

You start a research task on your laptop, the network drops during a meeting, and when you open your phone to continue, the conversation is gone.
You re-prompt, get partial duplicate results, and lose 30 minutes of work. The delivery layer dropped it. That's one of the most consistent problems teams hit when building AI applications.
It's particularly acute in customer support, where a session belongs to the conversation - not to any single device, connection, or participant. An AI agent handles a query, the user switches from desktop to mobile mid-interaction, a human needs to step in. Every one of those transitions is a point where the session can silently break.
Why this breaks
HTTP streaming is stateless. Each connection is independent, tied to a specific device and browser session, so when the user switches devices, refreshes, or loses connectivity, the new device has no position in the stream. It doesn't know which tokens the previous device received, it can't resume mid-response, and it starts over.
There's no shared state across connections. Device B has no visibility into what Device A received, and without session tracking built into the architecture, the server treats each connection as a new actor. A stateless delivery layer wasn't designed for conversations that span sessions, devices, or time.
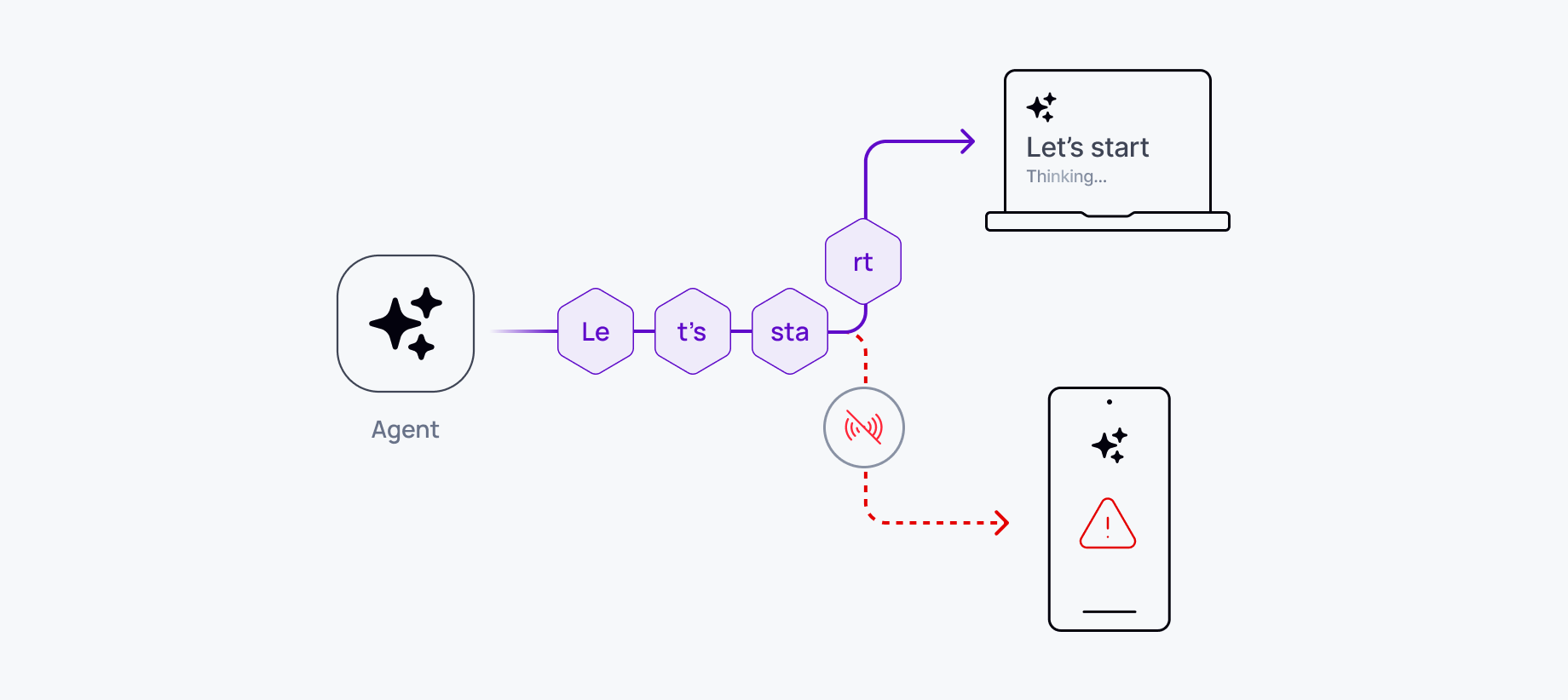
What breaks in production
Teams building multi-device AI experiences without dedicated infrastructure hit the same set of edge cases.
