

Take any AI agent demo from the last six months. It works.
Now ship it to real users on real networks, and real devices, and real attention spans. A meaningful share of those users will never finish their first conversation cleanly. Not because the model gave a bad answer. Because the connection dropped, the tab refreshed, the phone took over from the laptop, or the spinner kept spinning forever.
Over the last year, we noticed a pattern in our own customer base. A growing number of teams were building AI agent products on top of Ably. We weren't sure what to read into it. Was this a real new product opportunity for Ably, or was it specific to those customers and the way they happened to be using us? We went to find out. We interviewed 38 companies building AI products at scale, and we evaluated 37 vendors across the AI infrastructure landscape. The results were encouraging for Ably and surprising on their own terms. Almost everyone is hitting the same wall. None of those problems are model problems. And nobody is really to blame, because there isn't a layer in the stack today that solves them.
The capability problem itself is largely solved. Models can hold long conversations, call external tools, coordinate with other agents, and produce useful work over hours. That didn't happen because models got smarter on their own. It happened because larger context windows, context engineering, tool calling, and persistent memory all matured at once. The combination is what paid off.
What hasn't matured at the same pace is the agent communication experience: the way agents reach users, recover from failures, and stay reliable across devices.
Why the delivery experience matters more than the model
Imagine ordering food through a delivery app where the food is great but the app stops working halfway through. The map freezes. You don't know when the driver is coming. You refresh, the order seems to vanish, then the food turns up an hour later with no warning. The food was fine. The experience wasn't, and you'll order from someone else next time.
Uber and Deliveroo didn't win because they invented better taxis or better food. They won because they made the experience reliable and transparent. That's the shift happening in AI right now. The product winners are not the ones with the slightly better model. They're the ones whose product feels continuous, transparent, and trustworthy when the network doesn't cooperate.
The current state of AI agents on this front is, broadly, not good.
The four failure modes we kept seeing
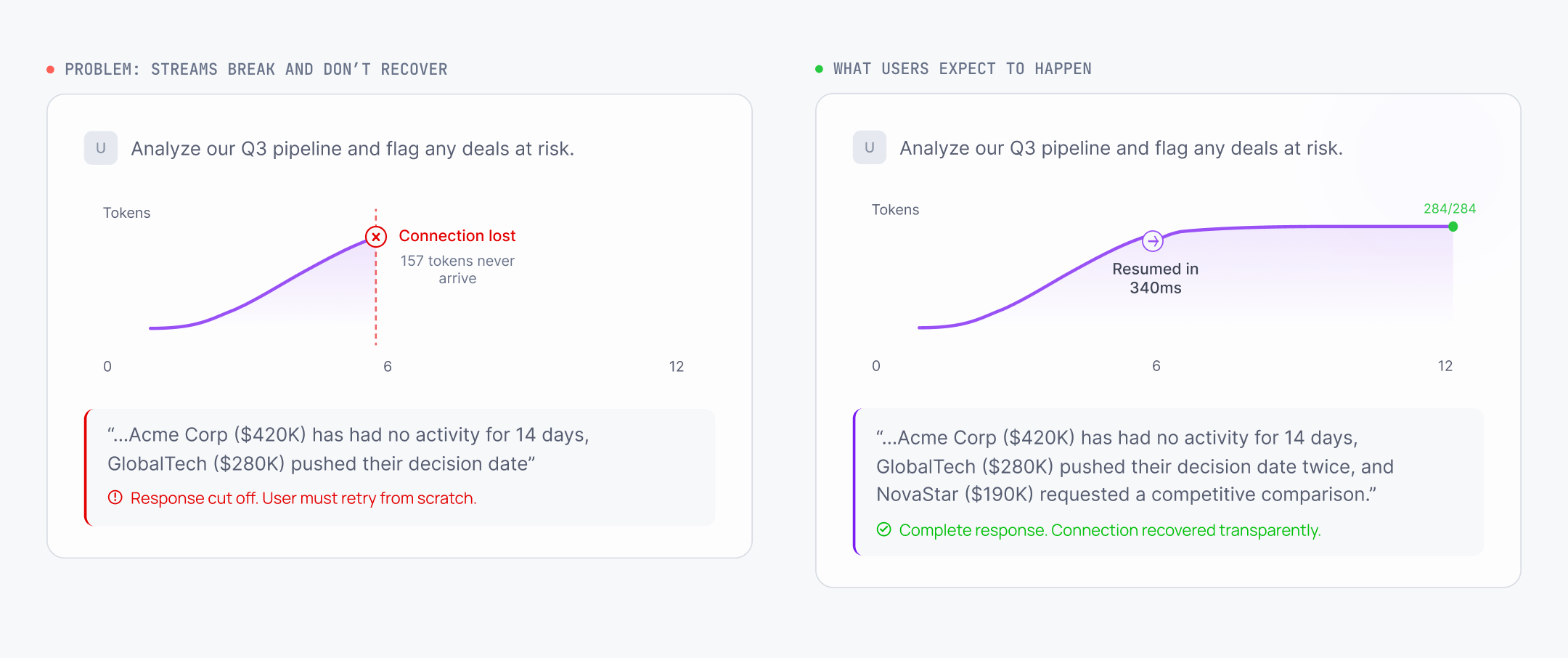
Streams break, and you lose the live state
HTTP streaming over Server-Sent Events works fine in development. In production, every hop between the server and the user has its own timeout, and the cumulative effect is that long streams break.
