Resilience in action: zero service disruption
During this week’s AWS us-east-1 outage, Ably maintained full service continuity with no customer impact. This was our multi-region architecture working exactly as designed; error rates were negligibly low and unchanged throughout. Any additional round trip latency was limited to 12ms, which is below the typical variance in any client-to-endpoint connection, and well below our 40–50ms global median; this is imperceptible to users and below monitoring thresholds. There were no user reports of issues. Taken together this means there was zero service disruption.
The technical sequence
Ably provides a globally-distributed system hosted on AWS with services provisioned in multiple regions globally. Each scales independently in response to the level of traffic in the regions, and us-east-1 is normally the busiest region.
From the onset of the AWS incident what we saw was that the infrastructure already existing in that region continued to provide error-free service. However, issues with various ancillary AWS services meant that our control plane in the region was disrupted, and it was clear that we would not be able to add capacity in the region as traffic levels increased during the day.
As a result, at around 1200 UTC we made DNS changes so that new connections were not routed to us-east-1; traffic that would have ordinarily been routed there (based on latency) were instead handled in us-east-2. This is a routine intervention that we make in response to disruption in a region. Pre-existing connections in us-east-1 remained untouched, continuing to serve traffic without errors and with normal latency throughout the incident. Our monitoring systems, via connections established before the failover, confirmed this directly.
Latency impact: negligible
We continuously test real-world performance in multiple ways. Monitors operated by Ably, in proximity to regional datacenter endpoints, indicated that the worst case impact on latency - which would have been clients directly adjacent to the us-east-1 datacenter, but which now have to connect to us-east-2 - was 12ms at p50. We also have real browser round-trip latency measurements using Uptrends, which more closely simulate real users, with actual browser instances publishing and receiving messages between various global monitoring locations.
These measurements taken during the incident are shown below; real-world clients experienced even lower latency impact, since from each of the cities tested, there is negligible difference in distance, and latency, between that location and us-east-2 versus us-east-1. Taken across all US cities that are monitoring locations, the measured latency difference averaged 3ms. That actual difference is substantially lower than normal variance in client connection latencies, and is therefore imperceptible to users and well below monitoring thresholds.
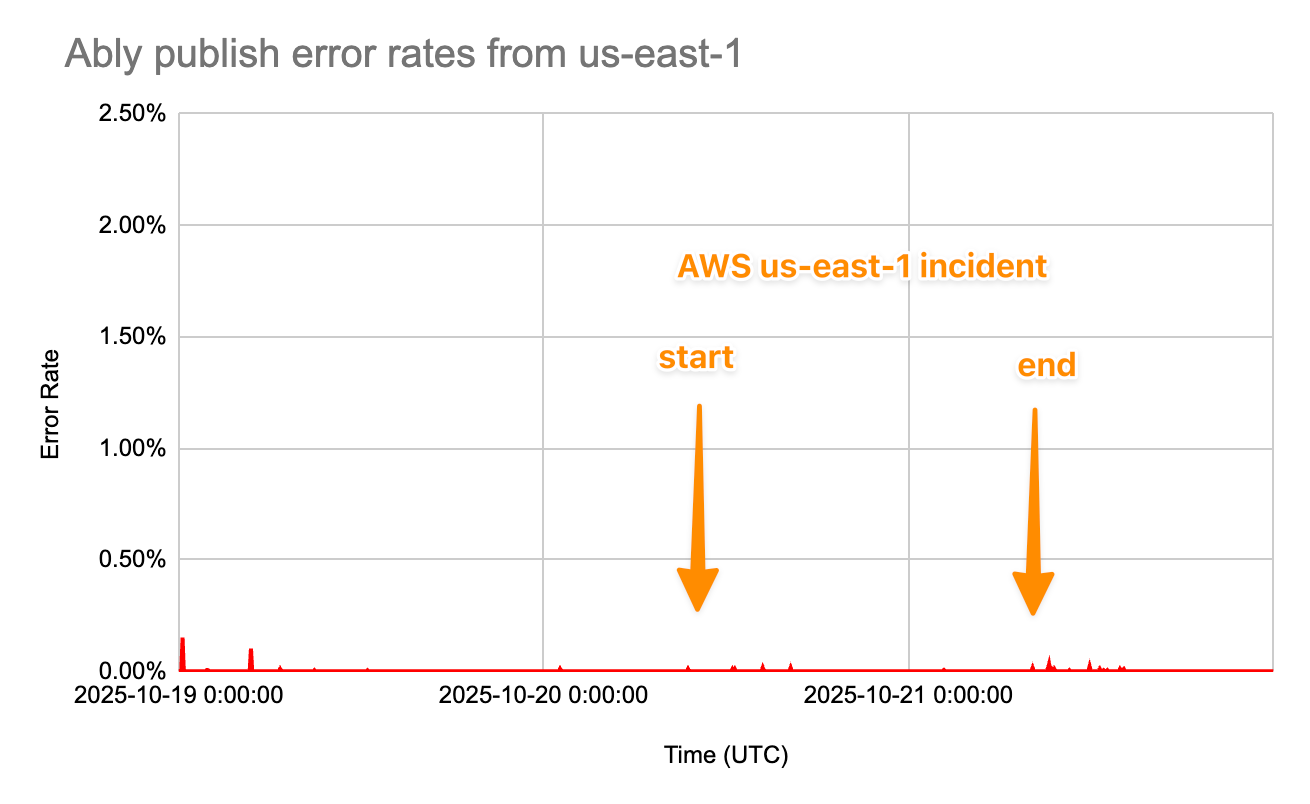

We restored us-east-1 routing on 21 October following validation from AWS and our own internal testing.
The architecture at work
This incident validated our multi-region architecture in production:
- each region operates independently, isolating failures.
- latency-based DNS adapts routing to regional availability.
- existing persistent connections are unaffected if the only change is to the routing of new connections.
- a further layer of defense, not used in this case, provides automatic client-side failover to up to five globally-distributed endpoints.
That final layer matters. Even if us-east-1 infrastructure had failed entirely (it didn’t), client SDKs would have automatically failed over to alternative regions, maintaining connectivity at the cost of increased latency. It didn’t activate this time, since regional operations continued normally, but it’s a core part of our defense-in-depth strategy.
Lessons reinforced
The key takeaways for us from this incident:
- A genuinely distributed system spanning multiple regions, not just availability zones, is essential for ultimate continuity of service;
- Planning for, and drilling, responses to this type of event is critical to ensuring that your resilience is real and not just theoretical;
- A multi-layered approach, with mitigations both in the infrastructure and SDKs, ensures redundancy and continuity even without active intervention. AWS continues to be an outstandingly good global service, but occasional regional failures must be expected. Well-architected systems on AWS infrastructure are capable of supporting the most critical business needs.