A brief look at the history of web technologies, and our readiness for the realtime web — talk by Matthew O’Riordan, CEO, Ably Realtime
Script
[INTRO]
Hi all. I am Matt, the technical co-founder of a platform as a service business called Ably. We provide realtime functionality as a service for developers making it easy for them build realtime apps and services, such as chat, live pricing information, or collaboration tools like Google Docs.
Before I get all nostalgic and give you a brief history of the internet and describe the building blocks that have enabled it to be so incredibly successful, I think it would be better to first start with what I mean by data at rest and data in motion.

Funnily enough, when I went ski touring in a little swiss village called Trient last year, I saw something there that reminded me of data at rest. In the 19th century, the frozen water industry emerged, and Trient, the town I was in, started supplying ice to the industry in the late 19th century. People would literally harvest ice from the Alps, transport it across the continent, and sell it in markets. I found the whole concept of the ice industry quite fascinating, but as a realtime evangelists thinking about data in motion, I did draw some rather obscure analogies with data at rest and how data in motion solves these problems.
At the time, there was a supply chain for this ice, and it would be harvested and shipped from source to a marketplace, where buyers would come to buy ice, then ship it onto other smaller marketplaces, where buyers would come to buy ice wholesale, until eventually it reached the final buyer. All along the way, two very important factors were at play. The value of the ice decreased the longer you held it, there was no way to ship the ice directly to the end user, intermediaries were needed. So speed was pretty important, yet in spite of this, the only way to participate in this market was go to to a marketplace, buy your ice, and ship it back. This is very much like data at rest, at least for data where timeliness is of the essence. If the only way to find out the price of the stock is to ask someone what the price is, and they have to ask other people in turn, the time it takes to get an answer is going to be long, and it’s going to be hugely inefficient as everyone keeps asking each other the price even if the markets are closed.

At the start of the 20th century, the frozen water trade came to an end due to advances in refrigeration cooling systems, yet water itself was of course still needed. Water flowed in pipes like data in motion, and a continual flow of the materials for ice were distributed to all buyers in the market directly. The intermediaries in many ways were removed complete, water would enter the water systems and be distributed directly to homes and businesses where it would later be turned to ice. No one needed to explicitly request water because the water itself was flowing, readily available. It’s no coincidence of course that data in motion is often referred to as data streams, fire hoses and pipes.
So my talk today is really focused on the how in the last 20–30 years the Internet has moved forwards in leaps and bounds, yet to some degree, in relative terms to my earlier story, we are in the late 19th century. This was the pinnacle of the frozen water industry, which in today’s terms, the period where most data is still at rest. Yet I believe a big change is brewing driven by consumer demand for realtime experiences, exponential growth in data being generated from new sources like IoT devices and machine learning, and recognition that the value of data in many use cases has decreasing value the longer it remains at rest.
[DEMO]
Before I get started, I’m hoping we can have a little bit of fun whilst I demonstrate the use of realtime technologies on your mobile phones.

Please visit giveitalob.com on your mobiles now.
Are you there?
Ok, so who wants to be the guinea pig and throw their phone in the air for us all to enjoy?
What code do you have?
Right, OK, so you’re now streaming the orientation of your phone in realtime to the Ably cloud, as well as the acceleration of your phone.
Everyone else, you should see that code appear on your screens now in realtime. Click on that, and we’ll all see a realtime stream of that phone.
Can you rotate your phone around, and everyone should see that?
Ok, do it, throw your phone but please do catch it.
Good throw.
So what you are experiencing there is a basic example of data in motion. The mobile device is streaming data to the cloud, in this case our closest servers in Ireland, and then that cloud is streaming data out to all the other devices and my laptop in realtime.
[BASE HISTORY]
So now that we know what data in motion is versus data at rest, and we’ve seen data in motion in action, it’s time for our history lesson!
