# Token streaming
Token streaming allows progressively streaming the tokens that are generated by LLMs to clients in realtime, as the response is being generated.
The Ably channel delivers each individual token to clients subscribed in realtime and automatically compacts the tokens into full LLM responses so clients do not have to re-stream the entire conversation token-by-token when they reconnect, refresh, or load history.
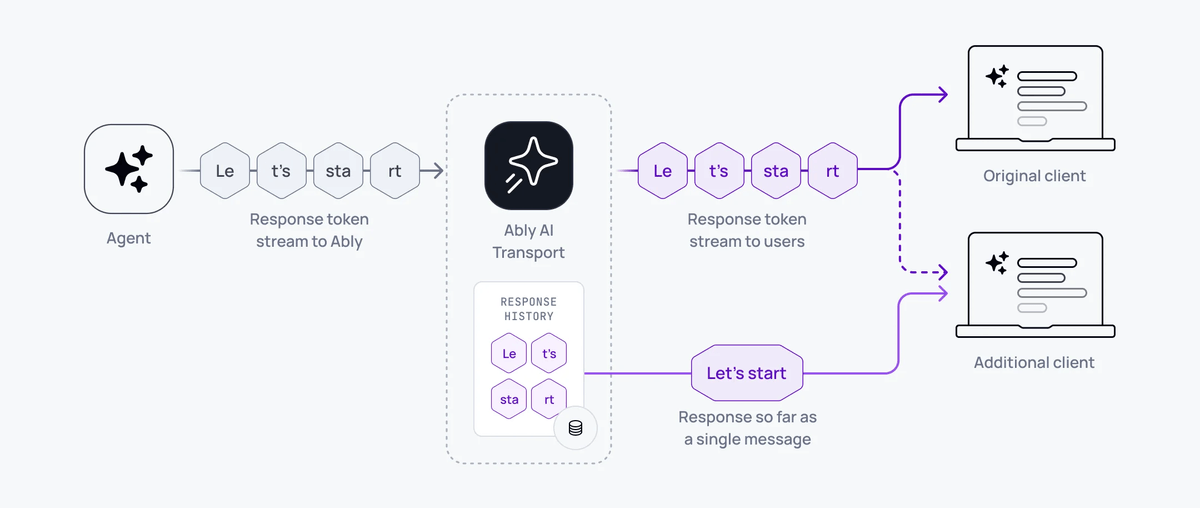
## How it works
Token streaming allows clients to receive and consume tokens as they are generated by the LLM, but also allows clients to consume the full responses as a single coherent message when not subscribing in realtime. For example, when looking at history, refreshing the client, or returning to a conversation.
A key feature of AI Transport's transport layer is that it understands the relationship between responses and their individual tokens. By doing this, the service can support clients that resume an interrupted connection, or those that refresh, during a streamed response. AI Transport supports token streaming by enabling agents to form responses incrementally by appending each token to the content of a single message. Each appended token can be received immediately by a subscriber consuming in realtime. Clients that are not connected in realtime do not need to consume each individual token in order to rebuild the response, these clients can consume the entire response up to the last appended token as a single message.
Using the AI Transport SDK on the server with Vercel's AI SDK, a single call streams the entire response:
### Javascript
```
const { reason } = await turn.streamResponse(result.toUIMessageStream())
```
That single line reads the LLM stream, encodes tokens through the codec, publishes messages to the Ably channel, handles abort signals, and returns when the stream completes or is cancelled.
On the client, the view updates as tokens arrive:
### Javascript
```
const { nodes } = useView(transport)
// nodes contains messages with streaming text that updates in real time
```
## Stream lifecycle
Each streamed response goes through three states:
- `streaming` - tokens are being appended. The message grows as tokens arrive.
- `finished` - the stream completed normally. The message is final.
- `aborted` - the stream was cancelled or errored. The partial message is preserved.
The stream status is tracked in the message header (`x-ably-status`). Clients can check whether a message is still streaming or complete.
## Implement token streaming
### Server
The server creates a turn, invokes the LLM, and streams the response:
#### Javascript
```
import { createServerTransport } from '@ably/ai-transport/vercel'
const transport = createServerTransport({ channel })
const turn = transport.newTurn({ turnId, clientId })
await turn.start()
await turn.addMessages(messages, { clientId })
const result = streamText({
model: anthropic('claude-sonnet-4-20250514'),
messages: conversationHistory,
abortSignal: turn.abortSignal,
})
const { reason } = await turn.streamResponse(result.toUIMessageStream())
await turn.end(reason)
```
`streamResponse` accepts any `ReadableStream`. For Vercel AI SDK, `result.toUIMessageStream()` provides the right format. For other frameworks, produce a `ReadableStream` of your codec's event type.
### Client
With Vercel's `useChat`:
#### Javascript
```
const transport = useClientTransport({ channel, codec: UIMessageCodec, clientId })
const chatTransport = useChatTransport(transport)
const { messages } = useChat({ transport: chatTransport })
```
With generic hooks:
#### Javascript
```
const { nodes } = useView(transport)
// Each node.message contains the streamed content, updating in real time
```
## Under the hood
The codec converts domain events to Ably operations:
- Start - creates a new Ably message on the channel.
- Append - appends content to the existing message (Ably message append operation).
- Close - updates the message with a terminal status (finished/aborted).
If an append fails, for example due to a transient network issue, the encoder falls back to a full message update operation to recover. This ensures the accumulated response is never lost.
