There’s no shortage of noise in AI right now. New frameworks, protocols, demos, and acronyms appear almost weekly. But when you speak directly to the teams actually shipping AI to users at scale, a different picture emerges.
This is what we've learned over the last few months from speaking to CTOs, AI engineering leads, and product leaders from unicorns, public companies, and fast-growing platforms across industries where humans interact directly with AI.
Matthew O'Riordan shares what Ably learned from conversations with over 40 engineering leaders building AI products.
The AI UX patterns that will decide what gets adopted next
The goal wasn’t to sell anything or validate a roadmap. It was to understand what’s really working, what’s breaking, and which AI UX patterns are quietly becoming non-negotiable.
What we found surprised us.
Many of the things dominating online discussion barely showed up in real systems. Meanwhile, a consistent set of experience problems kept coming up again and again, regardless of industry, model choice, or framework.
This post shares the most important patterns we uncovered, straight from the teams building agentic AI in production.

The short version: key takeaways from the research
Before diving deeper, here are the themes that came up most consistently:
- Only a small group of companies are building Gen-2 AI experiences today, but they carry most of the volume.
- The hardest problems aren’t model-related, they’re experiential. The model can be “good enough,” but the experience breaks under real user behaviour.
- There is no standard for agent-to-client communication. Nearly everyone ends up building their own delivery layer.
- Frameworks help teams get started, then teams diverge. As products mature, orchestration and delivery increasingly become in-house concerns.
- Progress visibility, interruption, and continuity are no longer “nice to have.” Users tolerate latency if they understand what’s happening. They don’t tolerate silence, resets, or lost context.
- Failure is the norm, not the edge case. Partial streams, retries, and mid-response failures happen daily at scale.
- Cost optimisation and presence awareness are rising fast. Teams are actively rethinking when, how fast, and at what priority AI work should run.
Gen-2 AI is still early, but it’s where the real volume is
Most companies are still shipping Gen-1 AI experiences (a prompt goes in, a response comes back). It’s fast, synchronous, and relatively easy to reason about.
But the teams pushing hardest on AI, the ones with meaningful traffic and real users, have already moved beyond that. They’re building assistants, copilots, and agents that run longer, call tools, work asynchronously, and interact with users over time.