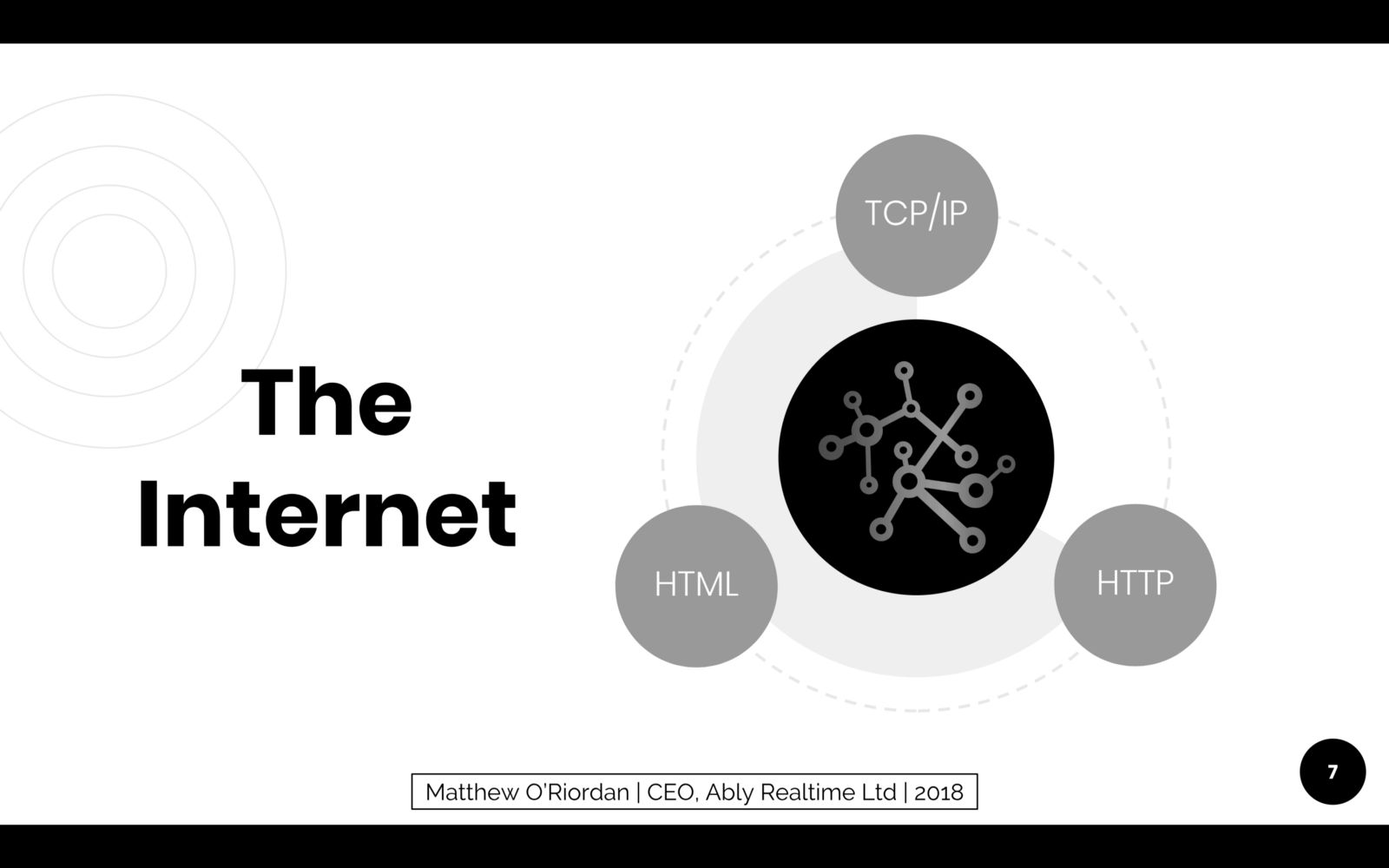
Whilst the Internet and Web has been built on a broad set of technological developments, there are almost unequivocally a few notable technologies that are the backbone and catalyst for the underlying network and web services have today.
