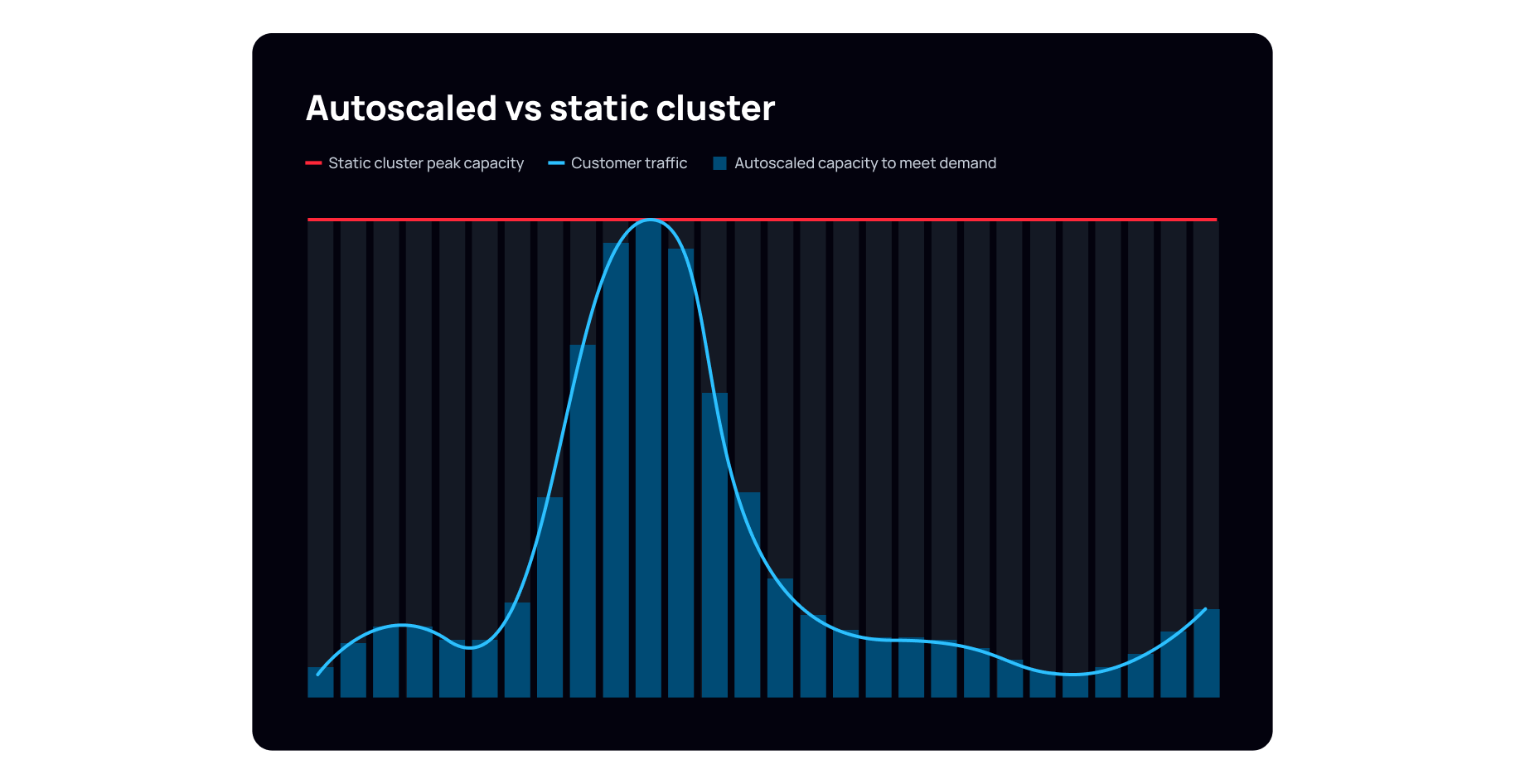
Now, let’s say our gaming app needs to handle 50,000+ concurrent client connections to stream realtime data globally. If we used Kafka alone to handle both the connections and data throughput, we’d need to scale Kafka brokers well beyond what is required for data processing.