The real list, with sources you can check yourself: AWS Application Load Balancer kills idle connections after 60 seconds by default. Cloudflare returns a 524 error after roughly 100 seconds for proxied origins. Istio and Envoy default to a 5-minute stream idle timeout. Corporate proxies buffer un-chunked text/event-stream responses because the body has no Content-Length. Mobile carriers rebind NAT entries on idle TCP flows. Browsers throttle background tabs.
When any of these fire, you don't get to recover the live state. You can replay completed state from a buffer if you wrote one. The bit the user was actually watching is gone. It's the same as your delivery app crashing mid-route. You still get your food. What you lose is the experience of watching it arrive.
Sessions belong to the browser tab, not the user
Almost every agent framework today is point-to-point. One connection, one device. Switch from a laptop to a phone, the conversation doesn't follow. Refresh, the live stream is gone.
This isn't a framework problem. It's an HTTP problem.
The frameworks know this. Vercel and TanStack have both shipped connection adapter interfaces precisely so a different transport can be plugged in. They're not failing to solve it. They're making space for someone else to.
Of the 37 vendors we evaluated, 32 have no multi-device fan-out for AI sessions at all. The user is locked to whichever tab opened the conversation.

Users can't get control back mid-stream
Once an agent starts generating, HTTP gives you no clean way to route a new instruction back to that running agent. The request is in flight. The response stream is one-directional. Routing a new message to the same running agent without significant engineering complexity is genuinely hard.
We spoke to one of the largest customer support platforms in the world. They told us they disabled all user input while the agent was responding because handling interruption reliably was technically too difficult. We have all felt this. You're watching the agent go down the wrong path, and you can't stop it. It's jarring. It isn't how we talk to humans.
The coding agents are the leading indicator. Tools like Claude Code let you interrupt, redirect, and stop mid-stream because that's what feels natural. Once people get used to that, they'll expect it from every agent product they touch.
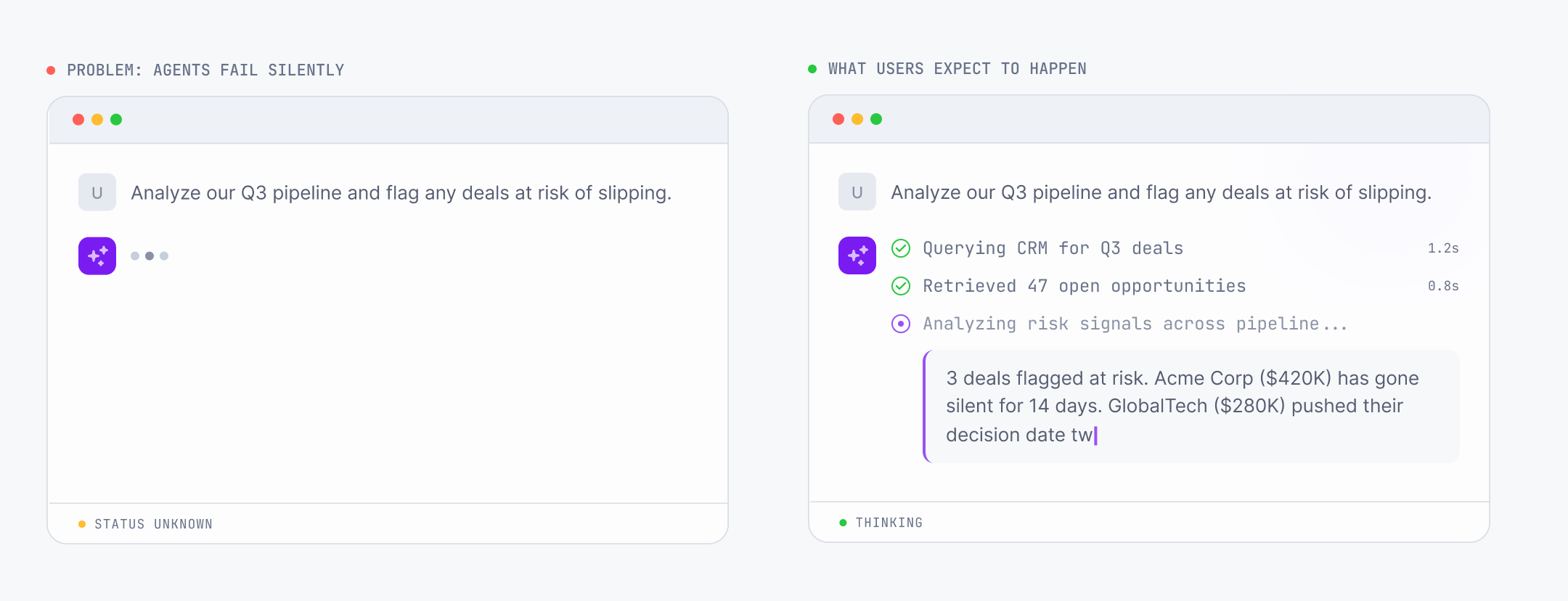
Agents fail silently
From a client's perspective, an idle SSE connection looks identical to a dead one. There's no signal coming down the wire either way. So when an agent crashes, stalls, or quietly loses its connection, the client has no way to know.
