The fallacies of distributed computing are a list of 8 statements describing false assumptions that architects and developers involved with distributed systems might make (but should undoubtedly steer away from). In this blog post, we’ll look at what these fallacies are, how they came to be, and how to navigate them in order to engineer dependable distributed systems.
What are the fallacies of distributed computing?
Building distributed systems you know you can rely on is no easy feat. Even a "simple" system that only consists of a couple of nodes still comes with complexity. Those nodes have to communicate over a network. However, one of them can fail, or the network itself can become unavailable, or experience high latency.
When designing our distributed system, it's essential to bear in mind that we can't assume everything will always go according to plan. We must be aware that there are constraints and obstacles we will need to overcome.
To better understand the challenges that come with engineering dependable distributed systems, we must refer to the fallacies of distributed computing — a list of false assumptions architects and developers might make. Here they are:
- The network is reliable.
- Latency is zero.
- Bandwidth is infinite.
- The network is secure.
- Topology doesn't change.
- There is one administrator.
- Transport cost is zero.
- The network is homogeneous.
The exact origin of the fallacies is a bit confusing. L. Peter Deutsch, a Sun Microsystems employee at the time, is often credited with drafting the 7 fallacies in 1994. However, some voices say otherwise:
"The eight fallacies as we know them today actually started off as just four fallacies. The first four fallacies were created in the early 90's (sometime after 1991) by two Sun Microsystems engineers, Bill Joy and Dave Lyon.
James Gosling, who was a fellow at Sun Microsystems at the time — and would later go on to create the Java programming language — classified these first four fallacies as 'The Fallacies of Networked Computing'. A bit later that decade, Peter Deutsch, another Fellow at Sun, added fallacies five, six, and seven."
Things seem to be clearer when it comes to the last fallacy — it was added by another "Sun Fellow", James "Dr. Java" Gosling, around 1997.
The 8 fallacies should serve as a warning for architects and designers of distributed systems. Believing these statements are true results in troubles and pains for the system and its creators further down the line. We should expect and prepare for the exact opposite of these statements if we want to have a dependable distributed system.

Diving into the fallacies of distributed computing
We will now take a closer look at each of these fallacies, covering the issues they can lead to, as well as what measures you can take to mitigate them.
1. The network is reliable
Before we talk about this first fallacy, let’s quickly look at what reliability means. Here at Ably, we define reliability as the degree to which a product or service conforms to its specifications when in use, even in the case of failures. Thus, you can think of reliability as the quality of uptime — that is, assurance that functionality and end-user user experience are preserved as effectively as possible.
Now, back to our fallacy. Networks are complex, dynamic, and often unpredictable. Many reasons could lead to a network failure or network-related issues: a switch or a power failure, misconfiguration, an entire datacenter becoming unavailable, DDoS attacks, etc. Due to this complexity and general unpredictability, networks are unreliable.
So how do you make your distributed system reliable, ensuring it continues to work as expected, even in the context of unreliable networks?
It’s crucial to accept and treat failure as a matter of course. You should design your system so that it’s able to mitigate failures that will inevitably occur, and continue to operate as expected in spite of adversities.
Concretely, from an infrastructure perspective, you need to engineer your system to be fault-tolerant and highly redundant. For more details about what this entails and what you need to consider, read our blog post about engineering dependability and fault tolerance in a distributed system.
