Fandom is now global. And the extraordinary opportunity that presents is balanced by the demands that fan expectations place on your digital platform.
No matter where they are–front-row seats or five timezones away–people engage with your fan experience to enjoy an immersive, immediate experience. However, as more fans take part, you might find that your platform hits a reliability and scale ceiling. If fans can get their updates and communicate with each other faster and more reliably elsewhere, that could make for an existential threat to your fan experience.
There are, though, proven patterns that you can deploy to enable your platform to serve the expectations of an ever growing fanbase reliably and on budget. In this article, we’ll explore the key challenges and how to address them through your architecture by covering topics like reliable data flow, the right communications protocol, and scalable infrastructure.
Why reliability is challenging for fan experiences
We should start by setting the scene. Digital fan experiences typically come in three broad categories:
- Live experiences: Fans watch a livestream or broadcast with no interactive features.
- Shared live experiences: Fans can interact with each other alongside the livestream or broadcast.
- Collaborative experiences: Fans directly contribute to the experience itself, collaborating with each other to create content and other ways of influencing the experience.
In this article, we’ll focus on the second two types of experience. That’s not to say that live streaming video is without its challenges, but it’s a known problem and we've had two decades of engineering focused on delivering video efficiently.
When you add interactivity, everything changes. The resource demands, scaling profile, and economics become shaped by:
- Unpredictable, sudden spikes: Key moments—a goal or a dramatic plot twist—drive traffic and engagement in bursts that are hard to predict.
- Peak-driven design: At the very least, you need resources in reserve to serve those high-intensity moments. That usually means keeping capacity that sits idle most of the time.
- Non-linear scaling: And those peaks, as well as the average level of traffic, might be more extreme than you’re used to. As more fans join, the traffic required to serve them grows exponentially and can reach enormous volumes with relatively few people.
- Low latency expectations: All of that traffic must reach fans faster, or at least as fast as, competing platforms. Scores, betting odds updates, and reactions must all arrive seemingly instantly.
- Global reach: Complicating the low latency requirement is that fans can be anywhere in the world. But there are no allowances made for that. They expect the same experience whether they’re in the arena or on the other side of the world.
We can illustrate the impact of getting the architecture wrong with a quick example.
It’s the NBA Finals and the game is tied. Millions of people are watching worldwide, many of whom are taking part in the official live fan experience. They’re chatting, sharing clips, receiving stats, voting on the MVP, and more.
At the moment the winning shot goes in, traffic volumes explode as fans celebrate or request a replay review. In the context of what we now know about the demands placed on fan experiences in these moments, three things are at risk of happening:
- Connections drop: The surge of traffic overwhelms connection pools on the realtime infrastructure and fans lose their connections to the experience. Their repeated attempts to reconnect creates negative feedback loops that compound the problem. As a result, fans miss key moments and reactions.
- Data arrives out of order: Queues start to form as multiple services struggle with the volume of data. New services spin-up to distribute load, meaning new messages join shorter queues and get delivered out of sequence. But without explicit message ordering mechanisms the result is that stats, voting tallies, and fan comments arrive in random order.
- Messages get delayed or lost: As timeouts kick-in, the system starts to drop messages, resulting in data getting lost and the fan experience becomes an incoherent mess.
A realtime fan experience is a distributed system
But why do these problems arise?
With thousands—or even millions—of fans taking part, the fan experience transforms into a complex distributed system made up of interconnected components including data sources (e.g. score feeds), data consumers (primarily fans taking part in the experience), and the platform infrastructure connecting everything together.
With all those different systems interacting, we come up against some fundamental challenges:
- High network latency: Data takes longer to travel to and from people who are further away from the fan experience platform’s servers.
- Disconnections and data loss: You can’t control the open internet that connects fans to the fan experience. Individual fans might drop out due to unreliable cellular connections, for example, or there could be broader network issues that cause data loss.
- Failures: Individual components or systems are bound to fail at some point. A fan’s device might crash, a server in the platform might go offline, or a critical service dependency could experience an outage.
- Data sync inconsistencies: You can’t be sure that every part of the system has the same view of what is happening. This is especially true when you add capacity by having multiple systems doing the same job, such as processing live event updates or distributing chat messages. Differences in processing times or delays in synchronization can lead to conflicting or outdated information being served to different users.
The problem becomes clearer once we can see a simple example. Let’s say you have a single fan experience system running on one virtual machine in a US east coast cloud region.