For example, a Kafka cluster might need 25 or more brokers (assuming a limit of 2,000 concurrent connections per broker) just to accommodate the client connections, even though just 5 brokers are sufficient to handle the actual data ingestion and streaming workloads. By offloading the connection management to a WebSocket layer, we can deploy a Kafka cluster with just those 5 brokers to handle the data throughput, while our WebSockets application tier manages the 50k+ connections. This approach would result in significant cost savings, as the infrastructure for Kafka is scaled only for the data it processes, not for the volume of connections.
Scaling with a connection management service
As we discovered earlier, while scaling Kafka is complex, scaling a WebSocket service is itself is also a challenge. Managing connection limits, handling reconnections, and maintaining global low-latency service requires significant engineering expertise and operational overhead. You could instead turn to connection management services that specialize in scaling WebSocket infrastructure. By offloading WebSocket connections to a dedicated service, you can focus on optimizing core data processing (e.g., within Kafka), while the connection management service handles the challenges of scalability, elasticity, and fault tolerance. This approach often proves more cost-effective and efficient than building and maintaining a custom infrastructure.
Here at Ably, we have Kafka integrations that enable you to manage WebSocket connections while optimizing your Kafka clusters for data throughput at the same time. Let’s explore them below.
How Kafka and Ably work together
Ably has two features that enable connectivity between Kafka and clients: the Ably Kafka Connector and the Ably Firehose Kafka rule.
The Ably Kafka Connector provides a ready-made integration between Kafka and Ably. It allows for realtime event distribution from Kafka to web, mobile, and IoT clients over Ably’s feature-rich, multi-protocol pub/sub channels. You can use the Ably Kafka Connector to send data from one or more Kafka topics into Ably Channels.
The connector is built on top of Apache Kafka Connect, and can be run locally with Docker, installed into an instance of Confluent Platform, or attached to an AWS MSK cluster through MSK Connect.
If instead you need to send data from Ably to Kafka, use an Ably Firehose Kafka rule. You can use a Kafka rule to send data such as messages, occupancy, lifecycle and presence events from Ably to Kafka. Setting up a Firehose rule is as simple as completing a form in your Ably dashboard:
Kafka-Ably architecture