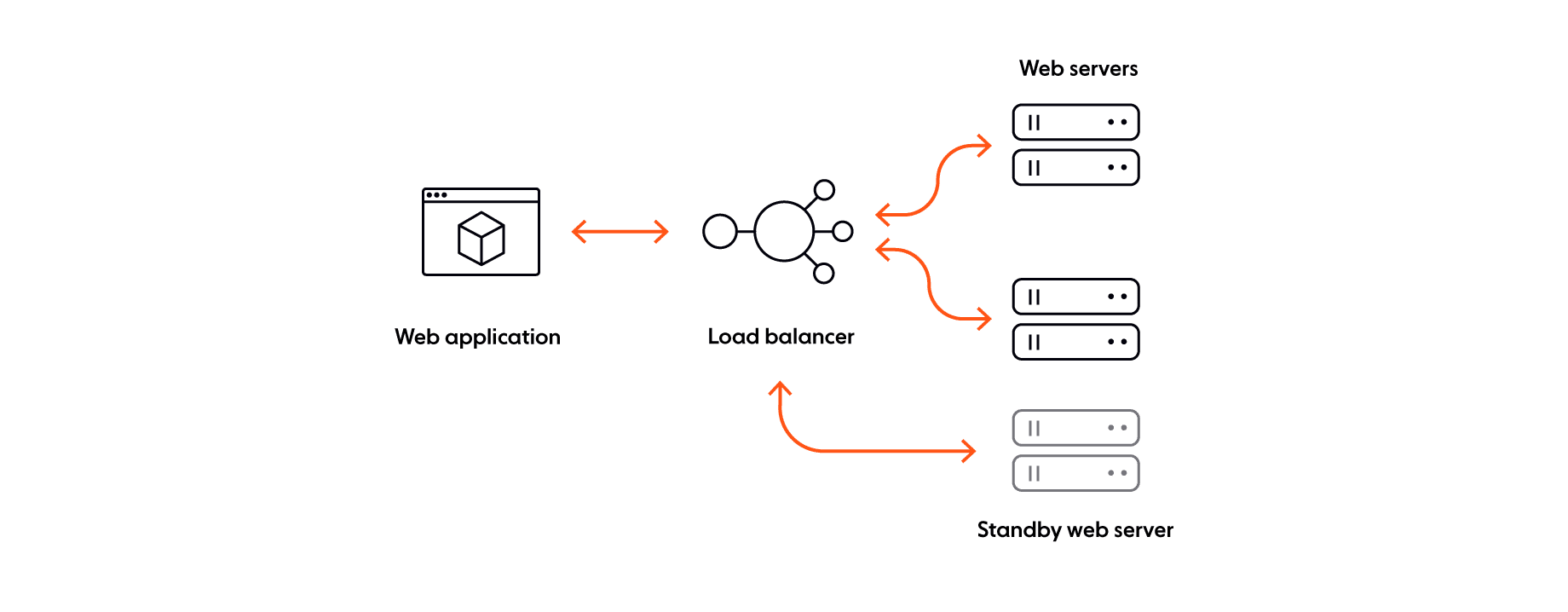
In addition to infrastructure concerns, you also need to think about connections being dropped and messages and API calls getting lost due to network failures. For some use cases (e.g., realtime chat app), data integrity is essential, and all messages have to be delivered exactly once and in order to end-users — at all times (even if failures are involved). To ensure data integrity, your system must exhibit stateful characteristics. Additionally, you need mechanisms such as automatic reconnection and retries, deduplication (or idempotency), and ways to enforce message ordering and guarantee delivery.
2. Latency is zero
Latency may be close to zero when you’re running apps in your local environment, and it’s often negligible on a local area network. However, latency quickly deteriorates in a wide area network. That’s because in a WAN data often has to travel further from one node to another, since the network may span large geographical areas (this is usually the case with large-scale distributed systems).
As you’re designing your system, you should bear in mind that latency is an inherent limitation of networks. We should never assume that there will be no delay or zero latency between data being sent and data being received.
Latency is primarily constrained by distance and the speed of light. Of course, there’s nothing we can do about the latter. Even in theoretically perfect network conditions, packets cannot exceed the speed of light. However, we can do something when it comes to distance: bring data closer to clients through edge computing. If you’re building a cloud-based system, you should choose your availability zones carefully, ensuring they are in proximity to your clients, and route traffic accordingly.