Back in 1970, two DARPA scientists developed TCP/IP, which is the low level network protocol that provides a robust way for computers to transmit data to each other. It is the primary networking protocol that all internet enabled devices rely on today, although there are some indications some new protocols may now finally emerge, almost 50 years on, such as QUIC.
Then in the 90s, HTTP, a protocol designed by Tim Berners-Lee, became the application protocol of the web. It provided a language for browser to communicate efficiently with web servers over a simple text based protocol. It was of course built on top of the robust network protocol of the 70s, TCP/IP.
Then very soon after, came a number of browser technologies to handle markup, layout and presentation of content, namely HTML, CSS and Javascript. Tim Berners-Lee was once again instrumental in much of this, having defined the first HTML spec in the early 90s. And given he had been instrumental in the design of HTTP, browsers were of course retrieving this markup over HTTP.
Arguably, it is these three layers of technologies that has made the Internet so successful and revolutionised how people communicate with each other and businesses globally. Like the agricultural and industrial revolutions, the change has been driven by a collective process that developed and expanded from one innovation being built upon another.
[RECENT HISTORY]
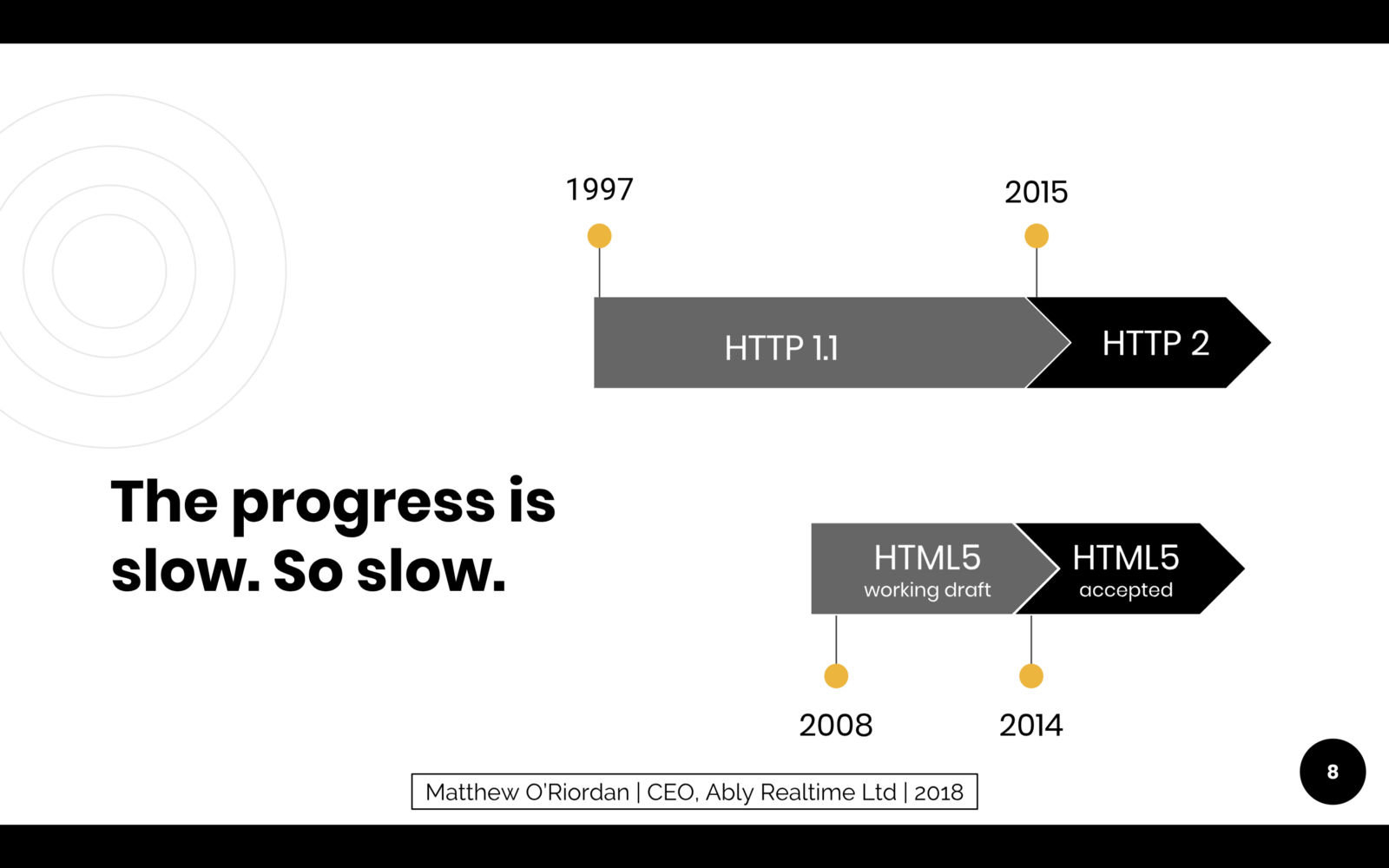
Moving forwards, the demands on the Internet have continued to increase, largely driven by consumer demand and expectations for improved and often far richer experiences. Open standards such as HTML, which are so widely adopted, have unfortunately been slow to evolve to meet these demands because it requires working groups to agree on complex and often backwards incompatible changes. For example, HTML 5 first became a working draft proposal in 2008, and was only released as stable version 6 years later in 2014. Similarly, HTTP 1.1 which is most widely used today, was defined as an ISO standard in 1997, and 18 years later now has a successor, HTTP 2.0. HTTP 2 whilst a huge improvement on HTTP 1.1, is hardly an entirely new technology, but instead represents a significant evolution of the core tenets of the original HTTP spec defined by Tim Berners-Lee back in the early 90s. Sadly, this is not unsurprising as backwards compatibility is essential, and getting working groups to agree and implement significant changes to the Internet’s fabric is hard.
Whilst most of the focus thus far has been on the technologies that enable people to interact with the web, businesses have been exploiting the internet and web fabric to exchange data with each other programmatically as well with great success. These web and internet technologies made it incredibly easy for businesses to communicate with each other as the networking layer TCP/IP existed, and the protocol for servers to communicate with browsers was equally efficient for servers to communicate with other servers. So once the Internet picked up momentum, we quickly saw businesses follow suit and start offering APIs, which stands for Application Programming Interfaces.
