

Refresh the page, lose signal, switch tabs. The AI conversation just keeps going. That's what resumable token streaming makes possible: no restarts, no lost context, the same response picking up right where it left off. Whether you're building an AI assistant, a customer support agent, or a multi-step research tool, the expectation is the same. The stream should survive whatever the network throws at it.
This post covers why AI token streams break on reconnection, what makes the problem hard at the infrastructure level, and what your transport layer needs to make streaming resumable.
Key takeaways
- AI token streams break on page reload because HTTP ties each stream to a single connection. When the connection dies, undelivered tokens are lost.
- Resumable streaming requires four things: persistent connections, server-side output buffering, session tracking across restarts, and ordered exactly-once delivery.
- In AI customer support, a dropped stream means a customer waiting for a resolution that never arrives, an agent re-running inference at double the cost, and an enterprise proxy that caused the failure in the first place.
- Most teams building resilient streaming independently arrive at the same architecture: decouple generation from the client connection and buffer output server-side.
Why do AI token streams break?
An AI support agent is streaming a resolution to a billing query. The enterprise proxy terminates the SSE connection after 30 seconds of apparent inactivity. The customer sees a frozen response. When they refresh, the resolution is gone, and the support team pays for the same tokens twice.
Most web stacks were never designed for this kind of continuity. Three things break.
Stateless protocols like HTTP drop the stream on failure
If you're streaming an AI response over a standard HTTP connection and it drops, that request is gone. HTTP has no native concept of resuming a half-finished response. It wasn't designed for long-lived, continuous streams.
In enterprise environments, the problem is worse. Corporate proxies and load balancers actively terminate idle SSE connections, sometimes within 30 seconds.
For specific timeout values and the server-side ping fix, see WebSocket reconnection in AI agents.
Streaming logic often lives only in the browser
If the browser tab crashes or closes, any awareness of the current conversation state disappears. Unless the server is explicitly maintaining progress (e.g. buffering the partial response), the result is a hard reset. Even a minor network blip or a page reload can cause the entire generation to be lost, forcing the user to re-issue the prompt and wait again. From the developer's side, this means wasted tokens and potentially double the LLM costs for the same request.
Server infrastructure rarely stores stream state by default
Even when WebSockets or similar protocols are used, many backends treat streaming as fire-and-forget. Once tokens are emitted, they're not stored. If a client reconnects and asks "what did I miss?", the server has no answer unless a stateful resume mechanism is in place. That means tracking client progress, buffering streamed output, handling retries, and ensuring correct ordering. None of which are trivial to bolt on after the fact.
Building this kind of infrastructure requires careful design, and is one reason robust streaming support remains rare despite user demand. It is also why the question of whether WebSockets alone are sufficient matters.
What does resumable streaming infrastructure look like?
The fix is a transport layer: infrastructure between your AI backend and the client that manages connections, buffering, and delivery independently of either. It needs to handle four things that HTTP streaming does not.
Persistent streaming connections
Instead of one-request-per-response, the client uses a persistent connection (e.g. WebSocket) that stays open for streaming. A persistent channel enables realtime, bi-directional delivery and guarantees in-order arrival of tokens. If the connection breaks, the protocol can attempt automatic reconnection without starting a new session from scratch. See token streaming.