With latency in mind, here are several other things to ponder:
- Caching. Browser caching can help improve latency and decrease the number of requests sent to the server. You can also use a CDN to cache resources in multiple locations around the world. Once cached, they can be retrieved via the datacenter or point of presence closest to the client (as opposed to being served by an origin server).
- Using an event-driven protocol. Depending on the nature of your use case, you might consider using a communication protocol like WebSockets. Compared to HTTP, WebSockets have a vastly shorter round-trip time (once the connection has been established). Additionally, a WebSocket connection remains open, allowing for data to be passed back and forth between server and client as soon as it becomes available, in realtime — a significant improvement over the HTTP request-response model.
- Server performance. There’s a strong correlation between server performance (processing speed, hardware used, available RAM) and latency. To prevent a congested network and your servers from being overrun, you need the ability to (dynamically) increase the capacity of your server layer and reassign load.
3. Bandwidth is infinite
While latency is the speed at which data travels from point A to point B, bandwidth refers to how much data can be transferred from one place to another in a certain timeframe.
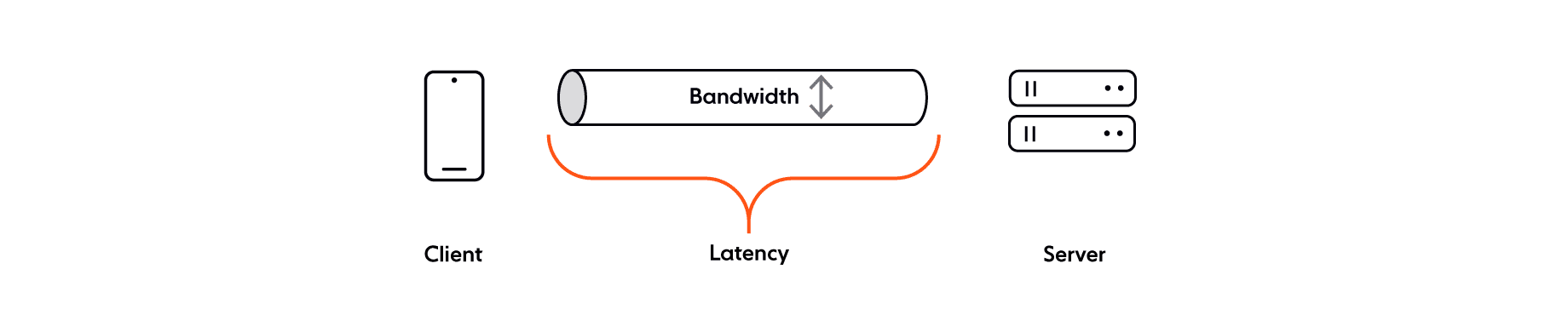
Computing technology has, without a doubt, made significant advancements since the 90s, when the 8 fallacies were coined. Network bandwidth has also improved, and we’re now able to send more data across our networks.
However, even with these improvements, the capacity of networks is not infinite (partially because our appetite for generating and consuming data has also increased). When a high volume of data is trying to flow through the network, and there is insufficient bandwidth support, various issues can arise:
- Queuing delays, bottlenecks, and network congestion.
- Packet loss leading to inferior quality of service guarantees, i.e., messages getting lost or being delivered out of order.
- Abysmal network performance and even overall system instability.
There are multiple ways to improve your network bandwidth capacity. Among them:
- Comprehensive monitoring. It’s essential to track and check usage in your network, so you can quickly identify issues (e.g., who or what is hogging your bandwidth) and take the appropriate remedial measures.
- Multiplexing. Protocols like HTTP/2, HTTP/3, and WebSockets all support multiplexing, a technique that improves bandwidth utilization by allowing you to combine data from several sources and send it over the same communication channel/medium.
- Lightweight data formats. You can preserve your network bandwidth by using data exchange formats built for speed and efficiency, like JSON. Another option is MessagePack, a compact binary serialization format that creates even smaller messages than JSON.