Lost responses. The model finished generating while the user was offline or mid-switch. Nobody saw the output. The compute was wasted.
Duplicate effort. The user doesn't know if the previous session completed, so they re-prompt. You pay for the same response twice.
State conflicts. A new prompt arrives on the phone while the laptop tab still shows an incomplete response. Which version is canonical? The server doesn't know.
Mobile-specific failures. iOS and Android background apps aggressively drop connections. WiFi-to-cellular handoffs are frequent. A conversation that works fine on desktop will fall apart on mobile without explicit reconnection and resume handling.
These failures don't show up in demos. They appear in production, under real network conditions, with real users – and they erode trust quickly because AI conversations often carry context the user spent time building.
What most teams build first
The standard workaround is a Redis buffer between the AI backend and the client. It handles full page reloads reasonably well. It doesn't handle tab switches. It breaks on mobile backgrounding. And it has no path for multi-device delivery – the session state is scoped to one client, not to the user.
Every serious production team discovers this wall independently and ends up engineering some version of the same architecture. Vercel's own lead maintainer acknowledged the gap directly: "to solve this we would need to have a channel to the server that allows transporting that information. WebSockets are one option." That's the right diagnosis. The Redis buffer is an approximation of the real fix.
The architectural shift: state lives in the channel, not the connection
The underlying problem is that session state is coupled to the connection. The fix is decoupling them.
Instead of streaming directly over an HTTP connection, the server publishes messages to a channel. Any device subscribing to that channel receives the same messages. The state is in the channel. The connection is the transport, nothing more.
This is the foundation of what's increasingly called a durable session – a persistent, addressable session between agents and users that outlives any single connection, device, or participant. Durable execution makes the backend crash-proof; durable sessions makes the experience crash-proof. They sit on opposite sides of the agent and complement each other.
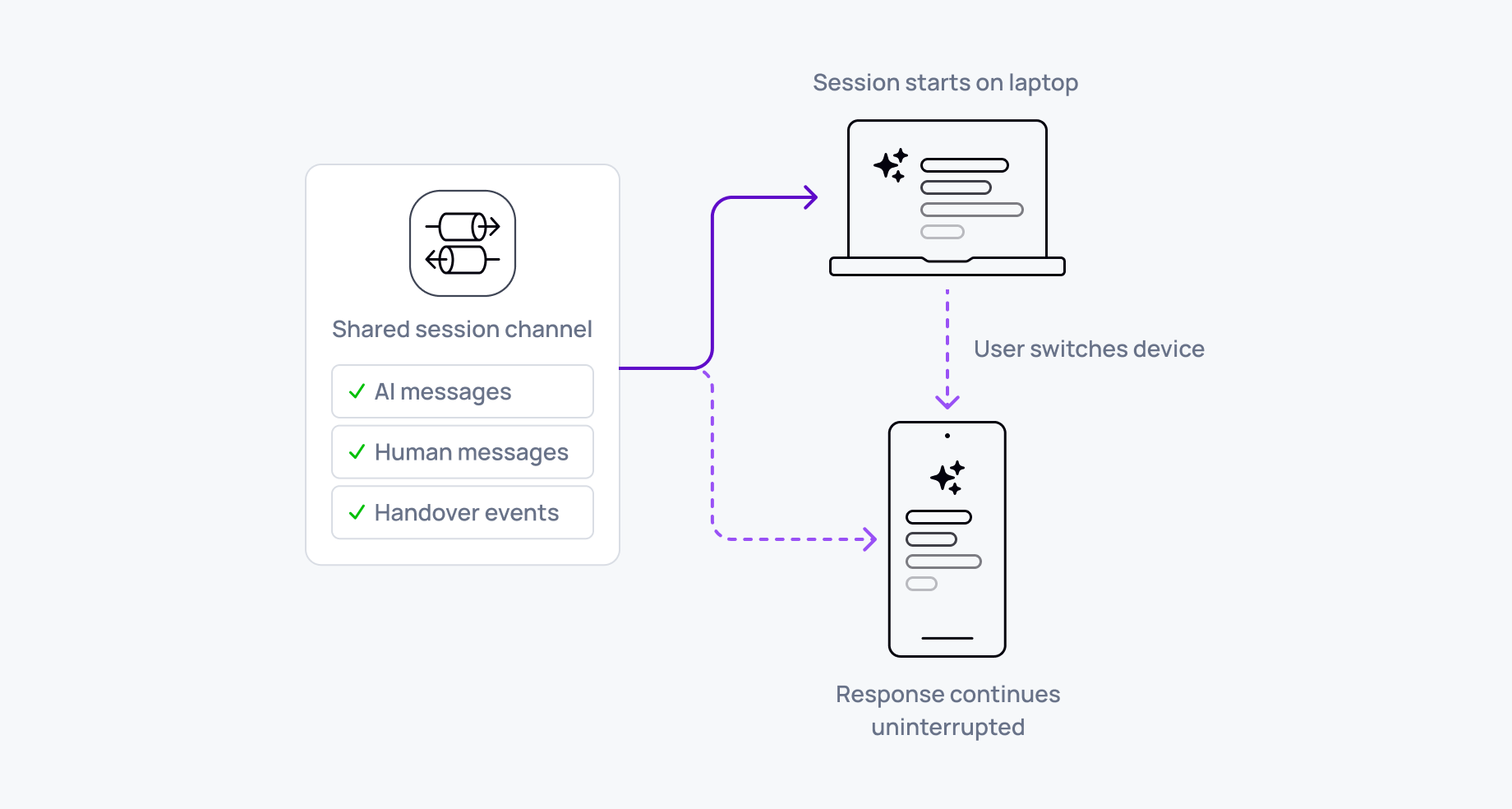
In practice this changes the behavior fundamentally. Any device can join – same browser tab, phone, or tablet. Subscribing to the channel gives that device access to the conversation. Reconnection becomes catch-up rather than restart: channels persist message history, and when a device reconnects, it replays what it missed and transitions to live delivery. From the user's perspective, they pick up where they left off.