But there was a problem which stifled widespread adoption of these APIs by businesses. Whilst it was easy for businesses now to send and receive requests over Internet protocols, there was no agreement on formats. So standards organisations and committees emerged to try to solve this problem. However, in many ways this only exacerbated the problem. The standards defined for these data formats were often incredibly thorough and covered every edge case they could think of, but they were also complex. So whilst interacting with other businesses was now far simpler over web technologies, there was a new layer of complexity in implementing these complex standards by both the requester and receiver of this information.
So in the mid to late 90s, a working group was formed to define a flexible and extensible markup language called XML that allowed machines to communicate with machines without having to worry about data formats, but instead focus on the data and the semantics of that data. XML was in fact soon replaced mostly with JSON as it’s a far simpler format for data in most cases, but in reality, I believe XML was the first technology that really solved the problem of providing a common data format for businesses.
But there was still one final barrier before businesses could freely communicate with each other without significant engineering effort. Whilst the networking layer, protocol, and now the data formats had effectively one preferred approach, there was still a lack of standardisation in how clients and servers could express commands and requests to each other. Therefore, without this standardisation, every time two companies built API connections with each other, they would need to implement a custom language or programming interface to perform common operations like requesting the price of a product. A few technologies came along to try and solve this, including WSDL and SOAP, however in the end REST, or Representational State Transfer, won out and this standard is still by far away most adopted.
So in early 2000, when all of these technologies, standards and protocols were in place, I believe it was at this point that a new programmable interface economy was finally able to emerge. The overhead required to consume or publish APIs became small, developers no longer needed to reinvent the wheel each time they were tasked with this, and as such, businesses were more easily able to realise value by exposing a programmatic interface into their business. In fact, Salesforce and eBay are recognised as the pioneers having exposed public APIs for the first time in early 2,000.