- Network traffic control. You need to think about using mechanisms such as throttling/rate limiting, congestion control, exponential backoff, etc.
4. The network is secure
Gene Spafford (“Spaf”), one of the world’s leading security experts, once said:
“The only truly secure system is one that is powered off, cast in a block of concrete and sealed in a lead-lined room with armed guards — and even then I have my doubts.”
There are many ways a network can be attacked or compromised: bugs, vulnerabilities in operating systems and libraries, unencrypted communication, oversights that lead to data being accessed by unauthorized parties, viruses and malware, cross-site scripting (XSS), and DDoS attacks, to name just a few (but the list is endless).
Even though true (absolute) security in the world of distributed computing is a fallacy, you should nonetheless do whatever is in your power to prevent breaches and attacks when you design, build, and test your system. The aim is for security incidents to happen as infrequently as possible and to have limited impact and ramifications.
Here are several things to consider:
- Threat modeling. It’s advisable to use a structured process to identify potential security threats and vulnerabilities, quantify the seriousness of each, and prioritize techniques to mitigate attacks.
- Defense in depth. You should use a layered approach, with different security checks at network, infrastructure, and application level.
- Security mindset. When designing your system, you should keep security in mind and follow best practices and industry recommendations and advice, such as OWASP’s Top 10 list, which covers the most common web application security risks your system should be equipped to address.
5. Topology doesn't change
In a nutshell, network topology refers to the manner in which the links and nodes of a network are arranged and relate to each other. In a distributed system, network topology changes all the time. Sometimes, it’s for accidental reasons or due to issues, such as a server crashing. Other times it’s deliberate — we add, upgrade, or remove servers.
As you design your distributed system, it’s important to not rely on the network topology being consistent and not expect it to behave in a certain way at all times. There are numerous types of network topologies you may choose to use, each with its own advantages and disadvantages.
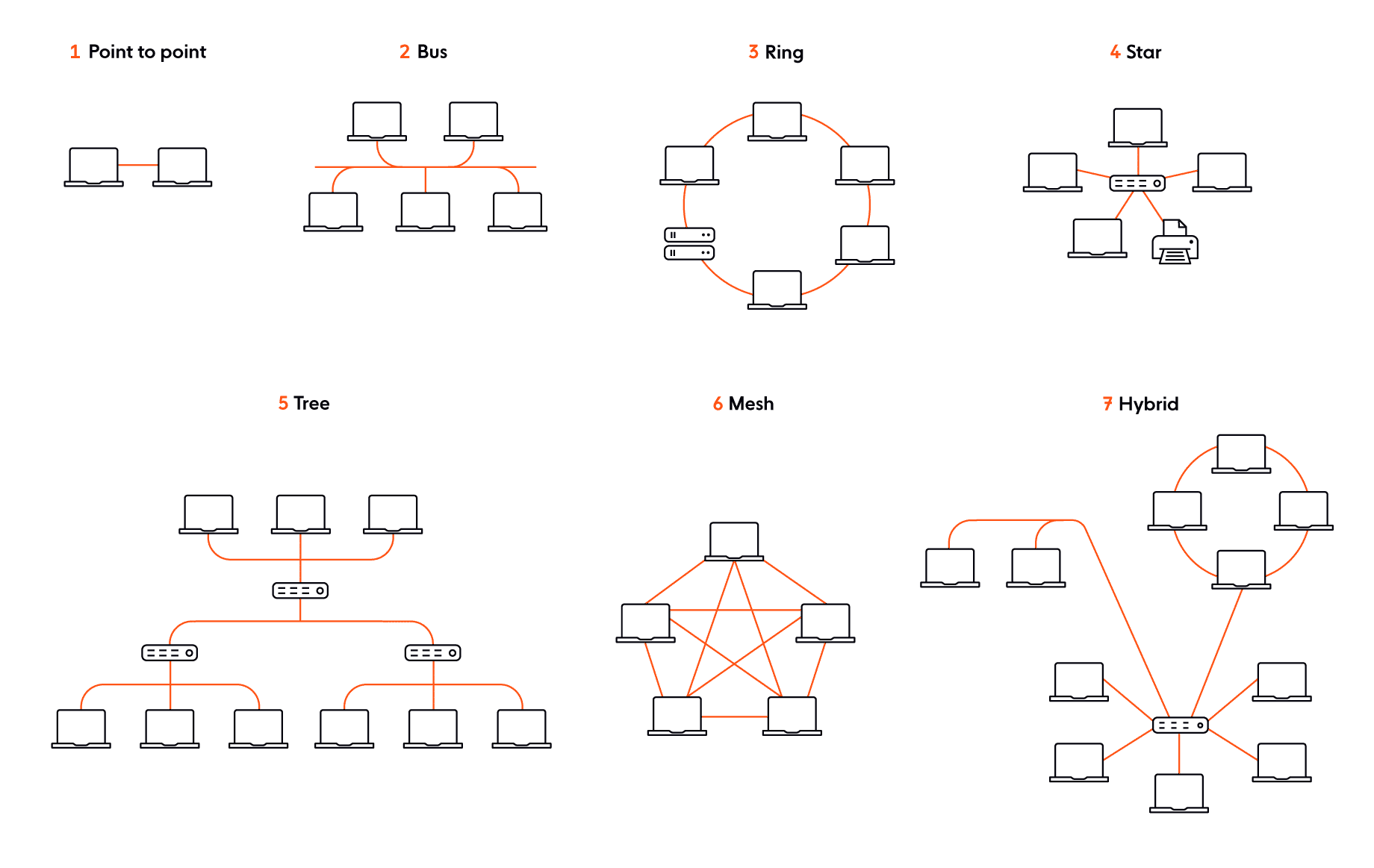
For example, in a ring topology, each node connects to precisely two other nodes. Data travels from node to node, with each of them handling every packet. Some of the advantages of using a ring topology:
