

At Ably we've been able to make a transformational change in how we build SDKs as a result of what's now possible with LLMs. In this post, I explain how.
The problem
Ably's service is accessed by clients using a range of client libraries, or SDKs. The core Ably Pubsub product is supported by SDKs for a comprehensive range of languages and platforms, both for end-user clients (iOS, Android, Browser, React Native, etc) and servers (Go, Python, Java, .NET, PHP, etc). Each SDK implements the same functionality, with high degree of alignment in their APIs; this is achieved by having a common specification, with nearly 3000 individual requirements in total, across multiple products. This specification aims to be a comprehensive definition of the realtime protocol, and the protocol interactions that occur in response to each operation performed by a client or server, as well as a definition of the client-side functionality and API.
This specification has served as a solid foundation for the development and maintenance of all of the compliant libraries. In the pre-AI era of development, this specification would be used by a developer to formulate a language-idiomatic API for each target platform, build the implementation and write the tests that verify compliance with the specification. Library code, and its associated tests, reference the relevant specification points to provide traceability from spec to implementation, and conformance auditability. Although the development effort for a library could be significant, we benefitted from a wide range of libraries that provided a consistent developer experience and API; maintainability, and SDKs' ability to evolve as the protocol and API were developed was enhanced by that traceability.
That, of course, is fine in theory. The practical reality was that development and maintenance, just like all real-world software development, have challenges. Several challenges arose from the fact that the SDKs were all essentially independent efforts, by individual developers, and this inevitably led to inconsistencies in the interpretation of the (natural language) spec; in how fully specification references were maintained in the code; in how tests were constructed to verify conformance. Some SDKs, for example, would have unit tests for certain functionality, whereas others would test the same functionality via integration tests. Other challenges arose from the fact that different SDKs were built with different levels of completeness, and different combinations of optional features supported. SDK development and maintenance was resource-intensive, and this would mean that we were slow to implement support for new and emerging platforms. The situation overall has been that:
- the level of effort required for ongoing SDK development and maintenance is significant;
- despite there being a high level of consistency in API, and good compliance with the specification, there were still significant inconsistencies in function breadth, test coverage and approach, and traceability.
More significantly, the requirement to implement the SDK side of any new feature would be a real barrier to velocity for product advancement, and this problem would get worse with each new SDK we developed.
Approach
When it became clear how effective LLMs could be when given effective test suites, we decided it was time to take a radically different approach. We have a common, detailed, specification; this ought to make it possible to have a systematic and repeatable process for building SDKs and their tests.
We had decided some time ago that we would create a universal conformance test suite; the Autobahn test suite for implementations of the websocket protocol is an example of where this has been done before. However, there is a key disadvantage to this approach where there is a single implementation of a test suite: the test suite is written in one language, and it therefore it integrates awkwardly, or not at all, with the native test framework that you would naturally want to use on each platform. A nicer approach would be to have a test suite that is portably specified, which can easily be translated into tests for any target language.
As AI coding agents crossed a tipping point of effectiveness, it became clear that there is now a language that can be used to specify tests portably - natural language. More specifically, pseudo code in which control flow can be expressed using specific keywords, but where the statements describing operations or conditions are simply stated in natural language. LLMs are now remarkably effective at translating that natural language into real code. Of course there is a concern about the level of precision that is possible with natural language, but remember that the specification itself is also in natural language. Ambiguity of statements in the spec has rarely been an issue in practice; they are always drafted to be as precise as possible, and when ambiguity is later found, they can usually be corrected by making them more precise, but still in natural language. We decided to try to construct a complete specification for a test suite in natural language, and get LLMs to translate those into tests for the relevant language and platform when targeting a specific SDK.
The result is our Universal Test Suite (UTS).