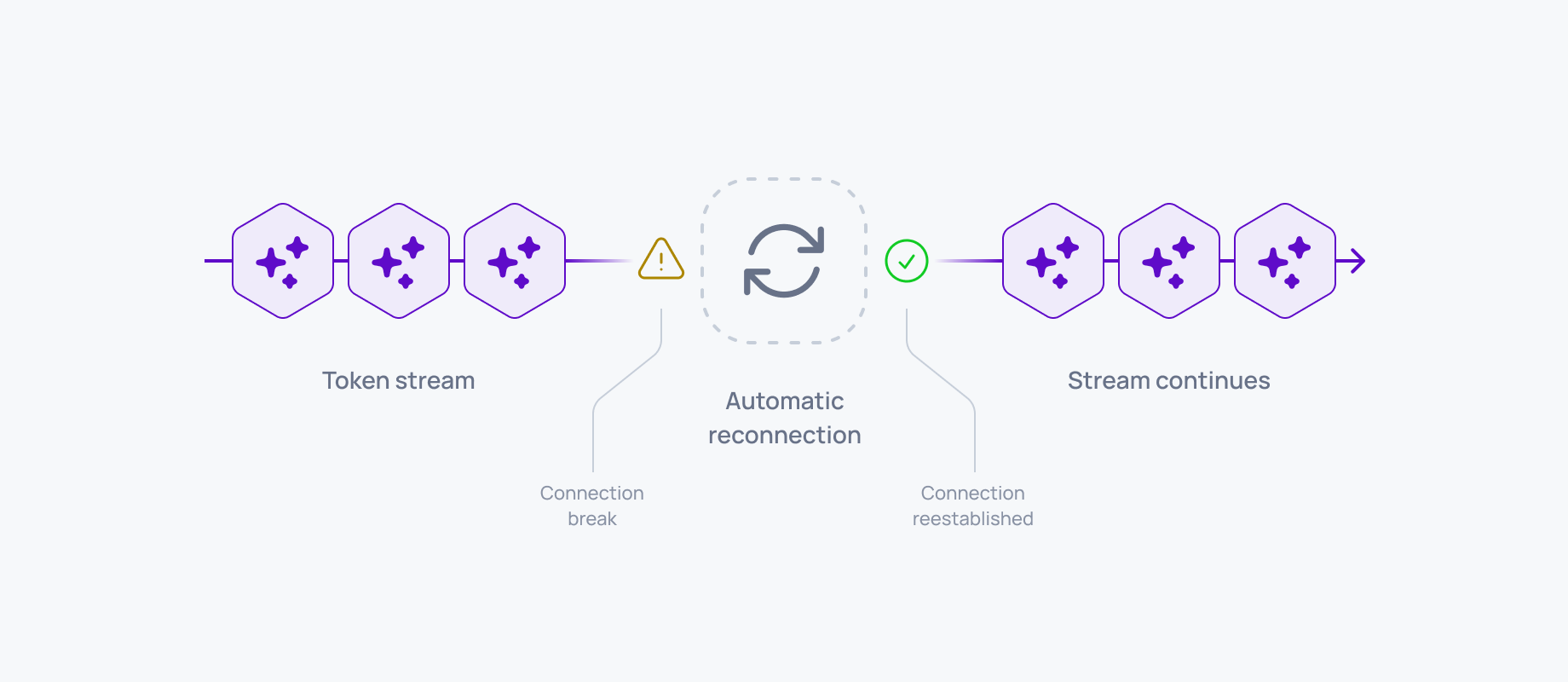
Server-side output buffering and replay
The transport layer buffers the AI's output on the server side as it's generated. Every token is stored at least until it's safely delivered. If the client disconnects, those tokens are still available to send later. When the client reconnects, the transport layer replays anything missed from the buffer before returning to live streaming. The user sees no gaps. Without server-side buffering, there is no way to recover what was produced during a disconnect. See how catch-up delivery works on reconnection.