Whilst the impact of these technologies and the reduced engineering friction as a result may not seem that significant, I believe the emergence of widespread APIs in itself could be considered a technological revolution. Currently, on a directory which tracks public APIs called ProgrammableWeb, there are over 10,000 different companies providing APIs, which in reality means there are probably 10s or even 100s of millions of API integrations globally. Now what seems like a trivial purchase of an item on Amazon, may in fact result in hundreds of APIs being executed in near realtime to fulfill that request, from payment, to fraud detection, to fulfilment, to notifications and thank you emails.
[FIRST REALTIME TECHNOLOGIES EMERGE ]

At this point I think it’s fair to wonder what all of this has to do with data in motion and data at rest. Well once consumers got used to the idea that they could interact with businesses from anywhere in the world and get a response within seconds, they demanded more. It was no longer acceptable that an online bank statement was out of date, or traffic updates were not in real time, or even simply that your web mail that was quickly replacing your native mail clients was not updating in real time. So the first generation realtime systems evolved to solve these problems.

Google and their Gmail product is often seen as the product that drove this innovation. They wanted to give their customers a realtime experience within a web browser and see their emails arrive in real time. To achieve this was not easy as all of the web technologies I’ve talked about thus far are really designed for data at rest. What I mean by this is a client, which is a browser in this case, sends a request to a server, and waits for an answer. A request/response mechanic is the basis of the HTTP protocol that Tim Berners-Lee first devised in the 90s. As such, a client browser cannot ask a server to notify it when there’s something new, but must instead simply continue to ask the server periodically to find out if there are updates available. This nasty architecture pattern is called polling and unsurprisingly is still used widely today.
So the innovative engineers at Google were forced to be creative and hacked the underlying HTTP protocol. In simplistic terms, what they did is realise that just because a client is asking a question, it doesn’t mean the server needs to answer straight away. Instead, when a server received a request from a client saying, “Hey, are there any new emails”, if there weren’t, the server would just wait. And it would continue to wait until a timeout was reached, or an email did arrive and it would respond with “Yes, I have a new email”. And like that, pseudo realtime was born, and consumers were able to get realtime-like experiences within devices built upon web technologies. This approach to realtime is again still used quite extensively, and is called long polling.
And off the back of these hacks, the first generation realtime platforms were born. And they worked surprisingly well, and solved the realtime notification needs of the time for browsers. However, these hacks have shortcomings, and whilst these approaches work for simple notifications, they are just not fit for purpose for broader applications, such as business to business data sharing, high data throughput, or indeed simply as a reliable way to deliver data with guarantees in regards to performance or integrity of your data.
[CURRENT STATE OF PLAY]
So we’re finally getting to the point of my talk and problems that we are facing when it comes to data in motion.
Remember earlier I told you that the amount of data being produced is growing exponentially, well that’s true. See this graph:

Admittedly a lot of that growth is coming from unstructured data like video, images and audio, however it’s still data, and consumers still want access to that data quickly. The interesting thing is that the predictions are that an increasing amount of the data being produced won’t in fact be stored. This is largely because it is only relevant at the time, or is only needed to drive an activity such as machine learning, aggregate some stats, or trigger events.
So if we assume that:
- Consumers increasingly demand realtime experiences
- The amount of data being produced is increasing
- The amount of data needed to be processed is increasing at the same rate
- Yet the amount of data needing to be stored is decreasing
- And the value to consumers is in the recency and accuracy of that data
Then I believe that firstly the current generation of data at rest APIs and technologies are not suitable because they are not designed to be reactive, but instead are designed to handle the traditional request/response mechanic.
And secondly, that a new set of realtime APIs are needed to allow businesses to share this data freely, easily, and without significant engineering overhead, like they do now for static APIs.
The problem is, no standards are emerging to solve this problem.
We have TCP/IP which is the network layer, which is indeed fit for purpose.