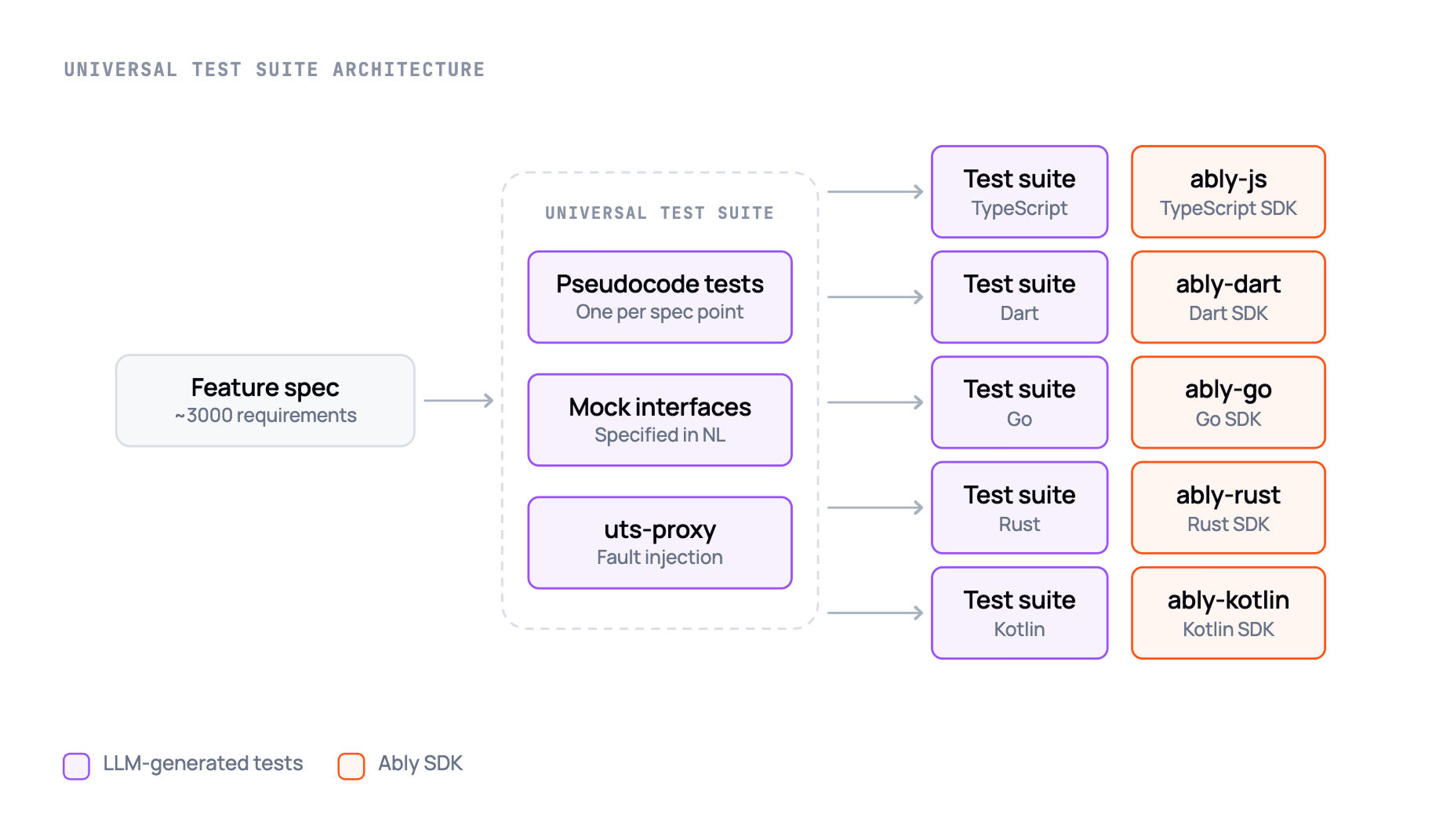
The process we used to generate this was as follows.
The aim was that the tests would be structured so as to address known shortcomings or antipatterns in the preexisting test suites for our SDKs.
Over-reliance on end-to-end tests. Many existing test suites are dominated by end-to-end and integration tests, even though most of the tests are aiming to test a specific API or behaviour. These tests are slow to run, and they can easily be flaky if they are subject to variances in response time from the service. We wanted to have a more conventional test pyramid where all functionality could be exercised via unit tests with relevant interfaces mocked, together with targeted integration tests where necessary - that is, to verify interoperability with the real service, and to exercise parts of the stack that cannot be exercised in any other way.
Inconsistently accessed internal state. Many tests we have, because they are end-to-end, attempt to verify functionality using the public API surface only; they fall back to inspection of internal state if necessary, but this is achieved in ways that are both inconsistent, and unsatisfactory. We wanted there to be a standard set of interfaces that are mocked, and accessible for testing purposes.
