

Building AI agents that work reliably in production requires solving problems that have nothing to do with AI. While teams focus on prompt engineering, model selection, and agent orchestration, a different class of challenges emerges at deployment. These have little to do with LLMs and everything to do with keeping agents and clients synchronized in realtime.
Over the past few months, we've spoken with engineers at over 40 companies building AI assistants, copilots, and agentic workflows. The same infrastructure problems surfaced repeatedly – problems with distributed systems, not models.
The infrastructure gap in AI applications
When you're building an AI agent that streams responses to users, you're not just building an AI system. You're building a distributed realtime application where state needs to stay synchronized across components that connect, disconnect, and reconnect unpredictably.

These are the technical challenges that came up consistently:
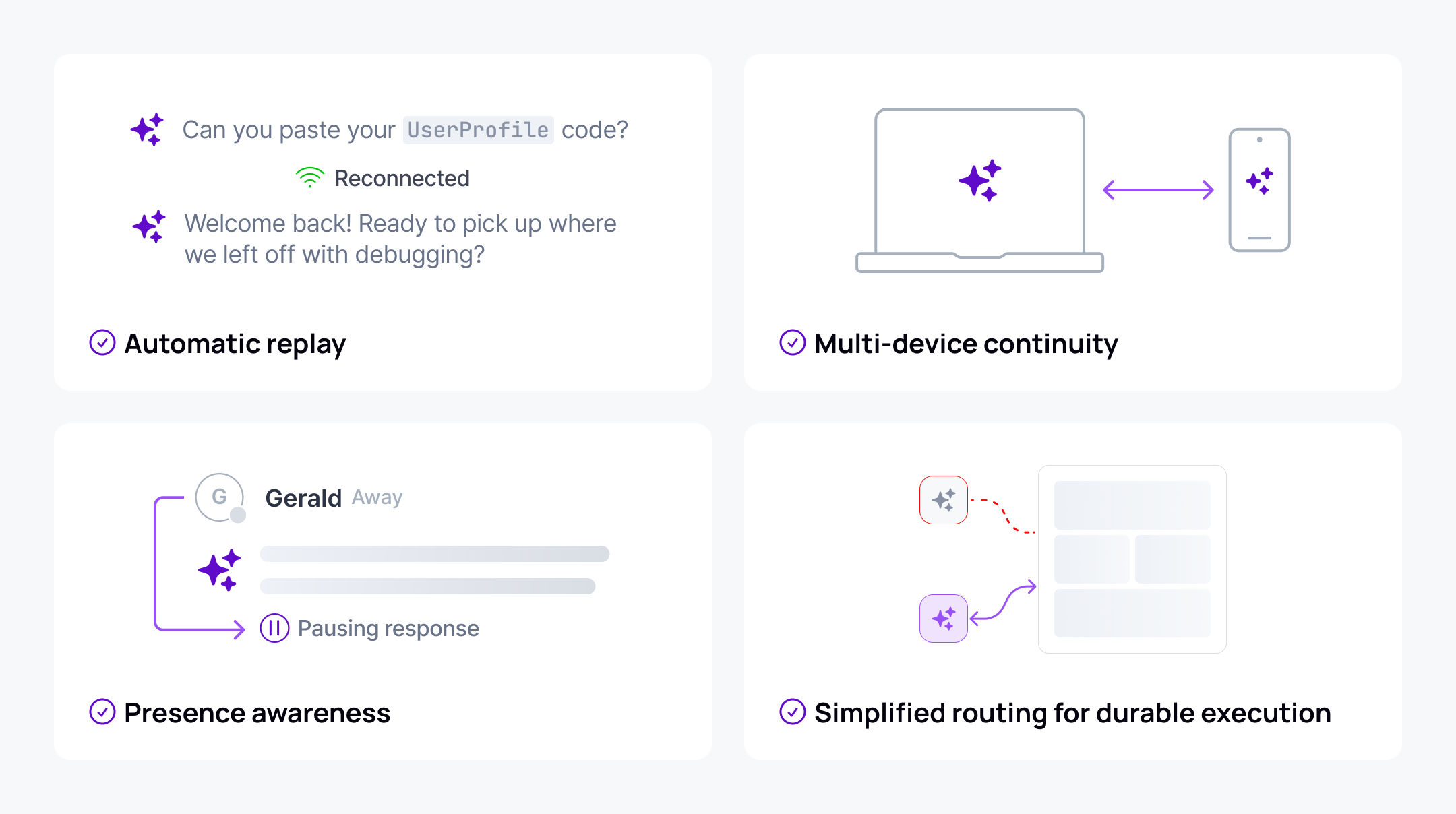
Connection management at scale. Managing WebSocket or SSE connections between agents and clients becomes complex quickly. Connections drop during mobile network handoffs, page refreshes, and tab switches. Each disconnection requires handling buffering, replay logic, and state reconciliation.
Client-specific state tracking. Agents need to track what each individual client has received, across multiple devices and multiple users. When a client reconnects, the agent must determine exactly which messages they missed and replay only those, without gaps or duplicates.
Distributed agent routing. In distributed deployments, reconnecting clients need to reach the correct agent instance. This gets harder still with durable execution patterns, where agent state persists but the instance handling it may change.
Continuity between historical and live data. Clients loading a conversation need continuity between historical messages and live streaming responses. Gaps in this transition break the user experience.
What teams actually wanted wasn't complicated: token streams that survive network interruptions, conversations that work across device switches, multi-user sessions that stay synchronized, and long-running agent work that continues when users go offline.
These requirements describe a transport layer problem – the infrastructure between agents and clients that handles delivery, synchronization, and state management.

