If you've built a conversational AI feature, you know the pattern. The client sends a message, the backend calls a model, and the response streams back over HTTP. SSE mostly, or WebSockets if you need bidirectional. For a single user on a single device, it works well.
The trouble is that the best AI products right now have moved well past that.
Users of the products setting the pace today can interrupt an agent mid-response, pick up a conversation on their phone where they left it on their laptop, collaborate with a colleague in a single session. Building those experiences on standard HTTP streaming is where things start to come apart, and where we keep seeing the same patterns of pain.
The root cause is that in the default pattern, the HTTP connection is the session. When the connection drops, the session drops.
What breaks and why

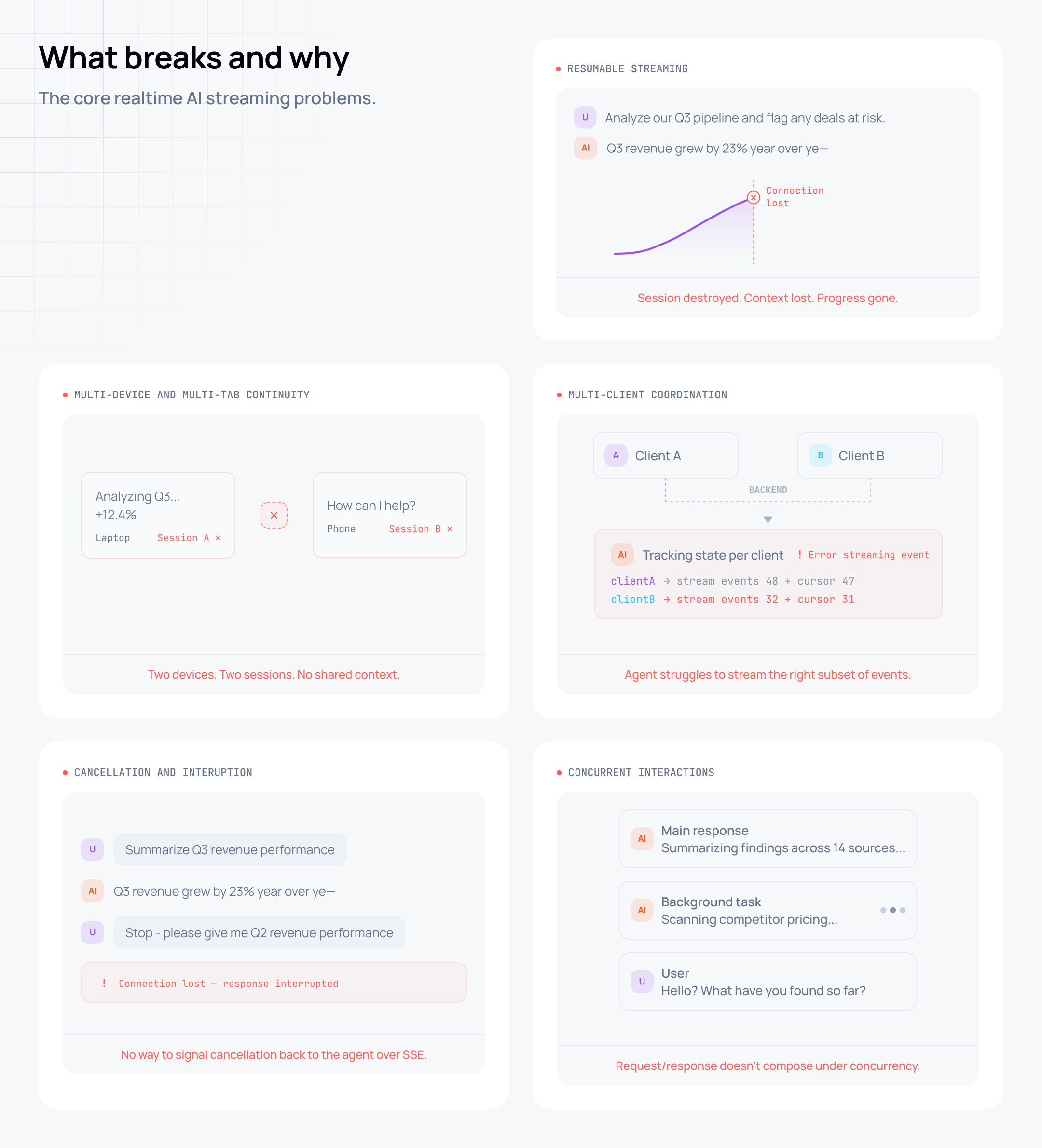
Resumable streaming. When an LLM streams a response and the connection drops, the response is gone. The client can poll for a completed version stored in a database, but that in-progress stream is lost. Users who reload mid-response, switch from Wi-Fi to mobile, or hit a corporate proxy timeout learn not to trust the product.