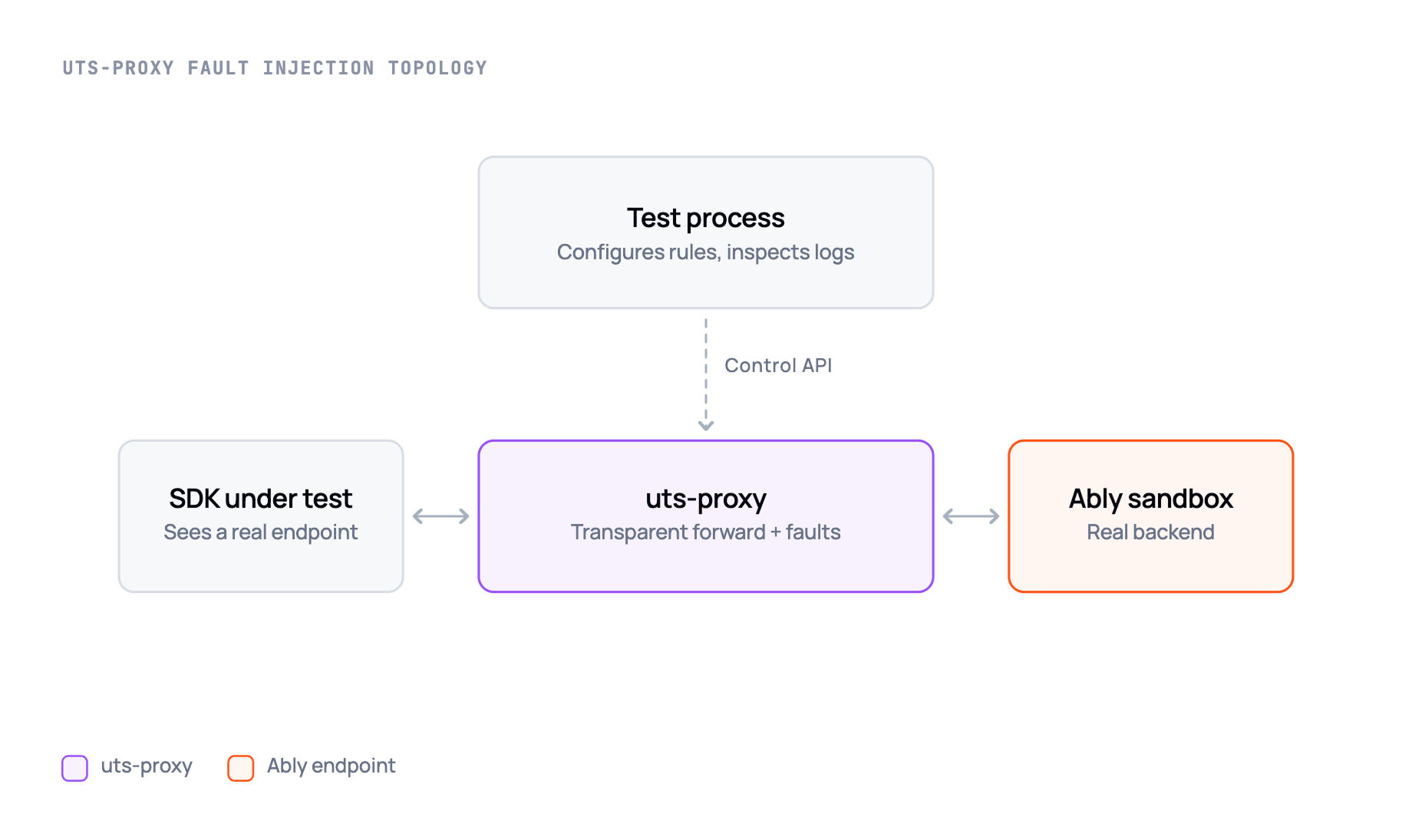
Inconsistently exercised unhappy-path behaviour. Much of the specification of both the protocol and the API defines what happens when operations (requests, connections, etc) fail. For integration tests there needs to be a way to simulate faults in the service or network, so that this behaviour can be tested. Our SDKs took inconsistent, and often unsatisfactory, approaches to doing that. We wanted a standard way in our integration tests of triggering and validating unhappy-path behaviour via injected server faults and behaviours.