We have HTTP and a superset of protocols on top, that are still primarily focussed on request and response mechanics. Some streaming capabilities exist on top of HTTP like WebSockets, SSE, XHR streaming, but the problem is that we also have other suitable protocols like AMQP, STOMP, XMPP, CoAP, just to name a few. And on top of that, there are literally hundreds of proprietary protocols in use.
In terms of data formats, fortunately that’s a solved problem.
But once again, when it comes to standardising on APIs for how to query realtime data, some academic papers exist, but again no standard is emerging to solve this problem.
In addition to this, unlike with data at rest, realtime data is typically shared globally with any number of subscribers. So for example, a point be scored in a tennis match, may be broadcasted to millions of devices. With the data at rest model, the providers of those APIs would rarely be responsible for the fanning out of this data, whereas with data in motion models, the less intermediaries there are, the lower the latency. So the publishers are typically responsible for managing this scale.
[PROBLEM]
So firstly we need to think about what the ramifications of this problem are. My view is that because there are no standards, it makes it very hard for small to medium businesses to participate in this new realtime data economy. The costs to integrate, maintain and run systems that can publish and subscribe to realtime data is going to be prohibitively expensive from both an engineering perspective and even an infrastructure perspective.
Which in turn will lead to huge polarisation in the industry. The giants like Google, Amazon and Microsoft will be able to share data with each other, and as a result, accelerate away from others as they have more data to improve their services and experiences for their consumers in real time. Specifically, in the AI and Machine Learning space, the more data you have to train your models, the better the results of your AI, so this in itself is quite a daunting idea.
However, humans in times of need, and arguably more importantly, when there is an opportunity to commercially benefit by providing a solution, are incredibly good at finding a solution. So it is possible that standards will come together quickly, the industry will gravitate towards one or two of the many technologies used in the realtime and streaming industries, and as such, the realtime data supply chain will once again be democratised in the same way the static API economy is now. This is certainly possible, but given how long it’s take for standards to emerge to date, I fear that’s not possible.
Instead, at Ably, we are betting on another approach which is interoperability. Unlike with the current data at rest APIs that require both the client and server to talk the same language, we believe that the publishers and subscribers of data should be completely decoupled through an intermediary. So for example an IoT device may respond to a car parking space becoming available by publishing to an intermediary platform using MQTT, a popular IoT protocol. That platform will then be responsible for pushing that data to one or perhaps millions of subscribers who have expressed an interest in that data. All of those subscribers can choose to receive the data using any number of protocols, and do not care which protocol was used to publish the data.
With this approach we believe the engineering effort required to participate in the realtime supply chain is carried primarily by the intermediary, open protocols and standards can emerge which may eventually win out, but there is no rush to find a common ground, and all businesses of any size can participate in this new realtime data economy.
[PARTING ADVICE]
So before I finish up, I think it would be good to offer some parting advice.
If you are looking to offer realtime functionality to your customers, then:
- Think carefully about whether you should buy or build. Unless you’re at huge scale, the engineering costs of building and maintaining a solution will almost certainly outweigh your service costs. And a quicker time to market is often the most
- Databases and realtime functionality are often coupled together, which means you benefit from far quicker prototype. But the downside, is you’ve created coupling in your architecture which is much harder to pick apart later. I recommend you choose best-in-breed for each component of your stack when you can, although of course this decision will be influenced by many factors including the size of your business.
- Realtime functionality comes in all shapes and sizes including open source and commercial solutions. Think a little further forward than your immediate requirement because a solid realtime backbone for your apps and services will help you add more realtime functionality in the future more quickly.

If you are thinking of participating in the realtime data supply chain, as a publisher or subscriber:
- Try and avoid proprietary protocol lock-in. This only creates engineering friction for the other participants of your supply chain.
- Think about whether you will need to send partial updates or complete updates in your data streams. If the former, there are technologies like Conflict-free replicated data types (CRDT), OT and various patching algorithms, but as yet, there are no standards and sparse cross-platform support.
- Unless this element of your business is your business, offload the work of scaling, redundancy and security to a third party vendor so that you can focus on the areas that deliver value, the data.
Thank you!
Matt
— — END — —