While this group represents a minority of companies, it accounts for a disproportionate share of usage volume. These teams care deeply about UX breakdowns because small failures get amplified at scale.
The “wild west” of agent-to-client communication
Despite rapid progress in models and tooling, one thing stood out: there still isn’t a widely adopted standard for how agents communicate with users.
We expected to see convergence around emerging protocols or patterns. Instead, nearly every team described some version of the same journey:
- Start with simple HTTP request/response.
- Add streaming.
- Add custom UI logic.
- Add retries, buffering, and recovery.
- Realise the experience is now bespoke and fragile.
Even teams using popular frameworks often diverged over time. Frameworks help early, but eventually teams hit constraints around flexibility, UX control, or scale. At that point, orchestration and delivery logic become part of what differentiates the product, and something they want to own.
The AI UX patterns that actually matter
Across conversations, the same experience patterns kept surfacing.
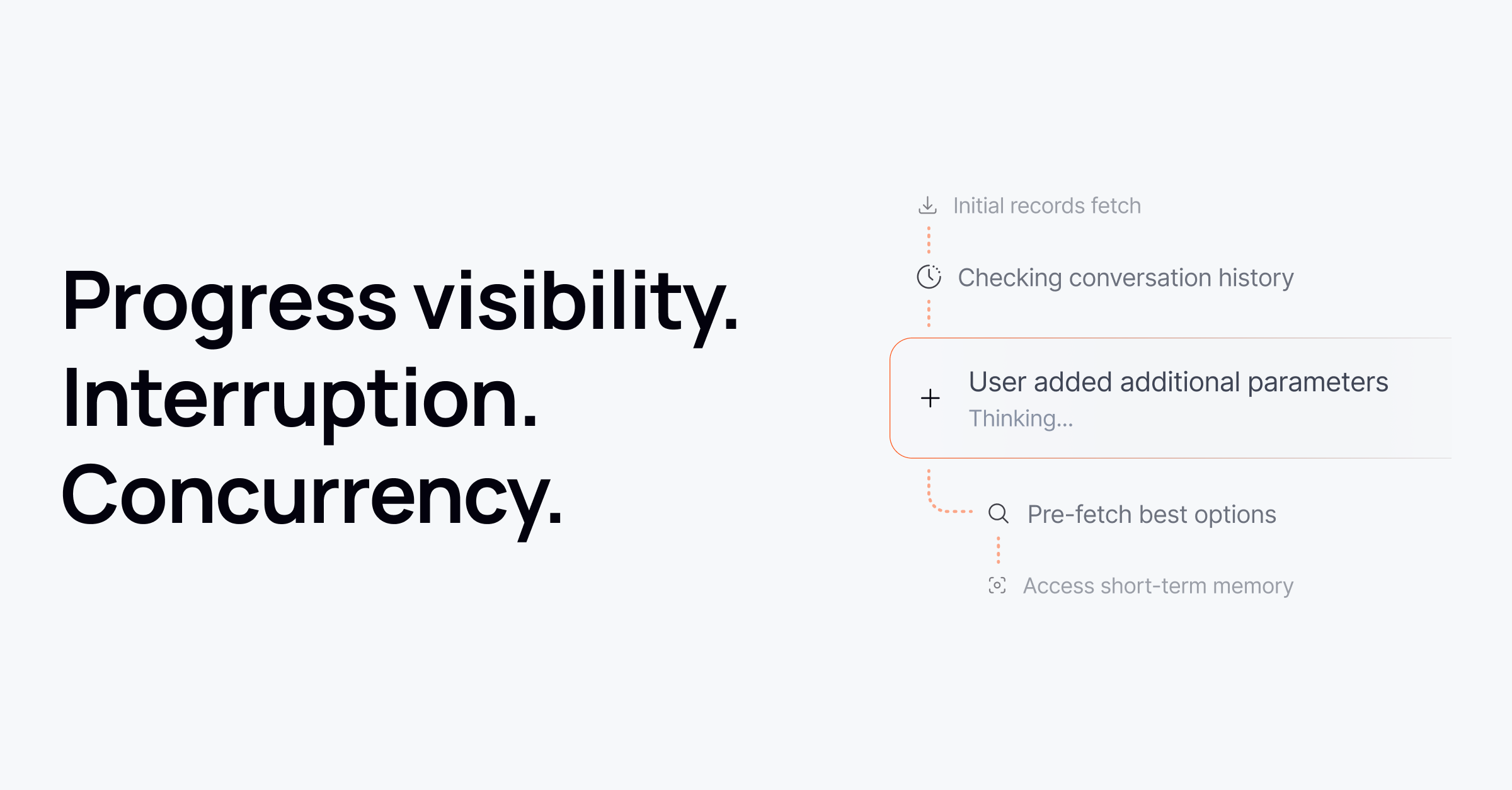
Progress visibility isn’t optional
Users are willing to wait, but only if they know what’s happening. Silent latency kills trust.
Some teams have invested heavily in making progress feel meaningful, not just adding a spinner. Others layer lightweight systems on top of heavier models purely to surface “what the system is doing” signals.
The consensus was clear: if users don’t see progress, they assume the system is broken.
Interruption and steering are critical
As soon as AI tasks become asynchronous, interruption becomes essential.
Users notice when an agent is heading in the wrong direction or missing context, and they expect to correct it immediately. Waiting for a long response to finish before restarting isn’t acceptable.
This introduces real complexity: stopping work safely, rerouting tasks, or resuming with new context mid-flight. But teams consistently said it was worth it, because it changes how usable the system feels.
Continuity across sessions and devices is assumed
People switch tabs. They lose connectivity. They come back later on another device.
When that happens, restarting the conversation feels broken even if the model is performing well. The expectation is continuity: the AI should still be there, aware of what it was doing and ready to continue.
This matters even more for long-running tasks and background work, where users might step away entirely and expect results to appear when they return.
