

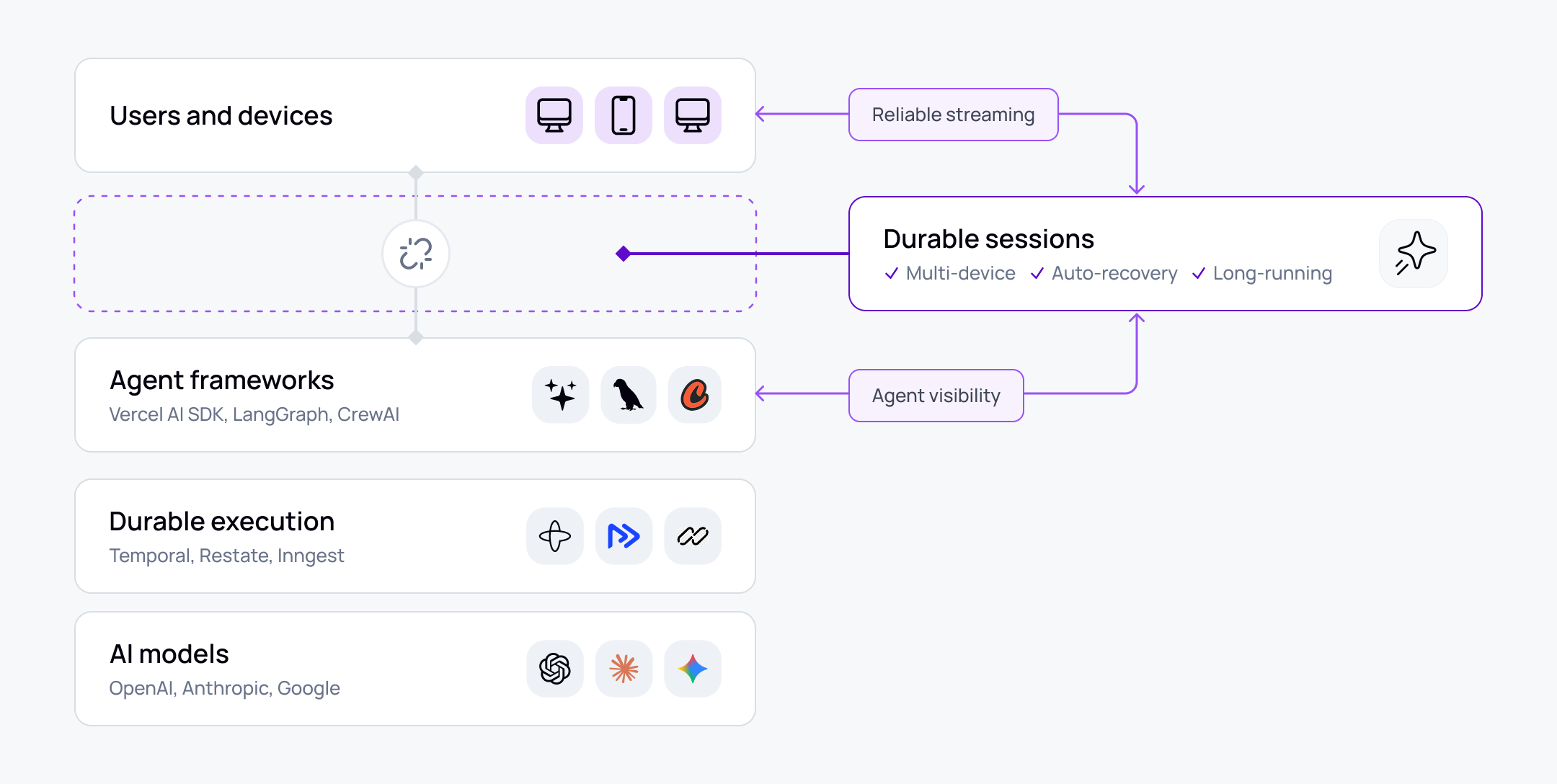
Every major layer of the AI stack now has a name. Model providers - OpenAI, Anthropic, Google - handle inference. Agent frameworks - Vercel AI SDK, LangGraph, CrewAI - handle orchestration. Durable execution platforms like Temporal make backend workflows crash-proof.
Between the agent and the user's device, there is nothing comparable. The stateful connection through which the agent and user actually interact - the session itself - has no dedicated layer, no recognised category, and no purpose-built tooling. Teams build on the protocols available: HTTP streaming, SSE. These work in demos. But they break at the boundary between a well-designed backend and real production conditions - and no framework, no model provider, and no execution engine has taken ownership of what happens there.
Having spoken to over 40 leading AI companies at the forefront of building these applications - and reviewed hundreds of developer reports across different SDK communities - there's a clear pattern: there is a transport gap, and the teams pushing hardest are the ones suffering most from it.
Why HTTP streaming can't fill it
HTTP streaming and SSE are a natural evolution given most web servers are HTTP-based. For the first generation of AI applications - user sends a prompt, model streams back a response, interaction complete - they work well. Stateless, short-lived, one direction.
The problem is fundamental. HTTP streaming couples the connection, the device, and the server to a single request. Any timeout, any network drop on either side, and the session is gone. There is no mechanism to resume from where you left off. There is no way for the client to send a signal while the server is streaming - no interrupt, no redirect, no heartbeat. The protocol was designed for document retrieval, not for stateful, bidirectional, long-running sessions.
Agentic AI applications need all of those things. Sessions run for minutes or hours. Agents make tool calls mid-conversation. Users expect to switch devices. Humans need to take over from agents. These interactions assume a persistent, bidirectional session - and HTTP streaming provides none of that. These aren't implementation weaknesses a team can engineer around. They are properties of the protocol.