Timing-dependent tests. SDKs rely on timers for various timeouts, retry intervals, and other time-dependent behaviour. These time intervals or delays impact on the tests - both because you have to have tests that verify they are correctly working, but also because a specific state, which might be the starting state for a test, is only reached after a timer has elapsed. Unless there is a way to advance time, tests would take a very long time to execute (and still tests can be flaky when there are variances in the time for execution of the test). Our existing test suites took inconsistent and/or unreliable approavhes to this problem. We wanted this to be approached in a consistent way for all SDKs.
Incomplete coverage and poor traceability. Tests were not consistently cross-referenced with the specification items that they tested, so it was not easy to assess specification coverage - the result being then that coverage was incomplete - and difficult to know which tests (and which parts of the implementation) needed to be updated when the specification was changed. It was always a stated requirement that spec references exist in all tests, but without a systematic way of checking and enforcing it, it was never done fully.
The approach taken in the UTS was to define required common mock interfaces; these were specified (also in natural language) and tests for each spec point were created in pseudocode. The entire test suite was written, mainly by LLM but with human review, for each point in the spec.
An integration test proxy was written that can inject nonstandard behaviour under test control, for the unhappy-path integration tests.The UTS proxy mediates interactions between the client under test and the Ably endpoint.
Validation
The next step was to validate those portable test specs by using them to generate tests for an existing library that was believed to be fully compliant with the spec; the target in this case is the Typescript library for nodejs clients. This led to a new suite of more than 1500 tests for that library. Each resulting test was run against that library and any failures was resolved either to be a problem with the test - that is, either a problem in the UTS test spec, or a mistranslation to Typescript - or to a nonconformity in the Typescript library. The result was 16 genuine non-conformities, and 6 cases where the UTS test spec was incorrectly inferred from the spec. That means that more than 98% of the tests passed first time - we took a high level of confidence from this in the approach.
The next step was to use the UTS test suite to generate tests for a brand new library. We have for a while wanted to build a pure Dart library for Ably (since we previously implemented support for Flutter] via plugins that wrap the native Kotlin and Swift libraries). The process for creating a new library requires there to be an API definition - which was substantially based on the existing Flutter API - but, given that, there can be a completely mechanical translation of the UTS specs to the target language. For Dart we were able to prove that, based on the UTS test specs and a target API, an LLM can build a complete test suite in any target language reliably without human intervention. This is largely a parallel activity, in that the generation of one test does not need to share any context with the generation of another test, so an agent can generate a large test suite via subagents, without degradation in quality from context bloat. Tests are generated so that they compile against the target API, but we deliberately make that step happen before implementing the associated library functionality, so the LLM isn't tempted to make a test pass by modifying it.
Library development
This turns out to be the most impactful outcome from this work. The UTS isn't only a way to generate high-quality test suites for every language; it is the thing that enables the SDKs themselves to be very substantially LLM-written with a high level of reliability.