Multi-device and multi-tab continuity. The stream is tied to the connection that started it. Any other tab or device has to wait until the response is complete and they either poll or refresh. For something that's supposed to feel like a live conversation, that's a real problem.
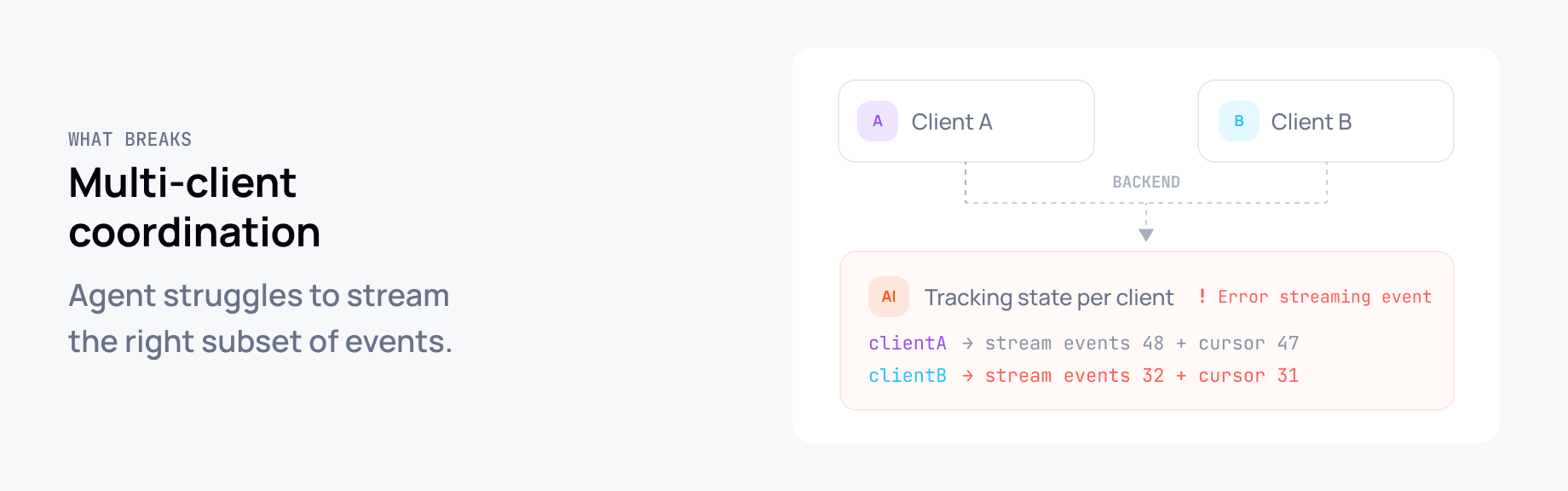
Multi-client coordination. Two users in the same session means building pub/sub on your backend. The agent has to track which clients are connected, what each one has seen, and stream the right subset of events to each. That complexity lands entirely in your application code. Getting it right at scale is a lot of engineering for something that should be a solved problem.