This system serves fans worldwide, all connected to that single server:
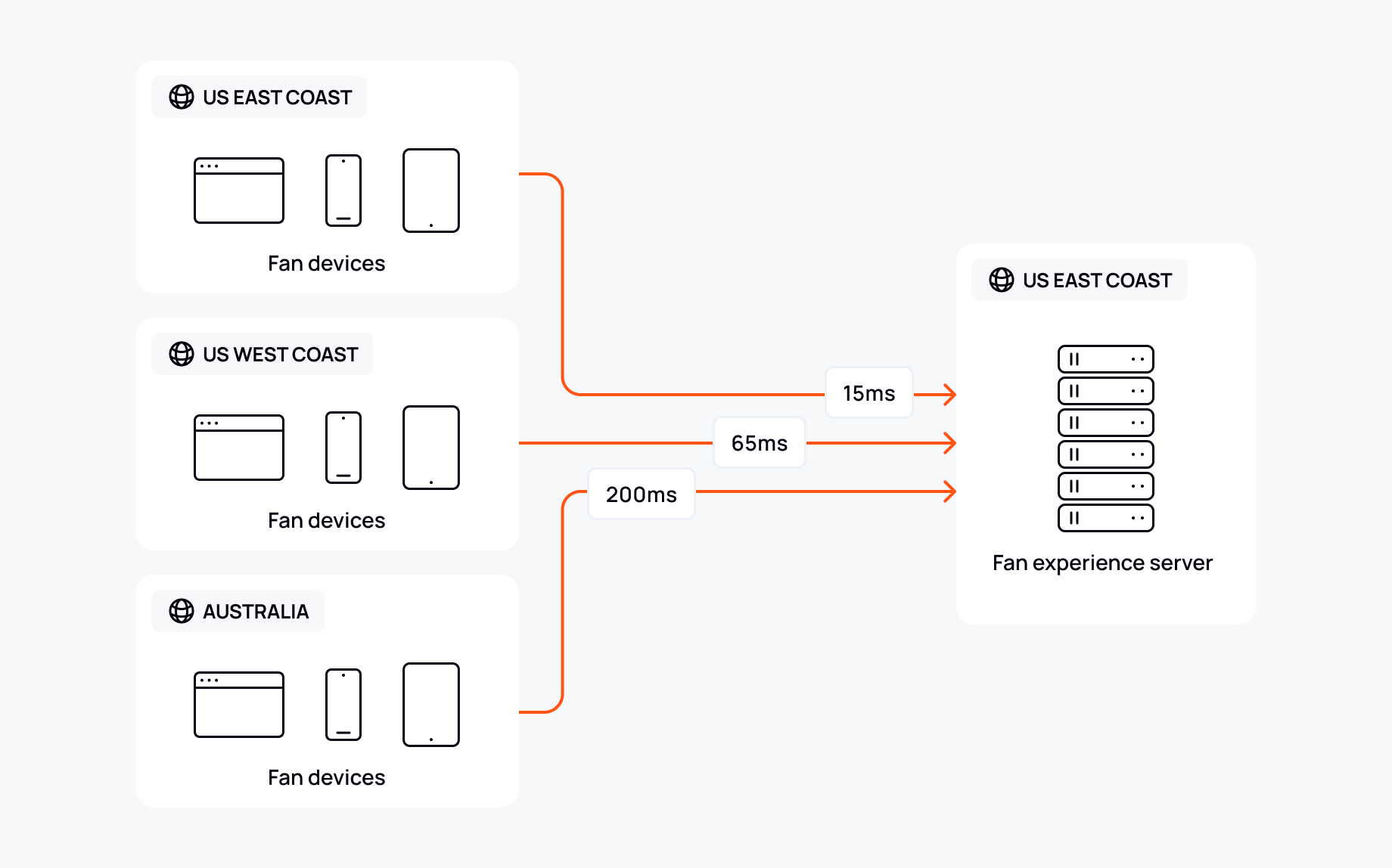
The physical distance our data must travel contributes to network latency. Fans on the US east coast, being closer to the server, experience lower latency than those farther away, such as fans in Australia.
For example, a fan in Melbourne might react to a big moment, but their message takes longer to reach the server than those sent by fans in New York. By the time our Australian fan’s message is delivered, people on the US east coast have already moved the conversation forward, leaving those farther away feeling out of sync and disconnected from the experience.
But it’s not just latency. Fans relying on an unreliable connection might drop out entirely, resulting in disconnections that disrupt their experience and leave gaps in the conversation. Meanwhile, if a server or critical system fails, the platform could struggle to recover quickly, affecting the reliability of updates and interactions. And as traffic grows, delays or synchronization issues across distributed services could lead to inconsistencies, where some fans see outdated stats or reactions compared to others.