The architecture of integrating Kafka and Ably leverages each platform’s strengths: Kafka manages data stream processing and storage, while Ably connects with Kafka by acting as either a publisher or consumer of Kafka topics. This setup allows each system to focus on what it does best, creating a more efficient and scalable solution for handling high volumes of realtime data.
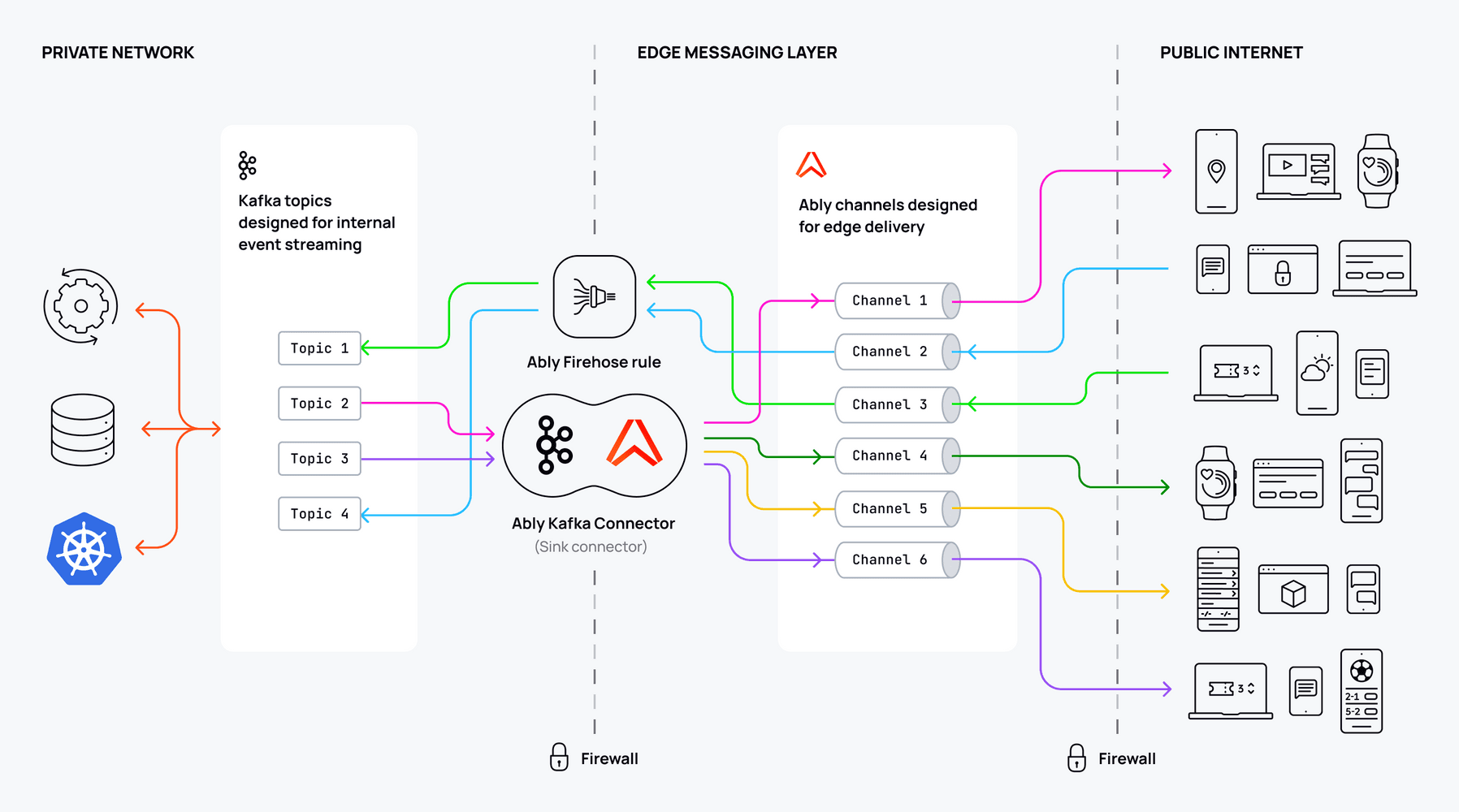
As new messages are produced in Kafka, Ably consumes them through the Ably Kafka Connector, converting them into realtime updates that are then relayed to end-users through WebSockets. Or, alternatively, as new messages are produced in Ably, Ably can send these to Kafka topics configured in a Kafka Firehose rule.
This allows Ably to push realtime data to clients—whether they are mobile apps, web browsers, or IoT devices—without Kafka needing to handle direct client connections.
A note on security
One of the core advantages of Kafka is its ability to be deployed securely in on-premise or private cloud environments, where Kafka brokers are kept behind firewalls and protected from external threats. In these setups, Kafka brokers are not exposed directly to the internet, which enhances security, particularly for enterprises handling sensitive data. However, in scenarios where Kafka needs to serve a global audience, directly exposing brokers to the internet can introduce security risks and complexity.
With Ably acting as an intermediary, Kafka brokers do not need to be exposed to the public internet. Ably's secure edge network handles the global client connections, while Kafka remains securely deployed within the organization’s on-premise infrastructure or private cloud. Ably relays data between Kafka and external clients in realtime, ensuring that Kafka is never exposed to potential cyber threats from public networks. For example, Ably Kafka Firehose rules can connect to Kafka clusters over AWS PrivateLink to achieve private connectivity within AWS.
Getting started with Ably
As we’ve seen, scaling Kafka with WebSockets, while avoiding the pitfalls of under-utilizing Kafka resources, can be a complex task. Each layer requires considerable engineering effort to build out, so if you’re considering a connection management service to offload to, Ably's Kafka solutions are designed to handle precisely these use cases.
Explore the Kafka Connector by reading our docs or by following our Kafka Connector setup tutorial. To get started with Ably more generally, check out our quickstart guide. With the Connector in place, connecting WebSocket clients to Kafka becomes as simple as connecting to Ably.
Sign up for a free account to try it for yourself.