The five gaps
The five problems below all originate in the same place: the absent session layer. Each one is a failure mode that shows up in production and traces back to the transport.
The workaround architecture – and where it fails
Teams don't stay blocked. They build their way around the gaps - and the architecture they converge on is strikingly consistent.
Message buffers to handle token replay across reconnects. Background workers to decouple generation from delivery. Custom state serialisation for device transitions and session restore. The general approach is to take what's available - HTTP streaming, a data store, a message queue - and assemble it into something that approximates a session layer.
The problem is that building state management for streaming architectures is not straightforward. These are systems designed to be stateless, now forced to maintain state across connections, devices, and participants. Teams add deduplication logic because message replays can produce duplicates. They add sequencing because multiple backend services writing to the same buffer create ordering problems. They add their own presence model because there's no signal for whether a client is connected, slow, or gone. Each patch introduces new edge cases, and the surface area grows faster than the team's ability to test it.
From speaking to over 40 leading AI companies, they're all building some kind of custom state management around this. Intercom had their own pub/sub layer that worked well until the requirements outgrew it. HubSpot built a dedicated token batching layer to manage delivery cost. These are experienced teams making rational decisions given what the stack provides. They each independently discovered the same constraints and built their way to the same workarounds. That convergence is the clearest evidence that the problem is structural. The workaround architecture does not solve the session layer problem - it is the session layer problem, assembled from parts not designed for it.
What the ecosystem has concluded
The framework vendors have made their positions clear. Vercel built a pluggable ChatTransport interface and told developers to bring their own transport. CrewAI closed a WebSocket feature request - complete with a detailed proposal and an offer to contribute the pull request - as "not planned." Temporal's maintainers have said there is currently no built-in way to notify frontends of state changes.
These are deliberate boundaries, not oversights. The session layer sits between every named part of the stack, and none of them have claimed it as their problem to solve.
The emerging name for this layer is durable sessions - a persistent, addressable session between agents and users that outlives any single connection, device, or participant. Several vendors are building pieces of it, including ourselves at Ably. ElectricSQL published a reference implementation for stream resilience. Upstash has positioned Redis Streams as a resumable streaming workaround. Vercel's durable-agent initiative acknowledges the framework layer alone isn't sufficient. Companies like ElectricSQL and EMQX in the MQTT space have been using the term "durable sessions" for a while - it's just becoming far more relevant now as AI applications hit the walls described in this article. Nobody yet provides the full layer across reliable streaming, multi-device continuity, agent visibility, and human-AI coordination.
What changes when teams solve it
The problems described in this article aren't theoretical. Neither are the outcomes when teams address the transport layer as a first-class architectural concern.
Intercom built Fin, one of the most sophisticated AI customer support agents in the market, on a capable internal pub/sub system. As Fin's capabilities grew - streaming responses, multi-step workflows, agent-to-human handoffs - the requirements outgrew what that system was designed for. After adopting Ably AI Transport as their purpose-built session layer, they saw faster first-token delivery, more reliable streaming across their network, and freed up engineering time that had been going to transport maintenance. Their teams are now working on higher-value problems instead of maintaining session infrastructure.
HubSpot's AI copilots needed to share state between agents and across devices - something their HTTP-based transport couldn't support. They'd also built a dedicated token batching layer to manage delivery cost. With a session layer handling transport, batching, and state sharing, those custom layers became unnecessary. Their copilots now share state natively, and the batching problem that required dedicated engineering is handled at the infrastructure level.
These aren't rescue operations. They're the natural outcome of treating the session layer as infrastructure rather than application code - the same shift that happened when everyone adopted CDNs and realised it was insane to serve static content themselves, or when Temporal made durable execution something you adopt rather than build.
What this means for engineering teams evaluating their stack
You're pre-launch or early in production. The user experience problems described here probably aren't your concern yet - you're focused on the intelligence, on delivering meaningful results. That's the right focus. The architectural decision worth making early is to avoid coupling your delivery directly to HTTP streaming, so that reconnection, multi-device, and handover become extension points rather than rewrites when the time comes.
You've shipped and you're seeing fragility. Your team is starting to spend time on how to handle refreshes, reloads, connection drops, tab changes. You're building workarounds for what seem like basic requirements but aren't. The signal: engineering time that should be going to product features is going to transport reliability instead. This is the point where the investment in fixing these problems yourself is no longer worth it - drop-in session layers exist now that solve all of this out of the box. Once you start seeing the signs, that's the inflection point.
You're operating at scale. The gaps become user experience constraints. You're limited by what you can do with your current transport. Things like copilots sharing state, showing agent presence, supporting interruption and barge-in become difficult to implement. You don't have observability over sessions or auditability for compliance. Supporting multiple devices or offline modes where you notify users requires more engineering. And this all matters because you've nailed the AI part - but now you're focused on the experience of AI, and the transport layer is getting in the way of delivering a great intelligent experience, not just great intelligence.
The layer worth naming
The way to think about it: durable execution makes the backend crash-proof. Durable sessions make the user experience crash-proof. They sit on opposite sides of the agent and complement each other.
Ably AI Transport was built to fill the session layer. It handles stream resumption, multi-device session continuity, agent presence, and human takeover - the same infrastructure that companies like Intercom, HubSpot, Suno, and Duolingo are running in production. It sits between your agent framework and your users, with no opinion on your orchestration logic or your model. If the gap described in this article looks familiar, the docs are a reasonable next read: ably.com/docs/ai-transport.