Architecting a reliable fan experience
To make sure data flows quickly and reliably through the fan experience even during times of heavy traffic, you need an architecture that:
- Minimizes latency: Deploy servers closer to users and optimize data pathways to ensure realtime interactions remain seamless, no matter where fans are located.
- Guarantees data delivery and integrity: Implement mechanisms to ensure every message reaches its destination in the correct order, without duplicates or losses, even during network disruptions or system failures.
- Scales on demand: Design the system to handle sudden traffic spikes, with the ability to dynamically scale resources during key moments without compromising performance.
- Is resilient: Incorporate failover mechanisms and redundancy so the platform remains operational even if individual components fail.
- Maintains consistency: Synchronize data across distributed systems to ensure all users see the same updates and interactions, regardless of location.
With that in mind, the communications protocol you choose to transfer data between the components of your fan experience platform shapes how you tackle these challenges. Different protocols make distinct trade-offs. Some balance easy implementation and low latency with reliability, while others maximize reliability at the expense of speed.
Selecting the right protocol for reliable fan experiences
Choosing the right protocol is one of the most impactful decisions you’ll make when building your fan experience platform. It will inform the additional engineering effort you’ll need to make to meet the reliability expectations of fans.
How, then, do you choose the protocol that offers the best balance of functionality for our needs? Three of the most common persistent communications protocols are WebSocket, MQTT, and gRPC. At first glance, they can seem somewhat similar, but they were each created to solve a different problem. For example, WebSocket is the official web standard for low-latency, bidirectional communication, while MQTT is most at home in powering internet of things (IoT) applications, and gRPC is primarily used to connect back-end services.
Here’s what this means for your fan experience:
| Protocol | Advantages for fan experience | Disadvantages for fan experience |
|---|---|---|
| WebSocket | • Universal availability • Low protocol overhead • Full duplex, bidirectional • Flexible message formats |
• No message guarantees • Lacks automatic reconnections |
| MQTT | • Publish-subscribe model useful for one-to-many communication • Low protocol overhead • Built-in message guarantees |
• Limited browser support • Requires brokers |
| gRPC | • Fast binary protocol • Data typing |
• No browser support for the full protocol • Complex to implement |
On balance, WebSocket is likely to be the best choice for most fan experience systems, largely thanks to its universal availability and ease of implementation. However, as we’ve seen, raw WebSocket does leave some gaps in the remaining areas that you’ll need to address.
Let’s look at how you can strengthen WebSocket with messages guarantees, automatic reconnections, and horizontal scaling.
Implementing message guarantees in WebSocket
As WebSocket doesn’t provide message guarantees by itself, you’ll need to build your own way of making that messages arrive at their destination in the intended order and the correct number of times.
Specifically, you’ll need to consider implementing some or all of the following:
- Message acknowledgments (ACKs): When a data consumer receives a message, it sends an acknowledgement back to the data source or, more likely, the system that coordinates message delivery. That way, your system can track message status, resending those that fail to arrive.
- Message IDs: Every message in your system needs a unique identifier. These IDs help track whether messages have arrived and also make it possible to remove duplicates.
- Exponential backoff retries: If messages are failing to arrive due to some problem along the way, the last thing you need is to compound the problem by repeatedly resending your message. Instead, configure your system to gradually increase the gap between each retry and then, eventually, to timeout altogether. This helps prevent overwhelming clients with a storm of retries.
- Temporary message storage: By keeping recent messages in memory or a fast storage layer, you can replay them when clients reconnect, ensuring no updates are lost during brief disconnections.
- Message prioritization: Not all messages are equally important. By maintaining separate queues for different priority levels, you can ensure crucial updates get through even when the system is under pressure.
Enabling automatic reconnections
WebSocket’s focus is on enabling communication rather than connection maintenance. As such, you’ll need to monitor connection health and reestablish lost connections in your code. That means buildings systems to take care of:
- Connection monitoring: Regular small messages in both directions let your system quickly detect when connections degrade or drop, rather than waiting for the next real message to fail.
- Session preservation: By keeping track of each client's session info–subscriptions, authentication, and message sequence numbers–you can restore their exact state when they reconnect.
- Message buffering: While a client is offline, you queue their messages in temporary storage. This is related to message delivery guarantees because, rather than having messages disappear, you can send them from the buffer when the recipient reconnects.
