We audited our skills library a few months ago and found twelve dashboards hiding in it.
Not dashboards. Skills that built dashboards. Someone needed a view of some data, asked Claude to put it together, got a long HTML page out of it, and then wrapped the whole thing in a skill so others could run it again. Twelve times over, by different people, for different questions.
This is what happens when people want to build with AI but there's no clear way to do it. Metabase was our chosen tool, but it had got into a state, hundreds of dashboards, no governance, and people had quietly given up on it. So they reached for Claude instead, because Claude is where they were already working and it felt like the new way to do this. But Claude isn't built for dashboards. You get a one-off HTML page. To let anyone else use it you wrap it in a skill. To keep it current you run the skill again.
And to make the skill produce live numbers, you teach it to call our internal MCP tools, so every run it goes back out to HubSpot or wherever and pulls the data fresh. Which sounds fine until you have a dozen of these, each with its own query logic, each person's slightly different interpretation of the same metric, all hitting source systems directly. The artefacts people shared in between were worse again, frozen at the moment Claude generated them, out of date by the time anyone opened the link.
So the twelve skills weren't really the problem. They were the symptom of people not knowing what they should be doing.
It went deeper than tooling
The obvious read is that this is a tooling gap. People wanted to build dashboards, the official tool was friction, so give them a better way to build and the problem goes away.
We'd also come to a clear view that a dashboard-skill is the wrong tool, not just an awkward one. We think of skills as something that makes an AI agent smarter at a task, encoding reasoning or knowledge it would otherwise lack. A dashboard is the opposite kind of thing. It's reporting: a fixed question, the same query, the same answer every time. Wrapping that in a skill and having the AI re-fetch and re-render it on every run is using AI as a reporting engine, which is slower, non-deterministic, and invisible to everyone else. For us that's an anti-pattern with a name.
But there was something underneath all of it, and it's the reason people had drifted off Metabase in the first place: nobody knew where the right number lived.
Over half of our Metabase dashboards had zero views. The ones people did use often disagreed with each other, because there was no governance over what they queried or how a metric was calculated. So you'd open two dashboards that should agree, find they didn't, and have no way of knowing which one to believe.
When that happens enough times, people stop trusting all of them. And then they route around the whole system. They ask Claude an ad hoc question. They pull a number straight out of HubSpot when it should have come from Snowflake. They build a one-off skill that becomes the thirteenth dashboard in disguise.
The bottleneck was never getting an answer. It was knowing whether to believe the answer once you had it. Teams were spending more time working out if a number was right than they spent acting on it.
AI didn't cause this. It poured petrol on it.
This had been a problem for years, quietly. What changed is that everyone at Ably now queries data through Claude.
That's mostly brilliant. It's also what tipped this from a problem we lived with into one that bites daily. When anyone can get a confident, plausible-looking answer out of the data in seconds, every inconsistency in the data layer becomes a vector for a wrong decision made with high confidence.
And our data layer has a lot of inconsistencies, the kind every company that's grown for a decade ends up with. The same account is called ABLY_ACCOUNT_ID in one schema and ACCOUNT_ID in another. Our unique-devices table has one row per account per country per month, so reading it the obvious way, as if a row were the total, undercounts a busy account by more than a hundred times. And half a dozen of our tables look like they hold revenue, but only two are the ones our finance team actually stands behind. Query one of the others and you get a number that looks completely right and isn't.
A human analyst carries all of that in their head. They know which source to trust when several look right. They know which tables have to be summed rather than read straight. An agent doesn't know any of it, unless you tell it. It reads the field, trusts the value, and hands you a clean answer that's confidently wrong.
So the faster everyone got at pulling answers, the faster we produced confident misinformation. Speed without governance is just a quicker route to the wrong call.
So we fixed the layer underneath first
The first piece was building a governed way for the AI to get at our data. We call it the data warehouse genie. It's a skill, but really it's institutional knowledge written down.
It knows which table is the canonical source for each kind of question. It knows that of the tables that look like they hold revenue, only two are the ones finance trusts. It knows that the unique-devices table is one row per country and has to be summed, not read. All the context an analyst used to hold in their head, captured once, in front of every query anyone runs.
