

Many write about the merits of open data but a lot less is written about the challenges related to making such data accessible and available. Adapted from a guest post on bloggeek.me, this article offers a developers' perspective on optimising application and usage of public APIs, with a focus on live public transport updates.
Why realtime open data is useful
A well-known example illustrating the benefits of realtime open data is Transport for London and the ‘Citymapper effect’. Deloitte estimates that the 13,000 developers who started using this data created 600+ apps (including Citymapper), contributing £130m to the city’s economy within just a few years of the scheme’s launch. So it’s surprising large-scale examples like this are so rare, as ascertained by a recent study into the state of public transport APIs in ten major cities, conducted by Ably Realtime. Outside of transport, the EU’s data commission has also noted a distinct lack of publicly available, value-generating data sources (think weather information, realtime financial updates) due to the costs involved of realtime data distribution. In the UK, the Office of National Statistics (the ONS) has also noted a widespread lack of data sources in realtime. Headlines aside, ask most developers and you’ll get the same answer.
By allowing developers to publish and consumer realtime open data feeds on Ably’s API Streamer (a realtime API Management Platform) Ably’s Open Data Streaming Program aims to make public realtime data easier to work with. Work setting this in motion has involved identifying the most useful, publicly-available realtime data, converting it to a single realtime feed, and inputting it to the Ably Hub, which then re-distributes it to users (for free) in whichever realtime protocol and data structure they need. The process brought us into contact with hundreds of ‘open’ realtime data sets, and we soon became veterans in identifying and solving common problems developers experience when trying to consume realtime data feeds. Recurring obstacles range from a lack of ‘real’ realtime information, to a lack of protocol support, to heterogeneous data structures.
Below we isolate three key potential problems to bear in mind when accessing ‘realtime’ data sources, and share what we learnt about how to overcome them.
1. Polling takes up time and resources
Despite the fact many online experiences (B2C, C2C and B2B) now take place in realtime, we still see a lack of push-based realtime APIs. Developers have to poll for data if they want updates in near realtime. The internet’s infrastructure is built on REST-APIs, which fall short in terms of providing event-driven online experiences.
Let’s go back to transport systems as an example. Although transport systems are subject to change at any minute, even here we notice a lack of realtime APIs that would be better suited to reflect this. When we looked into this we found just 2/10 cities provided actual realtime APIs. As it happens, these were the two cities with some of the best journey-planning and transport sharing apps.
How do realtime APIs help? Consider an application which is meant to keep end-users updated with train arrival times, subject to change (as the city dwellers amongst us know), at any moment. Using pull-based protocols, those wanting to receive the information will need to poll the provider’s endpoint every few seconds for current information, with obvious impacts on server load as well as usability.
Leave it too long and you risk missing information on a train arriving at a different platform, and have the end user miss the train:
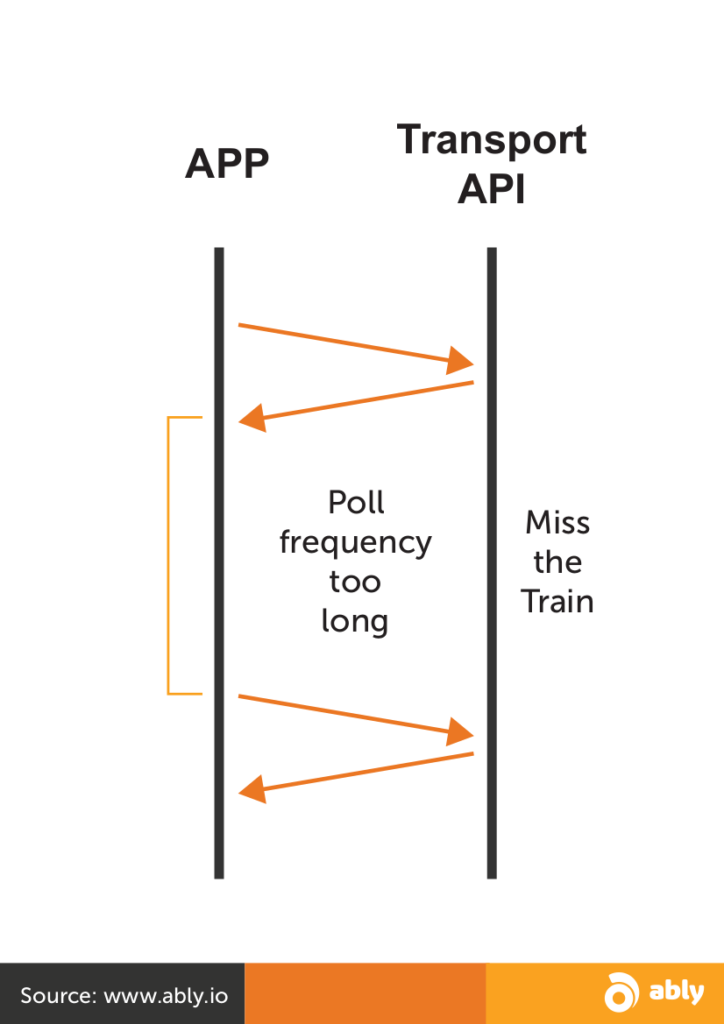
Make it too short, and you’re using a lot of bandwidth making requests for unchanged information, with each message also having a fairly large overhead:
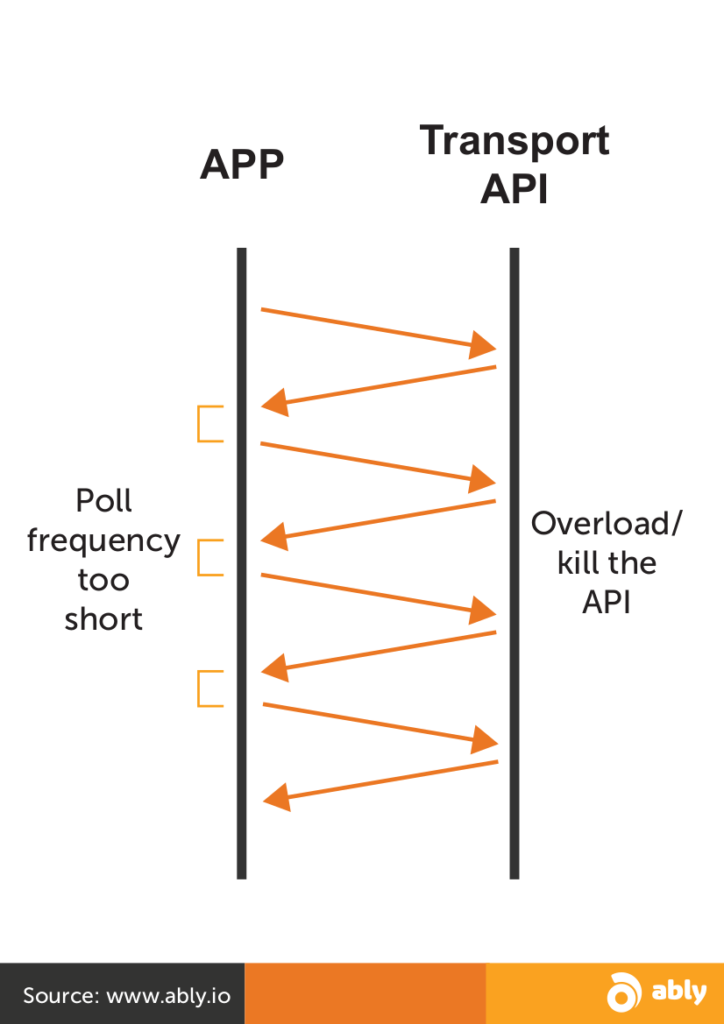
What can we do about it? We can recommend data be provided using push-based systems, to lighten the engineering load both for producers, who only need to provide the initial connection point, and for subscribers, who no longer need to worry about intermittently polling the provider’s endpoint. The result is instantaneous updates and far lower bandwidth costs.
Unlike pull systems, push bandwidth costs remain sustainable even when thousands of developers start using the data. For developers wishing to add realtime to their apps, look out for push-based APIs, such as WebSockets and MQTT, that allow for persistent, bidirectional connections. But while we are persuading data producers of the benefits of providing these, we can – up to an extent – stick with long-polling BUT optimize how we long-polling with maximal efficiency.
2. Data structures are fragmented
Developers looking for realtime updates have to spend a lot of time familiarizing themselves with each provider’s chosen protocol, be that HTTP or something like STOMP, working out its implementation, and how to convert this data into a unified format suited to a particular app or service. More widely though, and again using transport as an example, there is also a fundamental lack of standardization in the way transport providers structure their data. Some companies provide extended information – carriage formation, up-to-the-minute ETAs, and seat availability, others scrape by with the bare minimum of time and transport mode ID. A lack of standards across sectors mean developers wanting to expand the reach of their app (ie all developers) eventually come up against a host of additional problems to solve. With each new data structure developers need to work out which data corresponds to what, how to correlate similar data, in addition to allow for varying degrees of accuracy.
A good illustration of lack of cohesion is the variety of options for what has caused a disruption. GTFS Realtime includes twelve possible reasons for delays. NationalRail on Darwin however, has a whopping 496 options (I kid you not). If open data is to have a meaningful impact on different sectors, we recommend industry-wide agreements on what data to provide. For developers, in the meantime, it’s a matter of knowing how to sift through the sources.
3. Some data sets are more open than others
Most pull-based systems I’ve encountered don’t seem to be designed to handle large numbers of requests, which inherently reduce the value in the data as it becomes less accessible. Many transport data providers impose heavy rate limits and restrictions on data usage. For example, UK train operator NetworkRail has a limit of 500 people using their queues at any one time. TFL’s RESTful API is limited to 500 requests a minute. I think that public data providers need to impose generous limits. For developers, so as not to get caught out when your app scales, it’s a wise precaution to bear in mind that you will likely need higher loads than you are anticipating. Here and elsewhere, before you dive into building an app, it’s best to read the smallprint around your chosen data source, gauging how it fits in both with other data sources, and your use case.
If you have any other user feedback on public realtime data, or know of a public realtime data source that would benefit from being available on the Ably Hub, get in touch - [email protected]
Ably provides cloud infrastructure and APIs to help developers simplify complex realtime engineering. Organizations build with Ably because we make it easy to power and scale realtime features in apps, or distribute data streams to third-party developers as realtime APIs. To try us out, sign up for a free account or get in touch with our engineers.