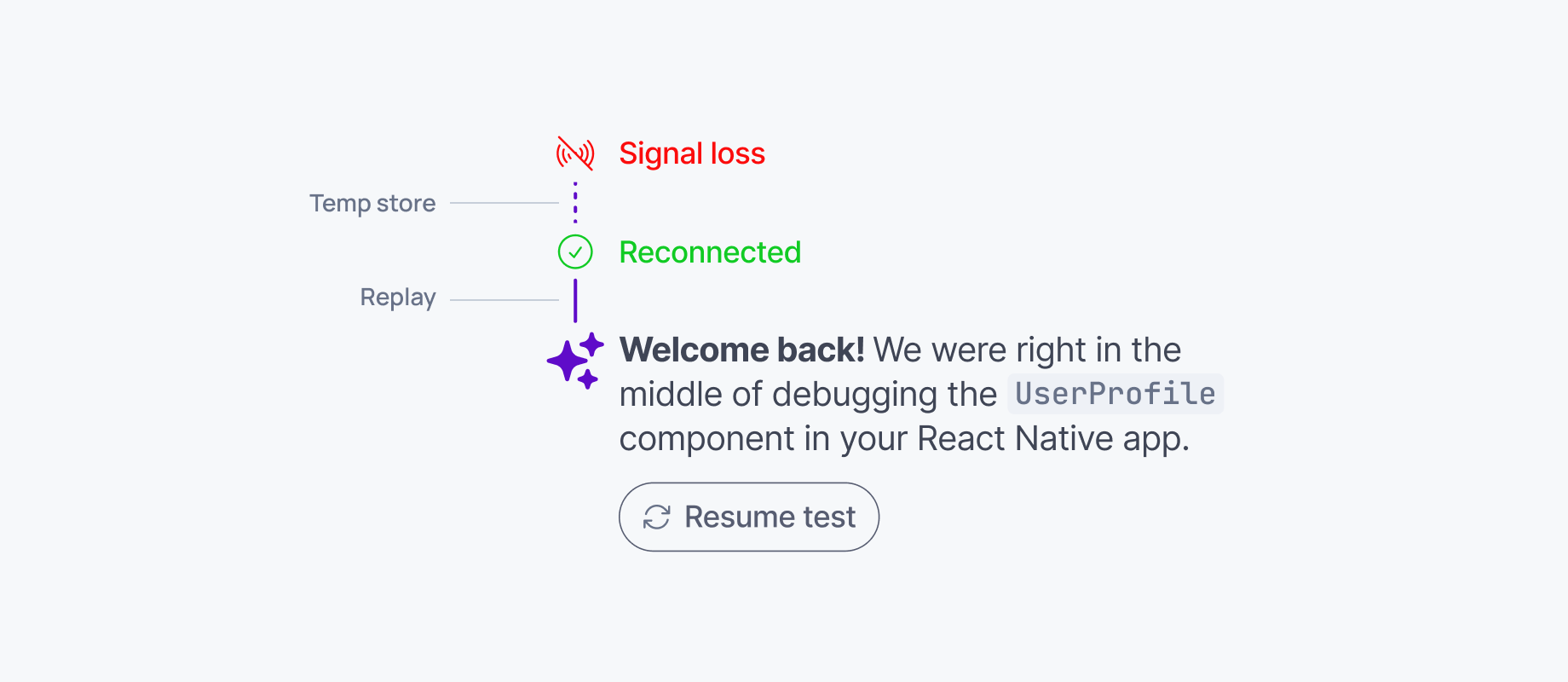
Session tracking across client restarts
To resume a stream, the system needs to know who is reconnecting and where to pick things up. That means using a stable session ID that stays the same even if the page reloads or the device changes. When the client reconnects, it tells the server what it last received (e.g. "I got up to token 123"). The server sends only what was missed. This handshake is what lets the stream continue cleanly without starting over. See reconnection and recovery.