- You do not require a central node to manage connectivity.
- It’s relatively easy to reconfigure.
- It can be made full-duplex (dual ring topology), allowing data to flow in both directions, clockwise and counterclockwise.
On the downside, a single ring topology is quite vulnerable to failure. If one node goes down, it can take down the entire network.
Let’s now look at another type of topology. In a mesh topology, there is no central connection point, as the nodes are interconnected. Mesh topologies use two different methods for data transmission: routing (where the nodes determine the shortest distance from source to destination), and flooding (information is sent to all nodes within the network). The advantages of mesh topologies:
- Interconnectivity of nodes makes the network durable and fault-tolerant, with no single point of failure. No single device can bring the network offline.
- New nodes can be added without interruption.
- Suitable for high-speed data transfers (when routing is used).
As for disadvantages, it’s a complex topology that requires meticulous planning, a long time to set up, and constant monitoring and maintenance due to the high number of connections needed for interconnectivity.
It’s up to you to choose the best network topology for your specific use case. Just bear in mind that your system needs the ability to quickly adjust to changes in network topology, without service availability and uptime being affected. With that in mind, you shouldn’t treat any given node as indispensable.
6. There is one administrator
There might be only one administrator in the case of a very small system, or perhaps in the context of a personal project. Beyond that, there is usually more than one administrator of a distributed system in nearly all real-life scenarios. For example, think of modern cloud-native systems that consist of many services developed and managed by different teams. Or consider that customers that use your system also need administrators on their side to manage the integration.
When you engineer your system, you should make it easy (well, as easy as possible) for different administrators to manage it. You also need to think about the system's resiliency and make sure it's not impacted by different people interacting with it. Here are a couple of things to consider:
- Decouple system components. Ensuring appropriate decoupling allows for greater resiliency in the context of either planned upgrades leading to issues, or unplanned events, such as failures. One of the most popular options facilitating decoupling (or loose coupling) is the pub/sub pattern.