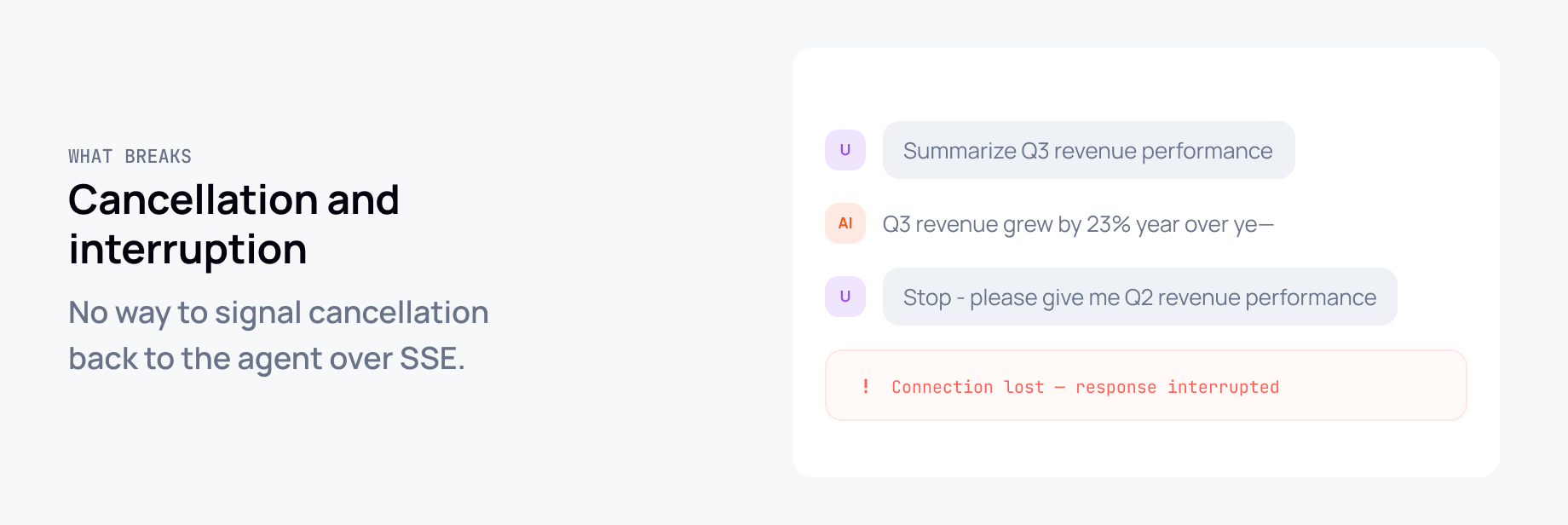
Cancellation and interruption. SSE is a one-way pipe. There's no way to signal cancellation back to the agent over the same connection - the only option is to disconnect. Which is indistinguishable from a network blip. Targeted cancellation, interrupt signals, message queuing: none of it is clean.

Concurrent interactions. The most capable AI products support multiple things happening at once in a session: a main response, a background research task, an agent editing a document while you ask questions about what it's doing. The standard request/response model doesn't compose well under that kind of concurrency.
Why we built a dedicated SDK for this
We've had the infrastructure to solve these problems for a long time. Ably channels have the right primitives: history, presence, connection resumption, message ordering, delivery guarantees. Teams have been building AI streaming on top of Pub/Sub for a while, and we've documented the patterns, including how to handle token pipelining so you're not waiting for acknowledgement between every token.
But there was still a meaningful gap between "you can build this on Ably" and "here is a drop-in solution." Getting concurrent turns right, managing message relationships for conversation branching, abstracting over different model provider event schemas: each of these is solvable, but taken together they're a meaningful chunk of work. And every team doing it was solving roughly the same problem from scratch.
That's why we built the Ably AI Transport SDK.
At its simplest, setting up a client-side session is two lines:
const channel = ably.channels.get('my-session')
const transport = createClientTransport({ channel, codec: UIMessageCodec })
Line 1 gets (or creates) an Ably channel called 'my-session'. This channel is the session - the shared, durable pipe that all messages flow through, rather than a direct HTTP connection that dies the moment the network hiccups.
Line 2 creates a client transport attached to that channel, using UIMessageCodec to tell it how to decode messages (in this case, Vercel AI SDK's UIMessage format). Any client running this same code with the same channel name - a second tab, a phone, a colleague - is automatically in the same session.
What the SDK does
Instead of streaming from agent to client over a direct HTTP connection, you stream through an Ably channel. The channel becomes the session layer. Any client subscribing to that channel can consume the response and pick up from where it left off after reconnecting, regardless of when it joined.
What would otherwise live in your application code (managing concurrent turns, tracking which messages belong to which turn, exposing abort signals for cancellation) the SDK handles. Clients that reconnect mid-stream catch up from their last received message automatically.