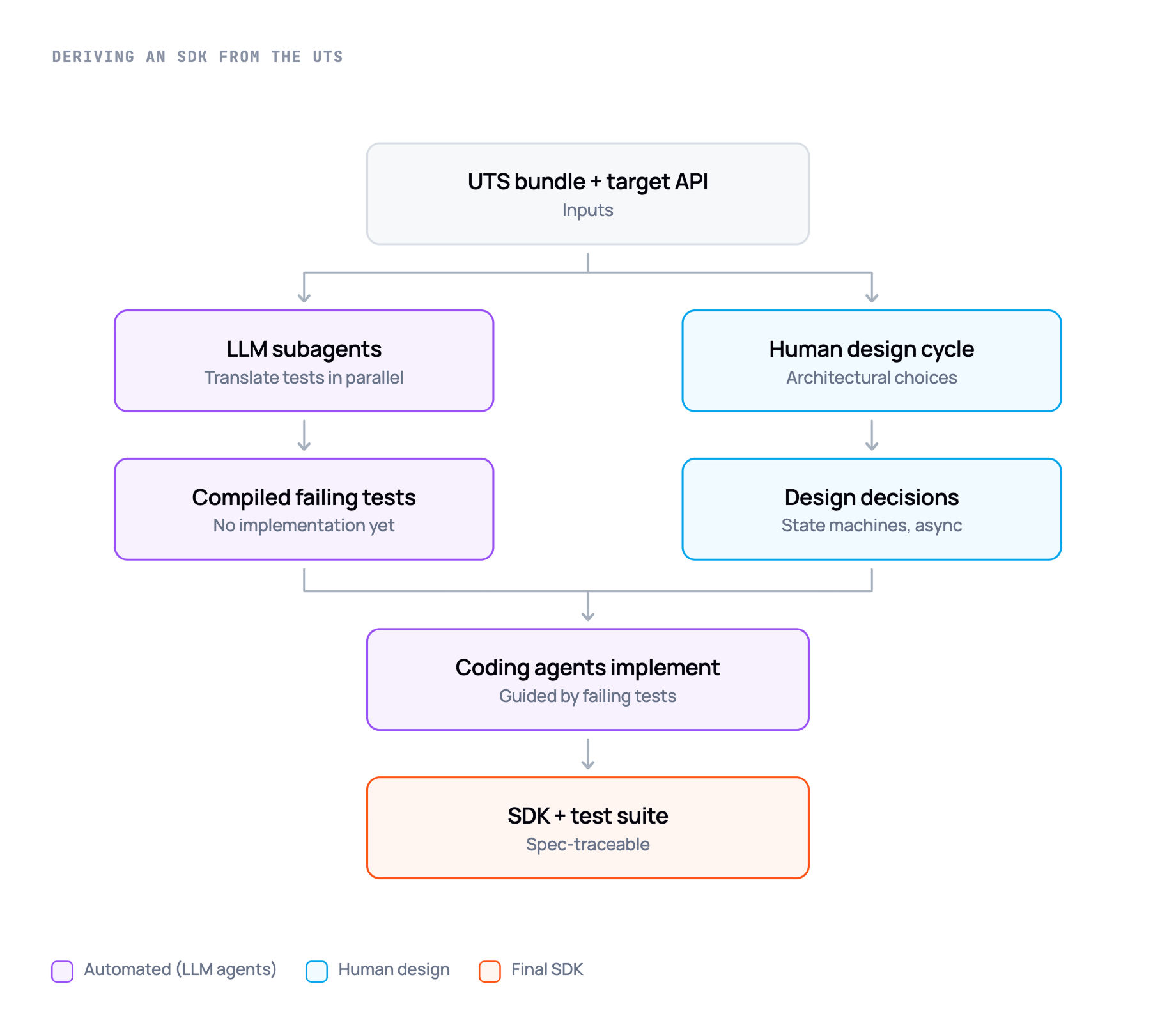
Birgitta Böckeler defines a spectrum of approaches to spec-driven development. Our approach isn't "spec as source", but aims to be as close to "spec + tests as source" as far as possible. The power of LLMs in this setting was already noted by Simon Willison.
The aim was that a design cycle with human input and review could establish the core implementation choices - for example how the connection and channel state machines are implemented, and how asynchrony is handled within the library, and how state change events (that are broadcast to external listeners) are serialised. With that, coding agents would be effective at completing the implementation guided by the test suite. In practice this was remarkably effective - the result is a working Dart library that passes the full conformance test suite; where every implemented feature is traceable to the test spec, and in turn to the feature spec. Compared to every other library we have, the Dart library has greater test coverage, a faster and more reliable test suite, and superior traceability.
This now sets a template for how other new feature development is undertaken. We are using this test-driven approach to development of a range of other new SDK features, including the AI Transport SDK.
Conclusion
This is a case where AI-powered development is able to deliver orders of magnitude improvement in velocity, together with improved quality, compared with the pre-AI approach. It's not that the quality and completeness weren't possible before; but the discipline and effort needed to do the right thing in every detail are rarely achieved in practice. This doesn't mean that humans don't have a role; it's quite the opposite. We have human input where it is most valuable: formulating ergonomic, intuitive and idiomatic APIs, and making the key design decisions in the structure of the code. What they no longer have to do is the part that LLMs can now do better, when humans are working with the reality of a constrained attention budget; doing systematic, thorough, but largely mechanical translation of the detail in the specification to the detail in the corresponding code.