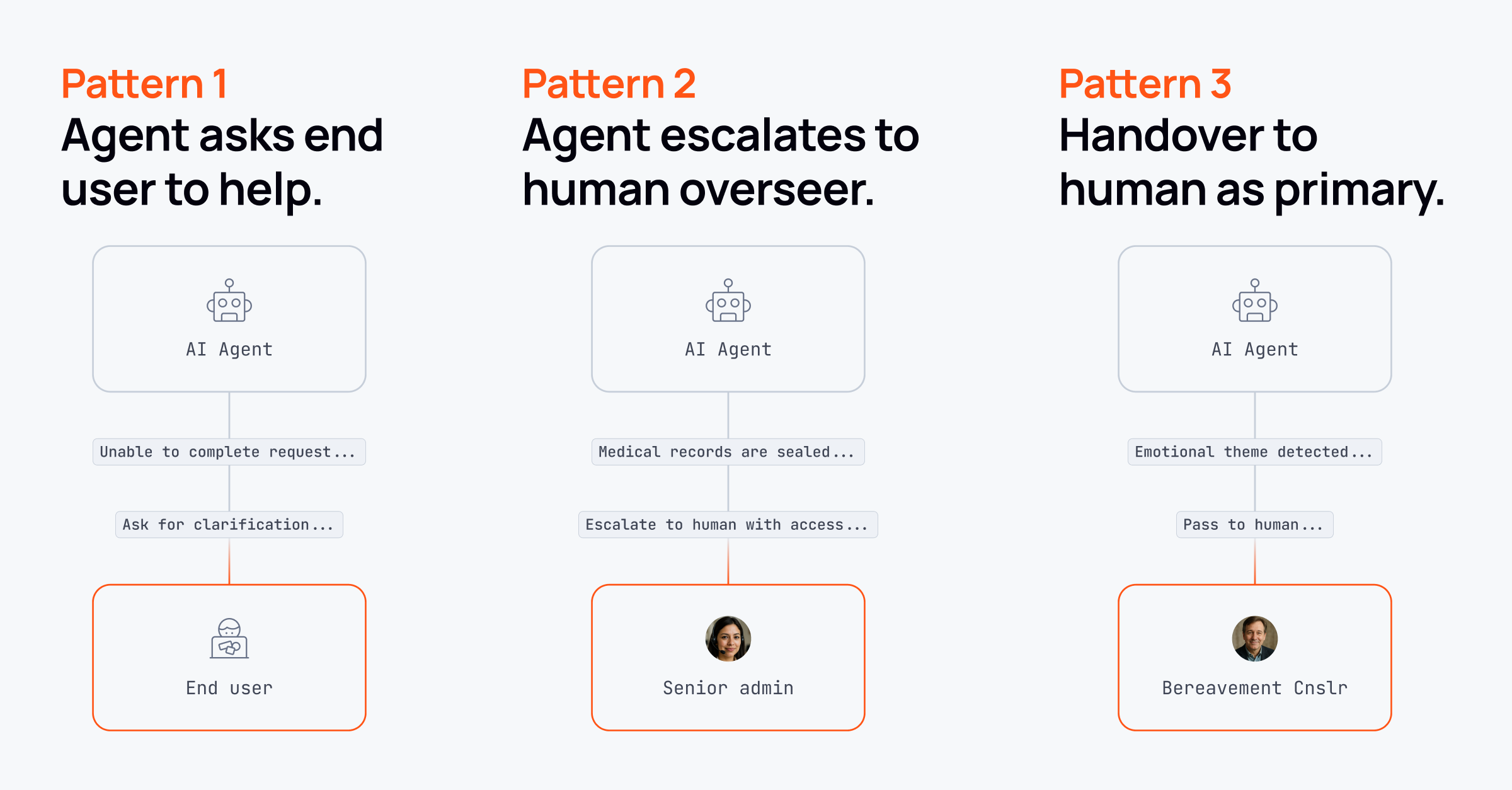
Concurrency, humans-in-the-loop, and coordination
Some of the most interesting findings came from customer support and CX-focused teams.
They described situations where users ask multiple things at once, or shift topics mid-task. That creates hard coordination problems:
- Do you pause one task and start another?
- Do you run multiple agents concurrently?
- How do those agents stay coordinated and avoid conflicting outputs?
Human handoff introduced similar challenges. Many teams still rely on separate chat systems for humans, leading to awkward context transfers and fragmented experiences. Teams that unify communication between agents and humans report far smoother transitions.

Failure is constant, and often partial
At scale, failures aren’t rare, they’re expected.
Streams stop halfway through. Responses stall. One provider fails while another succeeds. The hardest UX problems aren’t binary failures, but partial ones.
What do you show the user when half a response has already streamed? How do you retry without creating duplicates or a jarring reset?
Teams are experimenting with retries, parallel calls, and durable workflows, but most described this as ongoing work rather than something you “solve once.”
Cost awareness and presence are becoming first-class concerns
Cost came up in almost every conversation.
Tokens are expensive. Small prompt changes can dramatically alter spend. And many teams are now asking a simple question: if the user isn’t here, why are we running expensive work at full speed?
Presence awareness, knowing whether a user is active, idle, or offline, is starting to shape how teams prioritise, batch, or slow down processing. This wasn’t framed as optimisation for its own sake, but as necessary discipline as AI usage scales.