The AI doesn't go to the warehouse and guess. It goes through the genie, which already knows which source to trust and which tables have to be summed rather than read. That single change killed most of the confident-wrong-answer problem. The knowledge that used to live with one or two people now applies automatically to every question the whole company asks.
But governed queries still left us with the original problem. A live, correct number locked inside a skill you have to remember to run isn't a dashboard. It goes stale the moment it's generated, and refreshing it means re-running the whole thing and burning the tokens again. That's how we ended up with twelve of them.
Dashboards as code
The second piece was deciding that a dashboard should be a permanent thing, not a thing you regenerate.
So dashboards now live in code. Each one is a folder in the same repo as everything else: a small config file that says what it is and who owns it, the page itself, and the SQL queries that feed it. You build it with Claude, push a branch, get a live preview link straight away, and open a PR. The data team reviews the SQL. It merges. It's live, and it stays live, querying Snowflake directly every time someone opens it. No re-running. No regeneration tax. No stale snapshot.
What I didn't expect to matter as much as it does is that the SQL is committed alongside the dashboard, in plain files, where anyone can read it. And it has to carry its own definitions, because every dashboard has a chat assistant built into it that answers questions about the numbers. Ask it "how is this calculated?" and it reads the report's own committed SQL and config to answer. Nothing else. So the definition has to be in the file, or the assistant can't explain it.
That requirement changes how the queries get written. Take one of our real ones, the engineering investment split. Open the query and the comments tell you exactly how the number is built: which custom field carries the investment category, why sub-tasks are excluded, why a ticket that skipped "in progress" gets a half-hour minimum so it still shows up, which project boards are left out and the reason for each. The definition of the metric lives with the metric, partly so a human reviewer can sanity-check it, and partly because it's literally what the in-dashboard assistant reads when someone asks.
That matters more than it sounds. The old dashboards were opaque. You saw a number and you either trusted it or you didn't, and mostly you didn't. Now, if you want to know how a figure is calculated, you ask the dashboard and it tells you, grounded in the actual query behind the number. A number you can interrogate is a number you can trust.
The other thing I like is that it sits in the same place as the rest of how the company operates, a repo we call ably-os. Skills define how our agents think. Automations define how workflows run. Context defines what the agents know. Dashboards define how the company sees its data. Same repo, same PR process, same governance. A dashboard is no longer a one-off artefact someone made and forgot. It's a governed part of the system.