This is hard, not lazy. The transport itself doesn't carry a reliable health channel across unreliable networks. Unless the agent can explicitly say "I've actually failed," the client can't tell the difference between a thinking agent, a stalled agent, and a dead agent. Three completely different states, indistinguishable on the user's screen.
33 of the 37 vendors we evaluated have no agent health signal at the infrastructure level.
What developers are building instead
These failure modes are well known. The workarounds are documented. Teams aren't discovering unknown territory. They're independently rebuilding the same pieces.
The pattern is consistent. Engineers add a buffer (usually Redis) between the agent and the client, so the live stream can be replayed on reconnect. They build polling or queueing on top, so a new instruction can find the right running agent. They add fan-out so multiple devices can attach to the same session. Most teams either accept the broken experience and move on, or pour engineering effort into plumbing that doesn't differentiate their product.
Vercel's lead maintainer summarised the underlying constraint in a widely referenced GitHub issue: "to solve this we would need to have a channel to the server that allows transporting that information. WebSockets are one option." We've just shipped an Ably plugin for the Vercel AI SDK that does exactly this. Upstash now positions Redis Streams as "a Pusher/Ably alternative" for resumable AI streaming. Stardrift documented their four-step evolution to a fully custom transport: "nothing here is rocket science, but getting to this point took some iteration." A Pydantic AI user on Hacker News described their setup as "a lot of glue."
Every serious production team independently arrives at the same conclusion: generation has to be decoupled from delivery. Most of them end up building their own version of the same architecture to do it.
Why this is a delivery layer problem
The first generation of AI applications was simple. User sends a prompt, model returns a response, done. Request-response handles that. SSE handles streaming.
The applications being built now look different. Sessions last minutes or hours. Agents make tool calls mid-conversation, sometimes across multiple steps. Multiple agents work on the same task. Humans need to be in the loop, approving actions, providing input, stepping in when the agent reaches its limits. The patterns that worked for request-response become liabilities once the session is stateful, multi-participant, and expected to survive network drops, device switches, and crashes.
The frameworks have been honest about this. TanStack AI shipped a ConnectionAdapter for third-party transports. CrewAI received a detailed feature request for WebSocket-based human input streams, with reconnection semantics and an offer to contribute the pull request, and closed it as "not planned."
These are deliberate decisions, not oversights. The delivery layer is a different domain. It needs persistence, fan-out, presence, multi-region routing, mobile delivery semantics. The agent frameworks are saying, plainly, that this isn't theirs to build.
What the missing layer needs to do
When most people hear about this problem, they think it's about streaming reliability. Reconnects, timeouts, duplicate tokens. That's part of it, but only part. That's why workarounds built directly on HTTP keep falling short.