Tech stack agnostic by design. One thing I was focused on early was making sure this didn't force you to change your AI stack. Teams use different model providers, different frameworks, different ways of wiring it together. The SDK handles this through a codec model: you specify which provider or framework you're working with, and it translates that provider's event schema to the channel. We ship codecs for the Anthropic SDK and the Vercel AI SDK today.
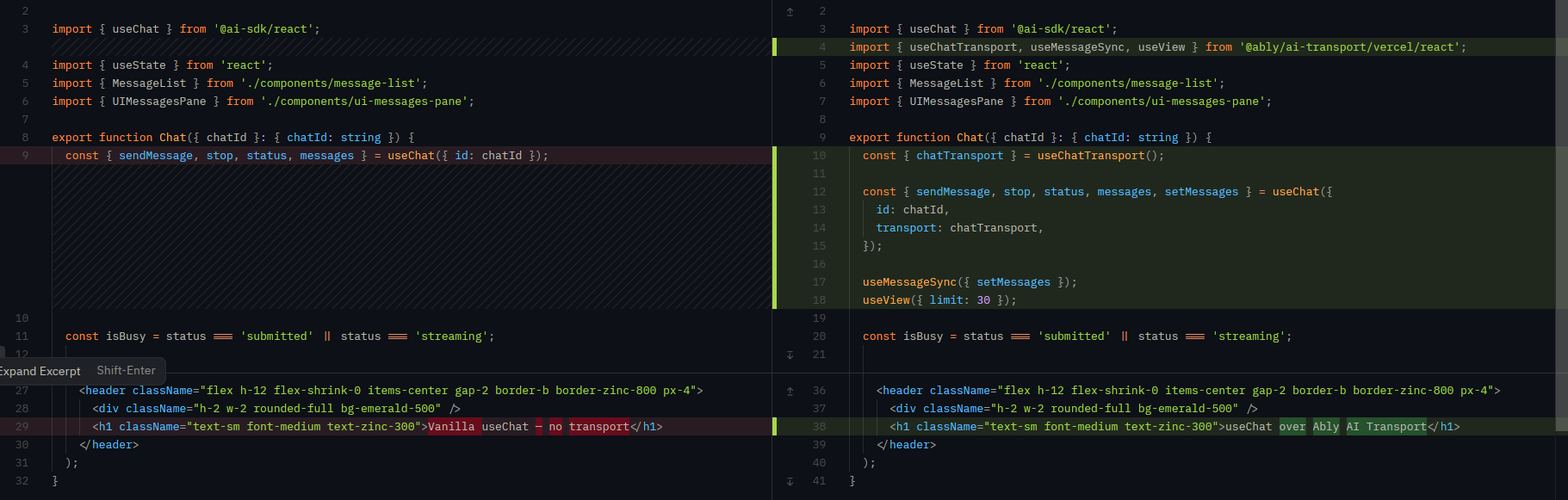
If you're using the Vercel AI SDK with the useChat hook, integrating the transport takes a handful of lines. You get resumable streaming and multi-client support without touching the rest of your application.
const channel = ably.channels.get('my-session')
const transport = createClientTransport({ channel, codec: UIMessageCodec })
Conversation history and branching. Because everything lives in the channel, client state can be loaded directly from channel history. The SDK also models the tree structure that emerges when users edit or regenerate messages, so you can expose fork navigation without implementing it yourself.
const { nodes, hasOlder, loadOlder } = useView({ transport, limit: 30 })
// Load the next page of older messages
if (hasOlder) {
await loadOlder()
}
Turns. The SDK organizes interactions into turns: a single request/response pair. Multiple turns can run concurrently on the same channel. Each has a lifecycle visible to all subscribers and a client ID identifying who started it. A cancel handle lets you target cancellation precisely, without affecting other active turns.