## Append rollup
LLM token streaming introduces high-rate traffic patterns, with some models outputting upwards of 150 distinct token events per second. AI Transport automatically manages this by rolling up multiple appends into a single published message, preventing a single response stream from reaching the [message rate limit](https://ably.com/docs/platform/pricing/limits.md#connection) for a connection.
1. Your agent streams tokens to the channel at the model's output rate.
2. Ably publishes the first token immediately, then automatically rolls up subsequent tokens on receipt.
3. Clients receive the same content, delivered in fewer discrete messages.
By default, Ably delivers a single response stream at 25 messages per second or the model output rate, whichever is lower. Ably charges for the number of published messages, not for the number of streamed tokens.
### Configure rollup behaviour
Ably concatenates all appends for a single response that are received during the rollup window into one published message. Set the rollup window for a connection using the `appendRollupWindow` [transport parameter](https://ably.com/docs/api/realtime-sdk.md#client-options):
| `appendRollupWindow` | Maximum message rate for a single response |
|---|---|
| 0ms | Model output rate |
| 20ms | 50 messages/s |
| 40ms *(default)* | 25 messages/s |
| 100ms | 10 messages/s |
| 500ms *(max)* | 2 messages/s |
#### Javascript
```
const ably = new Ably.Realtime(
{
key: 'your-api-key',
transportParams: { appendRollupWindow: 100 }
}
);
```
## Related features
- [Cancellation](https://ably.com/docs/ai-transport/features/cancellation.md) - stop a stream mid-response.
- [Reconnection and recovery](https://ably.com/docs/ai-transport/features/reconnection-and-recovery.md) - resume streams after disconnection.
- [History and replay](https://ably.com/docs/ai-transport/features/history.md) - load past streamed responses from channel history.
- [Chain of thought](https://ably.com/docs/ai-transport/features/chain-of-thought.md) - stream reasoning alongside text.
- [Server transport API](https://ably.com/docs/ai-transport/api-reference/server-transport.md) - reference for `streamResponse` and other server methods.
- [Transport architecture](https://ably.com/docs/ai-transport/how-it-works/transport.md) - how the transport layer encodes and delivers tokens.
- [Get started](https://ably.com/docs/ai-transport/getting-started/vercel-ai-sdk.md) - build your first AI Transport application.
## Related Topics
- [Cancellation](https://ably.com/docs/ai-transport/features/cancellation.md): Cancel AI responses mid-stream with Ably AI Transport. Scoped cancel signals, server-side authorization, and graceful abort handling.
- [Reconnection and recovery](https://ably.com/docs/ai-transport/features/reconnection-and-recovery.md): AI Transport streams survive connection drops automatically. Clients reconnect and resume from where they left off with no lost tokens.
- [Multi-device sessions](https://ably.com/docs/ai-transport/features/multi-device.md): Share AI conversations across tabs, phones, and laptops with Ably AI Transport. All devices see the same session in real time.
- [History and replay](https://ably.com/docs/ai-transport/features/history.md): Load conversation history from Ably channels with AI Transport. Paginated history, gapless continuity, and scroll-back patterns.
- [Conversation branching](https://ably.com/docs/ai-transport/features/branching.md): Branch conversations with edit and regenerate in Ably AI Transport. Navigate sibling branches and maintain full conversation history.
- [Interruption and barge-in](https://ably.com/docs/ai-transport/features/interruption.md): Let users interrupt AI agents mid-stream with Ably AI Transport. Cancel-then-send and send-alongside patterns for responsive AI interactions.
- [Concurrent turns](https://ably.com/docs/ai-transport/features/concurrent-turns.md): Run multiple AI turns simultaneously with Ably AI Transport. Independent streams, scoped cancellation, and multi-agent support.
- [Edit and regenerate](https://ably.com/docs/ai-transport/features/edit-and-regenerate.md): Edit user messages and regenerate AI responses with Ably AI Transport. Fork conversations and navigate between branches.
- [Tool calling](https://ably.com/docs/ai-transport/features/tool-calling.md): Stream tool invocations and results through Ably AI Transport. Server-executed and client-executed tools with persistent state.
- [Human-in-the-loop](https://ably.com/docs/ai-transport/features/human-in-the-loop.md): Add human approval gates to AI agent workflows with Ably AI Transport. Approve tool executions and provide input across devices.
- [Optimistic updates](https://ably.com/docs/ai-transport/features/optimistic-updates.md): User messages appear instantly in Ably AI Transport. Optimistic insertion with automatic reconciliation when the server confirms.
- [Agent presence](https://ably.com/docs/ai-transport/features/agent-presence.md): Show agent status in your AI application with Ably Presence. Display streaming, thinking, idle, and offline states in real time.
- [Push notifications](https://ably.com/docs/ai-transport/features/push-notifications.md): Notify users when AI agents complete background tasks with Ably Push Notifications. Reach users even when they're offline.
- [Chain of thought](https://ably.com/docs/ai-transport/features/chain-of-thought.md): Stream reasoning and thinking content alongside responses with Ably AI Transport. Display chain-of-thought in real time.
- [Double texting](https://ably.com/docs/ai-transport/features/double-texting.md): Handle users sending multiple messages while the AI is streaming with Ably AI Transport. Queue or run messages concurrently.
## Documentation Index
To discover additional Ably documentation:
1. Fetch [llms.txt](https://ably.com/llms.txt) for the canonical list of available pages.
2. Identify relevant URLs from that index.
3. Fetch target pages as needed.
Avoid using assumed or outdated documentation paths.