- Make troubleshooting easy. It's essential to provide visibility into your system so administrators can diagnose and resolve issues that may occur. Return error messages and throw exceptions so administrators have context and can take the appropriate course of action to fix problems. In addition, logging, metrics, and tracing (often called the three pillars of observability) should be key aspects of your system's design.
7. Transport cost is zero
Just as latency isn’t zero, transporting data from one point to another has an attached cost, which is not at all negligible.
First of all, networking infrastructure has a cost. Servers, network switches, load balancers, proxies, firewalls, operating and maintaining the network, making it secure, not to mention staff to keep it running smoothly — all of these cost money. The bigger the network, the bigger the financial cost.
In addition to finances, we must also consider the time, effort, and difficulty involved in architecting a distributed system that works over a highly available, dependable, and fault-tolerant network. It’s often less risky, simpler, and more cost-effective to offload this complexity to a fully managed and battle-tested solution that’s designed specifically for this purpose.
Beyond the infrastructure side of things, there’s also a cost associated with transporting the data over the network. It takes time and CPU resources to go from the application layer to the transport layer. Information needs to be processed and serialized (marshaling) on the server-side before being transmitted to the client-side, where it needs to be deserialized. If you wish to decrease transport costs, avoid XML or XML-based options, and use lightweight serialization and deserialization formats instead, such as JSON, MessagePack, or Protocol Buffers (Protobuf).
8. The network is homogeneous
Often, not even your home network is homogenous. It’s enough to have just two devices with different configurations (e.g., laptops or mobile devices) and using different transport protocols, and your network is heterogeneous.
Most distributed systems need to integrate with multiple types of devices, adapt to various operating systems, work with different browsers, and interact with other systems. Therefore, it’s critical to focus on interoperability, thus ensuring that all these components can “talk” to each other, despite being different.

Where possible, use open, standard protocols that are widely supported instead of proprietary ones. Examples include HTTP, WebSockets, SSE, or MQTT. The same logic applies to data formats, where options like JSON or MessagePack are generally the best way to go.
A brief conclusion: building distributed systems is hard
Even though the fallacies of distributed computing were coined a few decades ago, they still hold true today. That’s because the characteristics and underlying problems of distributed systems have remained largely the same. The rise of cloud computing, automation, and DevOps makes things easier and helps minimize the impact of these fallacies — but only minimize, not remove entirely.
One might be tempted to believe that the eight fallacious statements can be ignored. It’s definitely convenient, especially when your system is working as intended, without any issues. However, just because you might not run into these fallacies daily doesn’t mean you should dismiss them. On the contrary, being aware of these limitations will help you engineer better and more reliable distributed systems.
It will be interesting to see how technology evolves, and if in 10, 20, or 30 years from now, the fallacies of distributed computing will still be relevant. Right now, though, they are. And that makes building dependable distributed systems a tough engineering challenge. The biggest fallacy would be to think otherwise.
Ably and the fallacies of distributed computing
The fallacies of distributed computing are very well known to us at Ably. We solve hard engineering problems every day, and our distributed realtime communication platform is architected with dependability in mind, to counteract the effects and minimize the issues deriving from these fallacies.
Ably is powered by a globally distributed edge network built for massive scale and designed to ensure predictably low latencies (<65 ms global average). Our system has sufficient redundancy at regional and global levels to guarantee continuity of service even in the face of multiple infrastructure failures. Our fault-tolerant design enables us to provide legitimate 99.999% uptime SLAs.
If you are running into problems trying to massively, dependably, securely scale your distributed realtime communication system, get in touch or sign up for a free account and see what Ably can do for you.
Further reading
- Channel global decoupling for region discovery ?
- Reviewing the Eight Fallacies of Distributed Computing
- Understanding the 8 fallacies of Distributed Systems
- Engineering dependability and fault tolerance in a distributed system
- Achieving exactly-once delivery with Ably
- Ably’s Four Pillars of Dependability