Conflicts route through the server. User actions – sending prompts, interrupting, deleting messages – go to the server, which publishes the authoritative result to the channel. All devices receive the same update. There's no client-side state to reconcile.
What the transport layer has to handle
Identity-aware fan-out. The system needs to recognize all active sessions associated with a single user and propagate updates across all of them. When a user sends a message on one device, every other active device should reflect the change immediately. This requires mapping user identity to active connections at the infrastructure level, not the application layer.
Ordering and session recovery. If the connection drops – from a device switch, a network blip, or a page refresh – the user shouldn't lose messages or see them out of sequence. A well-designed transport layer replays missed events and keeps message sequences intact. History loads first, then the live stream resumes. The client doesn't need to manage the transition.
Token stream compaction. Replaying thousands of individual tokens to a reconnecting device is wasteful. A better pattern compacts token streams into complete responses in channel history: one message per AI response, not hundreds of tokens. New devices load the complete response instantly, then receive new tokens for any in-progress generation.
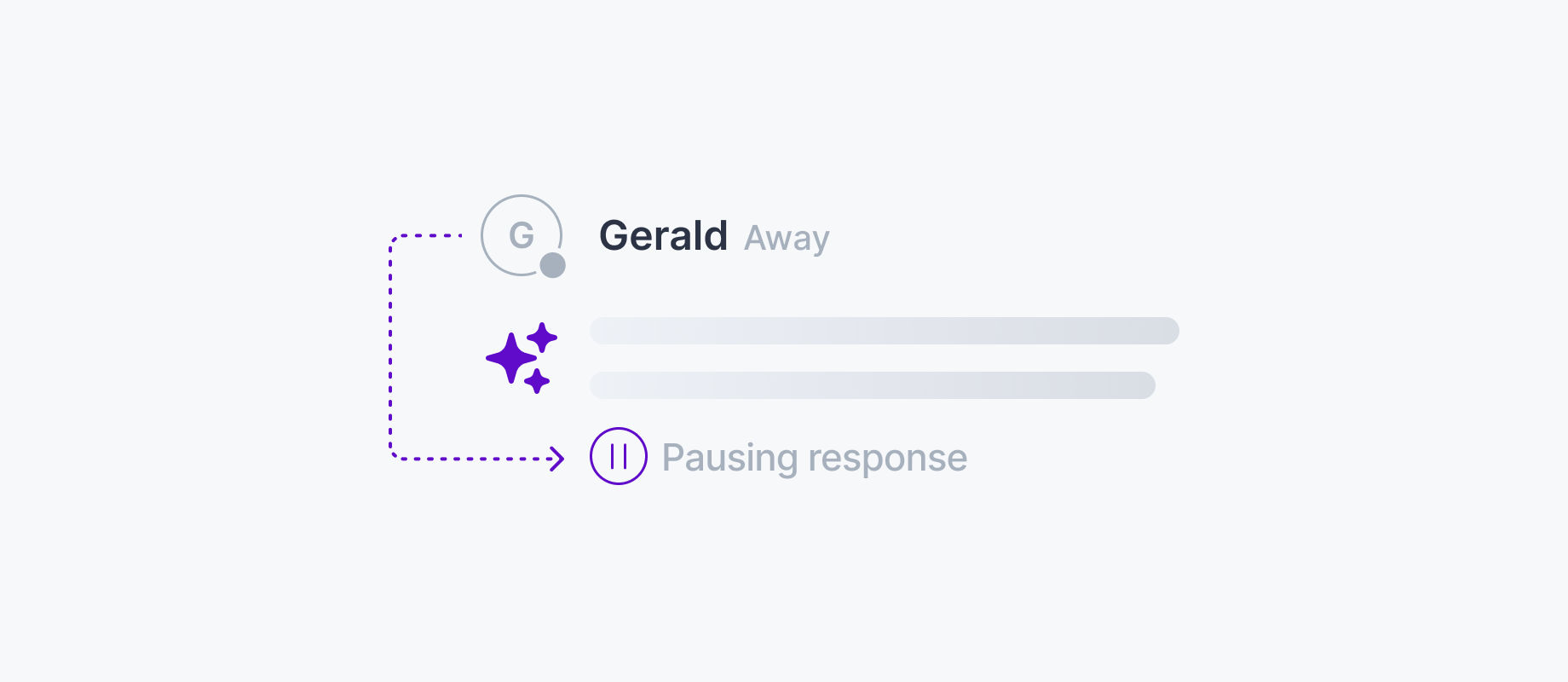
Presence tracking. The backend needs to know which devices are currently active. This matters for more than UX. Should the model keep streaming if the user closed the tab? Should a background task escalate if all devices have disconnected? Presence answers these questions from a live membership set rather than polling or timeout heuristics. Without it, systems rely on assumptions that produce missed interactions, wasted compute, and handoffs that arrive too late.
Presence-aware cost controls. AI agents can quietly generate output that delivers no value but incurs real cost – streaming to an empty room, running tool calls after the user navigates away. Tying agent activity to presence means the infrastructure pauses or deprioritizes automatically when no devices are engaged and resumes when they return. Costs scale with actual usage, not connection count.
Mobile is the hardest case
Mobile devices are the toughest environment for connection continuity.
Network instability is constant – WiFi-to-cellular handoffs, tunnel blackouts, dead zones. Resume capability isn't optional. Apps get backgrounded aggressively, so the model might finish generating while the app is suspended, and when the user returns they should see the completed response, not an empty screen.
Push notifications bridge the gap. When significant events occur while the app is backgrounded – task complete, human takeover required – notifications alert the user and deep-link directly to the conversation. The payload should carry enough context for the app to restore state without a full reload. Push notification infrastructure (FCM, APNs, Web Push) ships as a supported capability; AI-specific end-to-end delivery patterns are still being documented, so implementation details vary by platform.