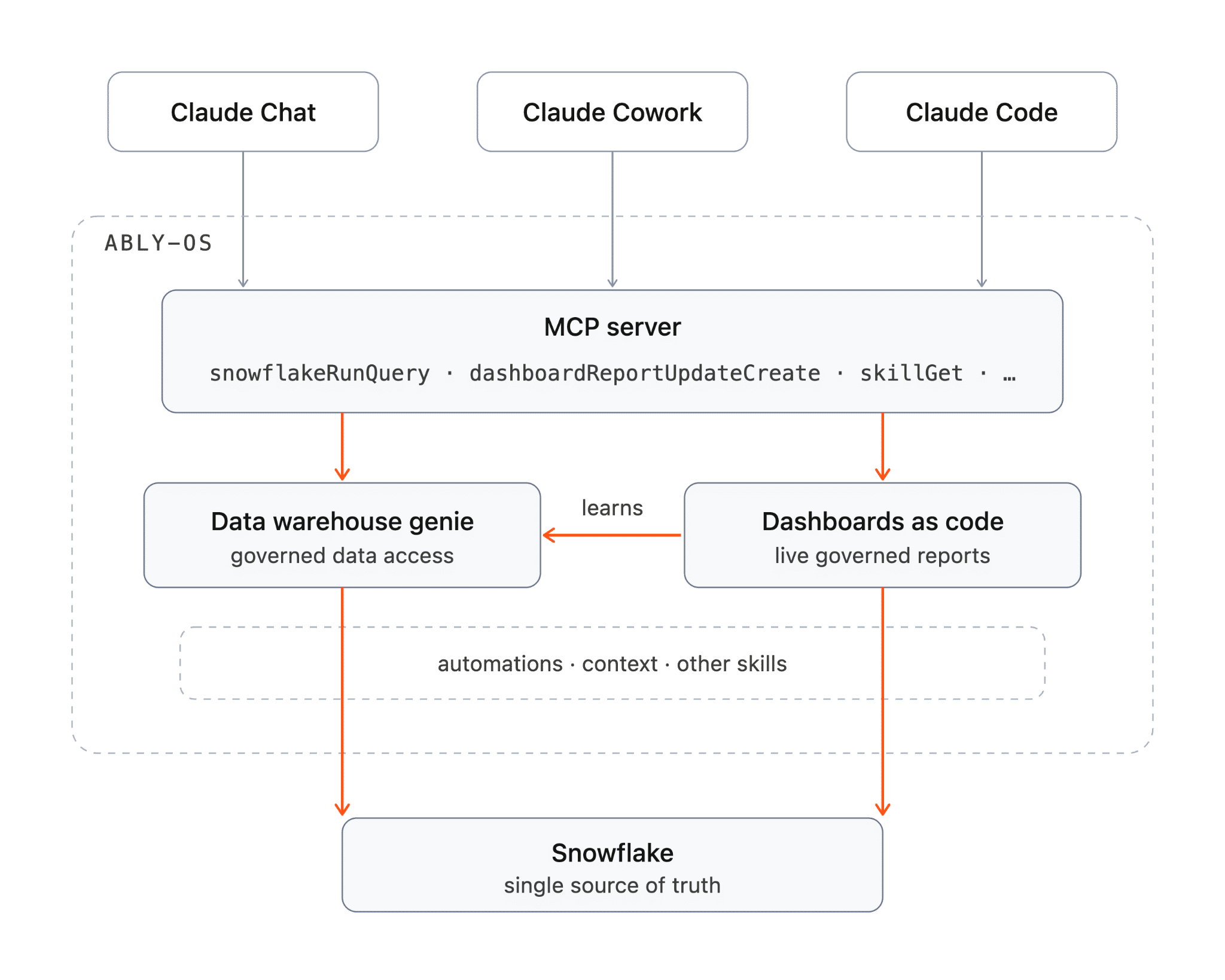
It's live in production now. The reports people actually use, the engineering investment split, AI Transport adoption, weekly shipping, are served from it, fed by governed queries, current every time you look.
Anyone can build one
The obvious objection to "dashboards live in code" is that it sounds like something only engineers can do. It isn't, and that's the part I'm proudest of.
We have a skill whose whole job is to help you build a dashboard. It's served through our MCP, so it works wherever you're already talking to Claude, in Chat, in Cowork, in Code, in any assistant connected to our MCP. You don't need a local checkout of the codebase. You don't need to know how the dashboards app is wired.You ask to build a dashboard, and the skill walks you through it. It relies on the genie to find the right sources and avoid the traps, then runs the queries against Snowflake through our MCP so you can see real numbers come back before anything is committed. What you get is governed from the start, rather than something to be corrected later. It opens the PR for you.
So someone in marketing, or finance, or CS, who has never touched the repo, can contribute a governed dashboard. They describe the report they want. The skill handles the data sources, the SQL conventions, the component kit, the config. They get a preview link and a PR.
And this is exactly why the automated review matters. Opening the door to the whole company only works if there's something checking the work on the way in. The reviewer is what makes it safe to let anyone build. You get the reach without losing the governance.
The part that compounds
Here's the bit that makes this more than a tidy-up.
Building a dashboard almost always teaches you something the genie didn't know. Which table actually holds the signal. How to work around a rollup that doesn't exist yet. An SDK string the data model hasn't parsed. A grant gap that returns an empty result under one role. The person building the report discovers the workaround, uses it, and normally that knowledge would stay trapped in the report. The next person asking the same question hits the same wall and rediscovers the same workaround from scratch.
So we put an automated reviewer on every dashboard PR. It runs four checks: that the report used the genie as its source, that every headline metric is defined in the committed files so the chat assistant can ground on it, that the report is built from the shared component kit, and the important one, that the genie could actually answer this report's question on its own. If the report relied on knowledge the genie doesn't have, that's flagged as a coverage gap, and the fix is to push that knowledge back into the genie rather than leave it in the report. Fix it in the genie first.