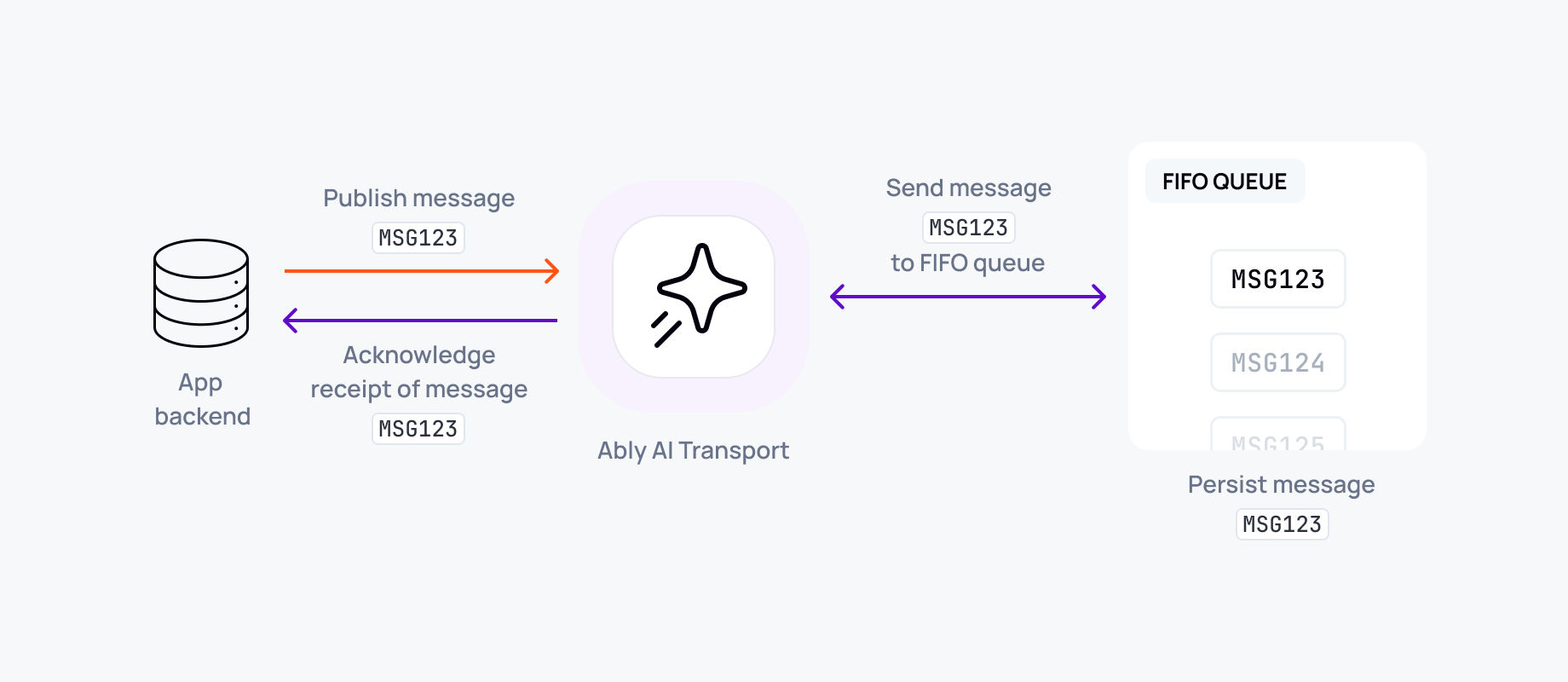
Ordered delivery guarantees and reconnection state
Maintaining correct token order is critical. The transport layer must guarantee that messages are delivered in order, exactly once. Each chunk gets a unique sequence identifier. The client never processes the same chunk twice, even in the face of retries. Upon reconnection, missed tokens are replayed in the original order with none missing and none repeated.
Ably AI Transport provides all four as a drop-in session layer, removing the need to build resumable streaming infrastructure from scratch. It does require Ably authentication integrated into your stack, so there is an additional setup step for teams not already on the platform.
Want to see how this works in practice? The AI Transport getting-started guide walks through the implementation with Vercel AI SDK in a few minutes.
How the experience maps to the transport layer
To better illustrate, here's how specific user expectations translate into transport-layer requirements and technical implementations:
Delivering reliable, resumable streaming today
Resumable token streaming is not a future capability. You can ship it now without redesigning your architecture.
Ably AI Transport provides persistent connections, ordered replay, automatic resume, and delivery guarantees as part of the platform. Your generation process keeps running, and users see the response continue exactly where it left off when they return. The getting-started guide walks through the implementation with Vercel AI SDK in a few minutes.
For more on how resumable streaming works under the hood, see resume tokens and last-event IDs for LLM streaming. For the Redis build-vs-buy decision, see AI chat stream resumption: when Redis is enough and when you need durable sessions. For the multi-device angle, see cross-device AI sync.
Frequently asked questions
Does resumable streaming work across devices or just page reloads?