Technical patterns for AI workloads
Several technical patterns emerged from observing how teams build AI applications on top of pub/sub infrastructure.
Token streaming with message appends. LLMs stream tokens individually, but storing thousands of separate token messages per response creates inefficient channel history. Loading a conversation would require replaying thousands of individual tokens.
The solution is a message append operation: publish an initial message, then append subsequent tokens to it by referencing the message serial. Clients joining mid-stream receive the complete response so far in a single update, then receive subsequent appends. Channel history contains one compacted message per AI response rather than thousands of token fragments.
Server-side rollups batch appends within a configurable time window (default 40ms) to stay within rate limits while maintaining smooth streaming UX. This handles the impedance mismatch between token-by-token streaming from models and efficient message storage.
Annotations for citations. AI responses that reference external sources need citation metadata attached without modifying the response content itself. Publishing citations as annotations – metadata referencing a message serial – keeps the response clean while enabling rich client-side rendering.
Annotations include a type (e.g., citations:multiple.v1) and arbitrary data: URLs, titles, character offsets for inline citation markers. The transport aggregates annotations automatically – clients receive a summary ("3 citations from wikipedia.org, 2 from nasa.gov") rather than processing every individual event.
Messaging patterns for agentic workflows. The bi-directional nature of channels enables several agent interaction patterns:
Tool calls: Agents publish tool invocations with a toolCallId for correlation. Clients can render generative UI (displaying a weather card when get_weather is invoked) or execute client-side tools (agent requests GPS location, client executes locally and publishes the result back).
Human-in-the-loop: Agents publish approval requests. Authorized users review and respond over the same channel. The agent verifies the approver's clientId or userClaim before executing sensitive operations. The request-response pattern fits naturally into bi-directional channels.
Chain-of-thought streaming: Streaming reasoning alongside output can happen inline (single channel, distinguished by message name) or threaded (separate reasoning channel per response, subscribed to on demand to reduce bandwidth).
Why this matters for production AI
The gap between prototype and production AI isn't primarily about model capabilities. It's about infrastructure that handles the messy realities of distributed systems: network interruptions, device switches, concurrent users, and agent failures.
When agents and clients communicate through a proper transport layer rather than direct connections, entire classes of complexity disappear. Agents don't track connection state. Reconnection logic isn't custom code in every agent. Multi-device support isn't a feature you build, it's a property of the architecture.
The interesting problems in AI infrastructure aren't always where you expect them. Sometimes the hard part isn't the AI – it's keeping everything synchronized.
Ready to build resilient AI applications? Explore the AI Transport documentation for implementation patterns, code examples, and architectural guidance.