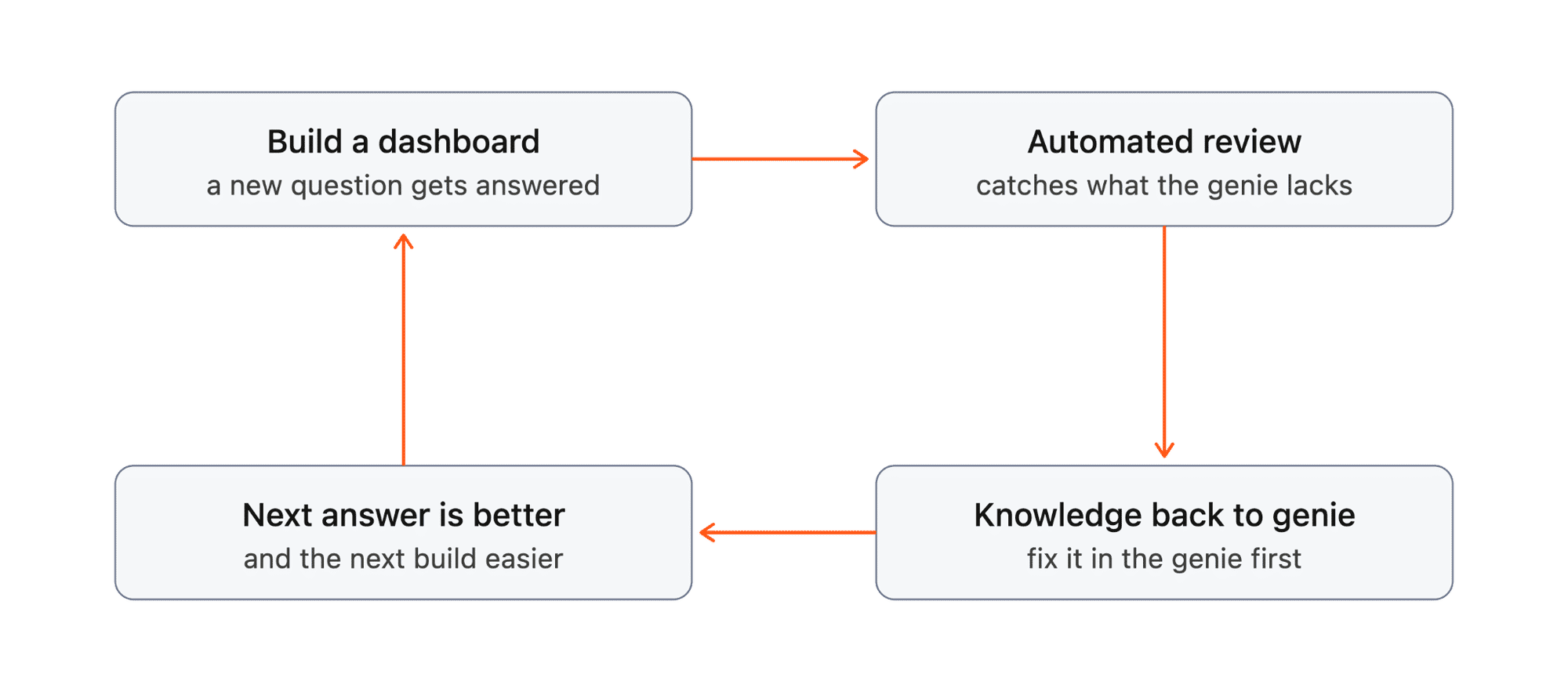
That's what makes the flywheel real. Every dashboard we merge becomes a known-good, reviewed query in the repo, a canonical answer to a real business question. And anything we learned building it goes back into the genie. So the next time someone asks Claude that question, or one near it, the answer is already there and already right.
The more dashboards we build, the better the AI gets at answering questions correctly. The governed reports and the ad hoc questions stop being two separate things and start feeding each other. Every answer we lock down makes the next answer more likely to be right.
This is becoming our default. We're now moving the dashboards people actually rely on into code and winding Metabase down. The tool everyone had quietly abandoned is being replaced by one anybody can contribute to, that stays current on its own, and that the whole company can interrogate and trust.
We started with twelve dashboards nobody asked for, built because the real tools had failed. The answer wasn't to ban people from building. It was to give the company one governed place where the right number lives, and to make the AI smart enough to find it. The dashboards were never the problem. Not knowing which number to believe was.