Battery is also a real constraint. Holding open WebSocket connections when the app is backgrounded drains battery, so intelligent reconnection strategies close connections when backgrounded, reconnect on foreground, and use push notifications to trigger reconnects for important updates.
Gen-1 AI vs Gen-2 AI: the real decision
Not every AI application needs cross-device support. HTTP streaming works well for Gen-1 AI products – a user sends a prompt, the model returns a response, the interaction is complete. Single session, single device, seconds to complete. For that use case, HTTP streaming is the right call.
Gen-2 AI products look structurally different. Sessions last minutes or hours. Agents make tool calls mid-conversation, coordinate with other agents, and run tasks in the background while the user is elsewhere. Humans need to step in – approving actions, taking over from an agent that has reached its limits, handing control back. Users move between devices and expect the conversation to follow them.
The question isn't whether your architecture is complex. It's which generation of product you're building. If sessions outlive a single connection, if users will move between devices, if a human might need to join a running conversation – channel-based architecture is the right call. 32 of 37 vendors evaluated have no multi-device fan-out capability at all, which means most teams building Gen-2 products are either rebuilding this layer from scratch or shipping without it.
What this makes possible
Channel-based sessions change what teams can build. A user starts a complex analysis on their phone during a commute, continues on their laptop at the office, and receives a push notification when the background task completes. In a customer support workflow, an AI agent handles a query, the conversation follows the user from desktop to mobile mid-interaction, and a human operator can step in on any device with full session context intact – then hand control back to the agent when they're done.
Users already expect this from messaging applications. AI conversations are next.
The infrastructure decision is whether to build session synchronization yourself or use systems designed for it. Building it means pub/sub channels, message persistence with configurable retention, client SDKs that handle subscription and history replay, presence tracking, mobile SDKs with background handling, push notification support, and identity-scoped authorization. That's weeks to months of engineering, and the edge cases don't appear until production.
Ably AI Transport implements this model – the docs on channel history and connection state recovery cover what the infrastructure layer needs to handle in detail.