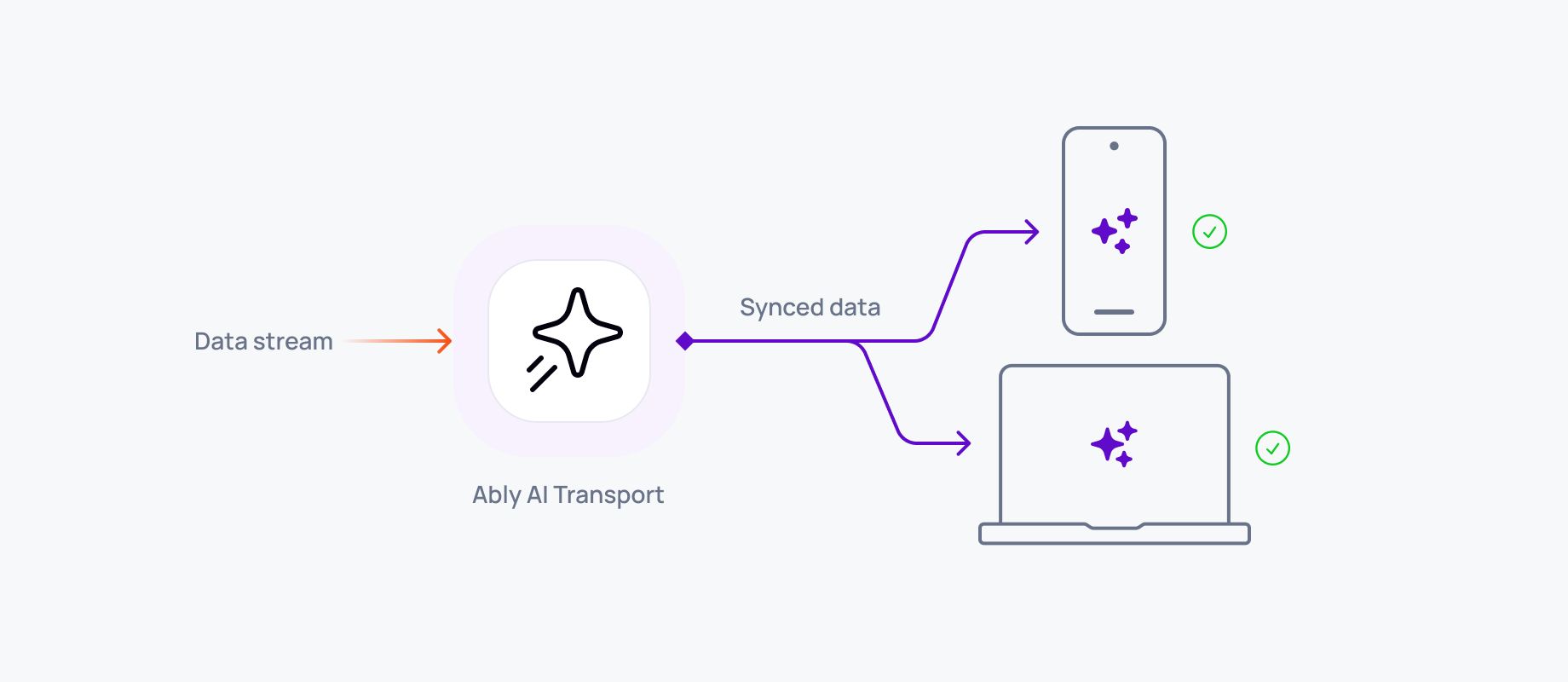
Most implementations, including Vercel's resumable-stream package, cover page reloads on the same device. They reconnect to the same server-side buffer using a stored stream ID. Multi-device resumption is a different problem: Device B has no position in Device A's stream. That requires decoupling session state from the connection entirely. See cross-device AI sync for the full architectural breakdown.
How does resumable streaming work with the Vercel AI SDK?
Vercel's resumable-stream package uses Redis to buffer tokens during page reloads. It handles single-device, same-tab recovery. For multi-device continuity, tab switches, or mobile backgrounding, you need a transport layer that decouples session state from the connection entirely. Vercel designed a pluggable ChatTransport interface for this.
What does a dropped AI stream cost?
Re-running inference is the obvious cost, but the engineering time to build custom reconnection, buffering, and deduplication logic compounds it. This is one reason teams evaluate managed session layers rather than building resumable streaming from scratch.