- Smart backoff: If a client repeatedly fails to maintain a connection, you can gradually increase the delay between reconnection attempts to avoid overloading recovering systems. Similarly, trying alternative WebSocket endpoints––such as a different load balancer or regional failover––offers a way to route around potential issues.
- Fallback to other protocols: There might be times where it’s not possible to maintain a continuous WebSocket connection but where a fallback transport like HTTP long polling can still deliver your data. In those cases, your connection monitoring should be able to identify network conditions or client capabilities that require switching to a different method.
Scaling WebSockets and reducing network latency
Unlike stateless protocols, such as HTTP, WebSocket needs a little more thought when it comes to scaling. That’s not to say it’s especially hard to implement but it does take more engineering effort to implement and maintain.
As your service grows in popularity, it needs to be able to serve more people concurrently. And it should also reduce network latency, especially as the geographic spread of your fans grows.
To meet demand and to reduce latency you’ll need to consider:
- Load balancing: Distribute WebSocket connections across multiple servers while ensuring each client maintains a consistent connection to the same server throughout their session. And because WebSocket is stateful, you’ll need a way to make sure clients connect to the same end-server each time or to share state between backend servers.
- Regional deployment: Serve fans from nearby data centers to minimize latency, with automatic failover between regions when needed.
- Message routing: Coordinate message delivery across server instances without duplicating messages or losing ordering guarantees.
- Data replication: Maintain consistent state across regions while handling the inherent delays in global data synchronization.
Of course, we’re just scratching the surface here. See our guide to building scalable WebSockets implementations, for more detailed technical guidance.
So, should you build in-house or buy a reliable realtime fan experience solution?
The WebSocket protocol provides a great foundation. However, as we’ve just seen, it takes a substantial amount of engineering work to meet the reliability and scalability requirements of a fan experience platform.
That lost engineering time means less time and fewer resources available for delivering features that will build loyalty amongst your fans. It also puts the burden on your engineering team to become experts in solving complex distributed computing problems.
It can be tempting to build in-house because it gives a sensation of having more control over the experience but the reality is often that your team will spend more time fighting fires than fulfilling that promise of control.
To make an informed decision, it’s essential to weigh the challenges of building in-house against the resources, expertise, and flexibility required. Consider the following:
- Engineering resources and opportunity cost: Reliable WebSocket infrastructure requires months of dedicated engineering effort. That's time your team should spend building unique fan experiences or shipping for key events. Even after launch, maintaining custom infrastructure creates permanent engineering overhead that pulls focus from core platform features.
- Infrastructure and operational costs: Global fan experiences demand distributed infrastructure to handle everything from connection management to message persistence. Factor in 24/7 on-call rotations, monitoring, and maintenance and you're looking at significant operational costs before writing a single line of fan engagement code.
- Scaling complexity: Fan platforms face brutal scaling challenges. A game-winning shot or season finale can trigger massive traffic spikes that overwhelm unprepared systems. Building infrastructure that handles these moments gracefully demands deep realtime engineering expertise that most teams simply don't have.
- Technical debt and reduced agility: Custom infrastructure often becomes a constraint rather than an enabler. As fan expectations evolve and new engagement features emerge, you might find your system can't support them. This forces painful choices between expensive rebuilds or living with limited functionality.
To avoid your platform’s failure becoming the story after a game, consider how the right realtime infrastructure can give you the freedom to focus on delivering unique experiences.
At Ably, our realtime platform already powers some of the world’s best loved fan experiences. Here’s why they choose to work with Ably:
- Seamless global scale: When thousands of fans react to a crucial play, you need instant scalability. Our global network means that, no matter where your fans are located, they’ll enjoy immersive experiences thanks to 6.5ms median global network latencies.
- Industry-leading reliability: With Ably, your data gets to its destination in the right order and the right number of times, thanks to 99.999999% (8x9s) message survivability. And we’ve never had a known global outage because our network automatically routes around issues.
- Exactly-once delivery and guaranteed ordering: It’s not enough just to make sure data arrives; it has to arrive in the right order and precisely one time to avoid confusing fan experiences.
- Predictable costs: Rather than making large capital investments in infrastructure and engineering, working with Ably gives you predictable usage-based pricing. No hidden infrastructure expenses or on-call rotations eating into your budget.
- Room to innovate: Fan engagement evolves quickly. Ably gives you flexible building blocks that support everything from basic chat to synchronized watch parties. You can focus on creating new experiences rather than rebuilding infrastructure.
Ready to see how Ably can transform your fan engagement platform?