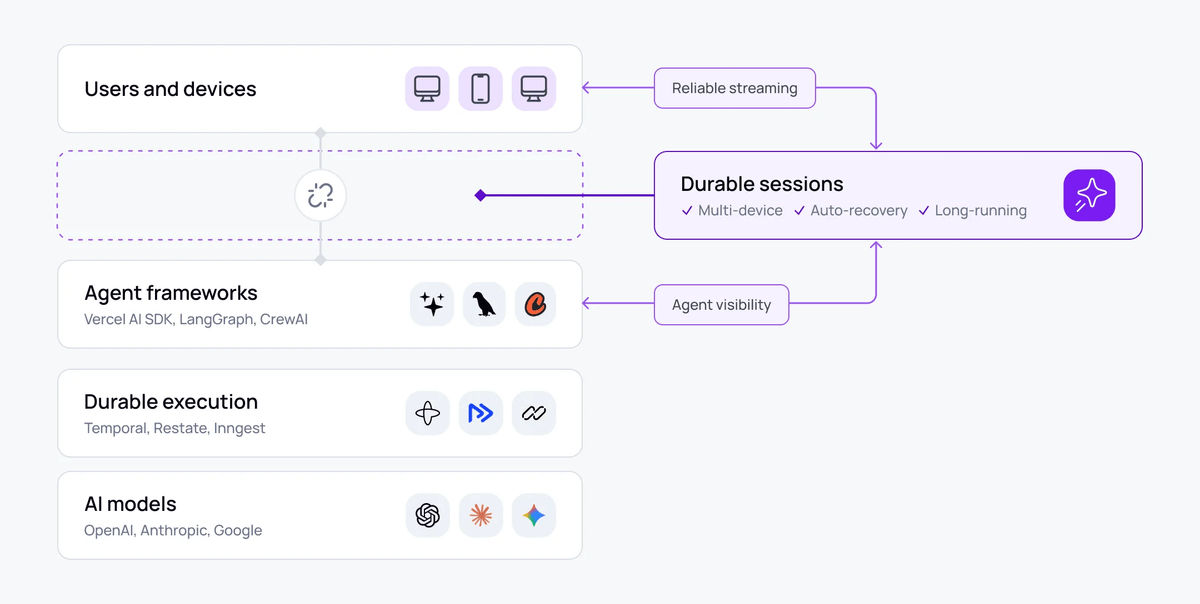
The category forming around this is what we've been calling durable sessions. A durable session is a persistent, addressable connection between agents and users that outlives any single connection, device, or participant. Disconnect and reconnect, the session is still there. Switch devices, it follows you. Agent crashes and respawns, the session survives.
This is distinct from durable execution. Tools like Temporal make the backend crash-proof. Durable sessions make the user experience crash-proof. Both matter, and they solve different halves of the problem.
In practice, that means a session that exists separately from any individual connection. Reconnection becomes reattachment. A device switch is another subscriber joining. Multi-agent coordination is fan-in to a shared session. And it has to handle the things people don't think about until they're burned by them in production: presence (so the agent knows when no one is watching and can pause expensive work), shared collaborative state, and organization-side handover (an internal expert joining a live session on a different device, hours into a conversation, with full context).
None of this depends on which model you're running. That's the point.
Where this is going
ElectricSQL published a "Durable Sessions" piece in early 2026 with the line that captures this best: "when the stream fails, the product fails, even if the model did the right thing."
There's a real bifurcation forming. The frontier AI labs spend tens of millions of engineering dollars building this layer themselves. They have the people and the budget to do it. Everyone else either accepts the broken experience or burns engineering effort rebuilding fragments of it. That's what makes this a product category, not only a technical headache.
We've been building realtime infrastructure since 2016. The same engineering that delivers tournament telemetry, live chat, and presence at scale is what's needed here. So our bet is straightforward: the durable session layer should be available to every team, not only the ones with frontier-scale engineering. Once it is, the things even Claude Desktop and ChatGPT don't yet do well, things like interruption mid-stream, multi-device handover, presence-aware cost control, and organization-side escalation to a human expert on whichever device they happen to be on, become available to teams who don't have a hundred engineers to throw at them.
The capability problem is solved. The delivery problem is where the work is now. The food is fine. The delivery is what wins.
Ably AI Transport is this layer, built properly. If you want to see what it looks like in code, the getting-started guide walks through the implementation with Vercel AI SDK. And if you want to talk through what this would look like in your stack, we're easy to find.
Frequently asked questions
What is a durable session?
A persistent, addressable connection between an agent and a user that outlives any single connection, device, or participant. Disconnect and reconnect, the session is still there. Switch devices, it follows. Agent crashes and respawns, the session survives. This is distinct from a standard WebSocket or SSE connection, which ends when the network drops. See AI Transport docs for how the session model works in practice.
What's the difference between durable sessions and durable execution?
Durable execution (tools like Temporal) makes the backend crash-proof. The agent's workflow survives infrastructure failures. Durable sessions make the user experience crash-proof. The conversation survives network drops, device switches, and participant changes. Both matter, and they solve different halves of the problem. A backend that recovers perfectly is useless if the user's stream died and they never see the result.
What should a durable session layer handle beyond streaming?
Beyond reliable streaming and reconnection, a durable session layer needs presence, so the agent knows when no one is watching and can pause expensive work. It needs shared collaborative state, so multiple participants see the same conversation. And it needs organization-side handover: an internal expert joining a live session on a different device, hours into a conversation, with full context. These requirements are what distinguish a session layer from a transport layer.