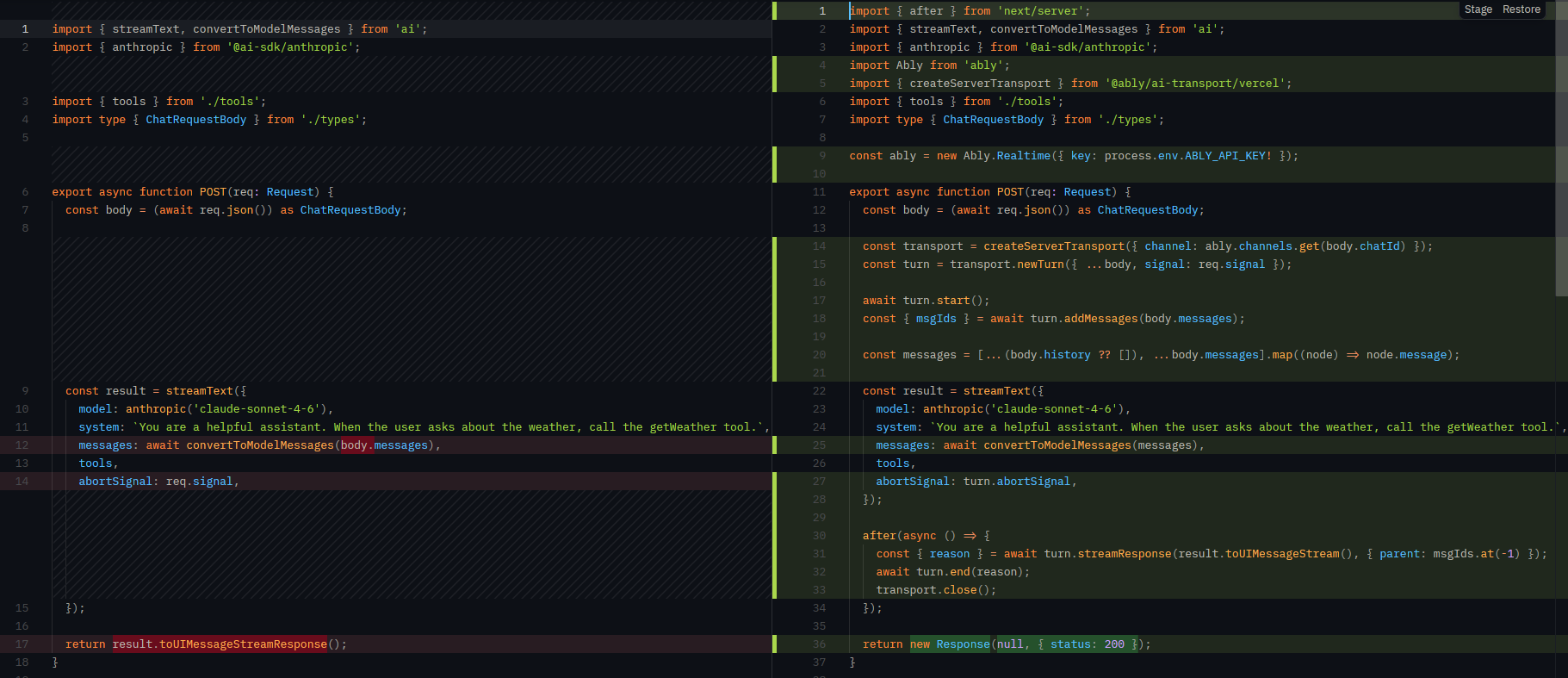
import { createServerTransport } from '@ably/ai-transport/vercel'
import { streamText, convertToModelMessages } from 'ai'
const transport = createServerTransport({ channel })
const turn = transport.newTurn({ turnId, clientId, signal: req.signal })
await turn.start()
await turn.addMessages(messages, { clientId }) // messages: MessageNode<UIMessage>[]
const result = streamText({
model,
messages: await convertToModelMessages(history),
abortSignal: turn.abortSignal,
})
const { reason } = await turn.streamResponse(result.toUIMessageStream())
await turn.end(reason)
The SDK is available now
AI Transport is already in use in production. This SDK is the adoption path we didn't previously have. The docs cover getting started with Vercel and direct Anthropic usage, and there are concept docs on turns, session management, and the codec architecture that go deeper.
The repo is at github.com/ably/ably-ai-transport-js. We're working on codecs for other frameworks and patterns for multi-agent coordination; there's more to do. If you're building in this space and running into any of this, I'd genuinely like to hear what you're hitting.