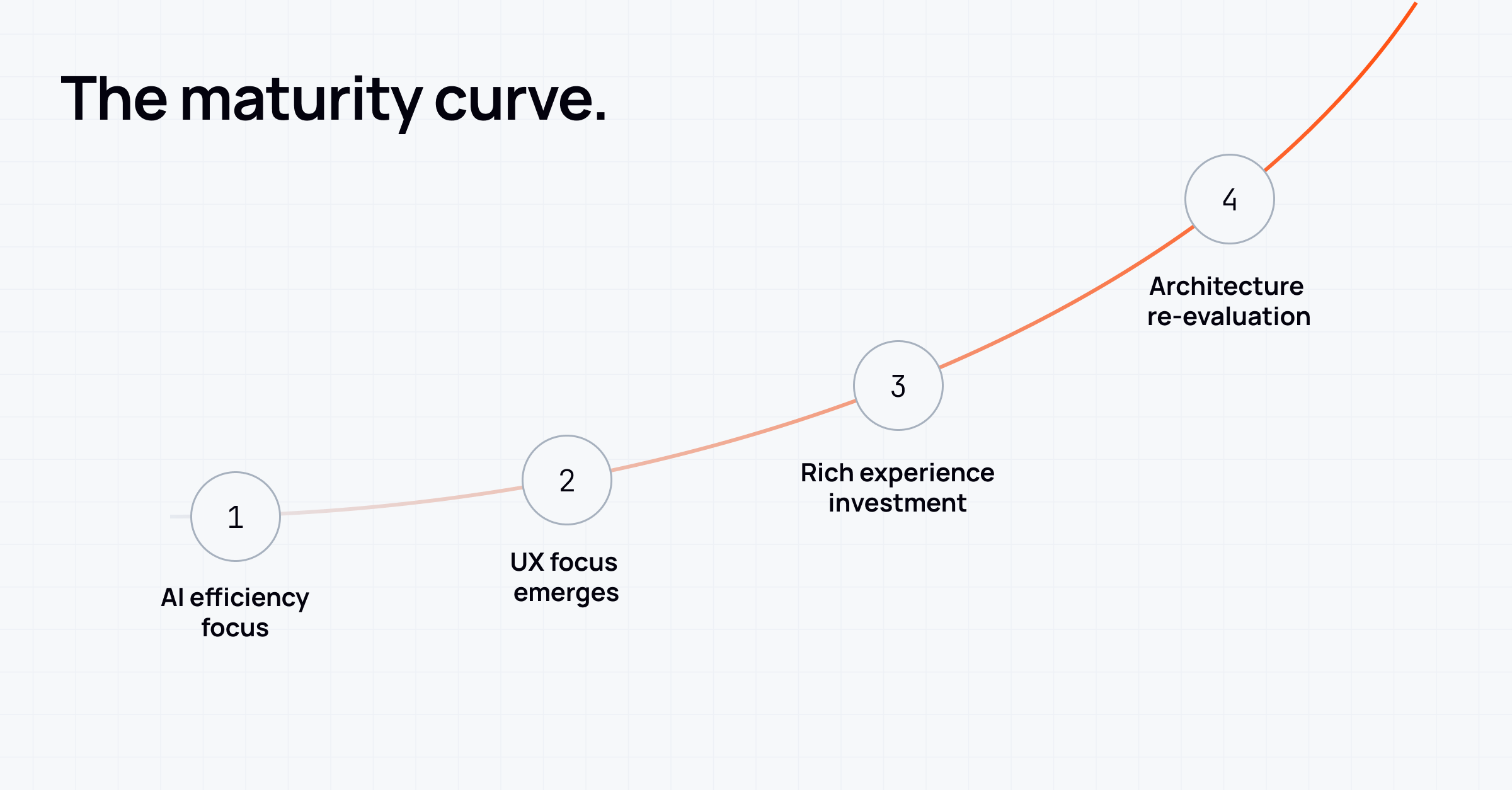
A maturity curve is emerging
Across industries, we saw the same progression:
- Add AI to prove intelligence.
- Improve UX so people can interact with it.
- Scale and orchestrate as usage grows.
- Re-architect when the original delivery approach becomes the bottleneck.
None of these problems are impossible in isolation. But together they quickly become overwhelming, and distract teams from improving the intelligence itself.
That, more than anything, was the underlying theme: teams want to spend time making AI smarter and more useful, not rebuilding the same delivery and UX foundations over and over again.
Final thought
The future of agentic AI won’t be decided by who has the best model. It will be decided by who delivers experiences that feel continuous, controllable, and trustworthy under real-world conditions.
That’s where adoption happens. And it’s where most of the hard work still lives.
To understand more about how Ably brings realtime continuity and control to your AI agents without rebuilding your whole stack, discover AI Transport here.